一.前言
首先要学习一下ogg的所有进程,看着这张图来学习
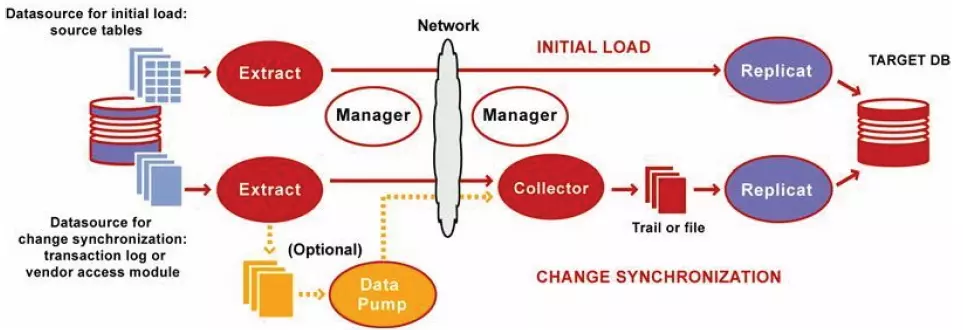
- Manager进程是GoldenGate的控制进程,运行在源端和目标端上。它主要作用有以下几个方面:启动、监控、重启Goldengate的其他进程,报告错误及事件,分配数据存储空间,发布阀值报告等。在目标端和源端有且只有一个manager进程
- Extract运行在数据库源端,负责从源端数据表或者日志中捕获数据。Extract的作用可以按照阶段来划分为:
-
- 初始时间装载阶段:在初始数据装载阶段,Extract进程直接从源端的数据表中抽取数据
-
- 同步变化捕获阶段:初始数据同步完成以后,Extract进程负责捕获源端数据的变化(DML和DDL)
- Data Pump进程运行在数据库源端,其作用是将源端产生的本地trail文件,把trail以数据块的形式通过TCP/IP 协议发送到目标端,这通常也是推荐的方式。pump进程本质是extract进程的一种特殊形式,如果不使用trail文件,那么extract进程在抽 取完数据以后,直接投递到目标端,生成远程trail文件。
- Collector进程与Data Pump进程对应 的叫Server Collector进程,这个进程不需要引起我的关注,因为在实际操作过程中,无需我们对其进行任何配置,所以对我们来说它是透明的。它运行在目标端,其 任务就是把Extract/Pump投递过来的数据重新组装成远程ttrail文件。
- Replicat进程,通常我们也把它叫做应用进程。运行在目标端,是数据传递的最后一站,负责读取目标端trail文件中的内容,并将其解析为DML或 DDL语句,然后应用到目标数据库中。
关于OGG的Trail文件:
- 为了更有效、更安全的把数据库事务信息从源端投递到目标端。GoldenGate引进trail文件的概念。前面提到extract抽取完数据以 后 Goldengate会将抽取的事务信息转化为一种GoldenGate专有格式的文件。然后pump负责把源端的trail文件投递到目标端,所以源、 目标两端都会存在这种文件。
- trail文件存在的目的旨在防止单点故障,将事务信息持久化,并且使用checkpoint机制来记录其读写位置,如果故障发生,则数据可以根据checkpoint记录的位置来重传 。
二.源端配置
2.1 版本选择
因为源端是抽取mysql db,所以要选择正确的ogg版本,这里选择的是:

2.2 解压安装
我安装的目录是/opt/ogg目录,所以就解压在这个目录
tar xf ggs_Linux_x64_MySQL_64bit.tar -C /opt/ogg
然后执行ogg命令
./ggsci
最初进入后需要初始化,执行命令
GGSCI (miaojiaxing-VirtualBox) 1> create subdirs Creating subdirectories under current directory /opt/ogg Parameter file /opt/ogg/dirprm: created. extract extkafka Report file /opt/ogg/dirrpt: created. Checkpoint file /opt/ogg/dirchk: created. Process status files /opt/ogg/dirpcs: created. SQL script files /opt/ogg/dirsql: created. Database definitions files /opt/ogg/dirdef: created. Extract data files /opt/ogg/dirdat: created. Temporary files /opt/ogg/dirtmp: created. Credential store files /opt/ogg/dircrd: created. Masterkey wallet files /opt/ogg/dirwlt: created. Dump files /opt/ogg/dirdmp: created.
2.3 配置管理进程
GGSCI (miaojiaxing-VirtualBox) 2> edit param mgr port 7809 dynamicportlist 7840-7939 autorestart er *, retries 5, waitminutes 3 purgeoldextracts /home/goldengate/dirdat/*,usecheckpoints, minkeepdays 2
- port mgr:进程的默认监听端口
- dynamicportlist:动态端口列表,指定mgr端口不可用的时候从这个列表中选择一个,最大范围256个
- AUTORESTART:重启参数设置表示重启所有EXTRACT进程,最多5次,每次间隔3分钟
- PURGEOLDEXTRACTS即TRAIL文件的定期清理
start mgr可以启动该进程,info mgr可查看该进程状态。之后配置的进程都可以用这个命令,名字换一下即可。
GGSCI (miaojiaxing-VirtualBox) 3> start mgr Manager started. GGSCI (miaojiaxing-VirtualBox) 30> info mgr Manager is running (IP port miaojiaxing-VirtualBox.7809, Process ID 13044).
2.4 配置抽取进程
GGSCI (miaojiaxing-VirtualBox) 2> edit param extkafka extract extkafka sourcedb alcmydata@172.29.30.6:3306 userid ogg password ogg exttrail /opt/ogg/dirdat/me TranLogOptions AltLogDest /var/log/mysql/mysql-bin.index table alcmydata.alc_asset_equity;
添加extract进程
GGSCI (miaojiaxing-VirtualBox) 10> add extract extkafka,tranlog,begin now EXTRACT added.
添加trail文件与extract进程绑定
GGSCI (miaojiaxing-VirtualBox) 11> add exttrail /opt/ogg/dirdat/me,extract extkafka EXTTRAIL added.
这里需要注意的mysql的my.cnf log-bin配置,因为对接mysql的时候,需要依赖mysql的binlog日志
2.5 配置传递进程
GGSCI (miaojiaxing-VirtualBox) 2> edit param mcp1 extract mcp1 passthru sourcedb alcmydata@172.29.30.6:3306 userid ogg password ogg rmthost 172.29.30.79,mgrport 7809,compress rmttrail /opt/ogg/dirdat/mp dynamicresolution numfiles 3000 table alcmydata.alc_asset_equity;
- passthru:使用pump逻辑传输
- rmthost:目标端ogg的mgr服务地址
- rmttrail:目标端trail文件存储位置以及名称
分别添加本地trail文件和目标端trail文件绑定到mcp1进程
GGSCI (miaojiaxing-VirtualBox) 2> add extract mcp1,exttrailsource /opt/ogg/dirdat/me EXTRACT added. GGSCI (miaojiaxing-VirtualBox) 3> add rmttrail /opt/ogg/dirdat/mp,extract mcp1 RMTTRAIL added.
2.6 创建表的定义文件
ogg对接mysql和oracle不同的地方是ogg获取mysql表结构的方法,需要配置defgen文件
GGSCI (miaojiaxing-VirtualBox) 2> edit param defgen defsfile ./dirdef/gmqdsjsjp.def sourcedb alcmydata@172.29.30.6:3306 userid ogg password ogg table alcmydata.alc_asset_equity;
然后生成表定义文件传给目标库目录
./defgen paramfile ./dirprm/defgen.prm scp /opt/ogg/dirdef/gmqdsjsjp.def miaojiaxing2@172.29.30.79:/opt/ogg/dirdef/
三.目标端配置
3.1 配置管理进程
和源端配置是一样的
GGSCI (miaojiaxing-VirtualBox) 2> edit param mgr port 7809 dynamicportlist 7840-7939 autorestart er *, retries 5, waitminutes 3 purgeoldextracts /home/goldengate/dirdat/*,usecheckpoints, minkeepdays 2
3.2 配置replicate进程
GGSCI (miaojiaxing-VirtualBox) 2> edit param rekafka REPLICAT rekafka sourcedefs /opt/ogg/dirdef/gmqdsjsjp.def TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props REPORTCOUNT EVERY 1 MINUTES, RATE GROUPTRANSOPS 10000 MAP alcmydata.alc_asset_equity, TARGET alcmydata.alc_asset_equity;
- TARGETDB LIBFILE:定义kafka的一些配置文件
- REPORTCOUNT:复制任务的报告生成频率
- GROUPTRANSOPS:以事务传输
- MAP 源端和目标端的映射关系
添加进程
add replicat rekafka exttrail /opt/ogg/dirdat/mp,checkpointtable test_ogg.checkpoint
3.3 配置kafka.props
gg.handlerlist=kafkahandler gg.handler.kafkahandler.type=kafka gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties gg.handler.kafkahandler.topicMappingTemplate=test_ogg gg.handler.kafkahandler.format=json gg.handler.kafkahandler.mode=op gg.classpath=/ggwork/kafka/2.2.1/libexec/libs/*
custom_kafka_producer.properties文件如下
bootstrap.servers=172.29.31.214:9092 acks=1 compression.type=gzip reconnect.backoff.ms=1000 value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer batch.size=102400 linger.ms=10000
3.4 发车
进程启动顺序为:源mgr——目标mgr——源extract——源pump——目标replicate来完成。
源端:
start mgr
start extkafka
start mcp1
目标端:
start mgr
start rekafka
然后update一条数据,你可以用最简单的term来查看结果(当然可以用个java的demo):
kafka-console-producer --broker-list localhost:9092 --topic test_ogg
结果:
{"table":"alcmydata.alc_asset_equity","op_type":"I","op_ts":"2019-08-08 15:12:56.973193","current_ts":"2019-08-08T17:39:28.281000","pos":"00000000000000488603","after":{"ID":1437,"CREATED_AT":"2019-08-07 17:19:04.000000","CREATED_BY":"c3lz","UPDATED_AT":"2019-08-07 17:19:04.000000","UPDATED_BY":"c3lz","HOLD_SHARE":66300.0000000000,"HOLD_AMOUNT":0,"FROZEN_SHARE":0,"FROZEN_AMOUNT":0,"ENTRUST_AMOUNT":0,"TRANSIT_AMOUNT":0,"INVEST_AMOUNT":66300.00,"ACHIEVED_AMOUNT":0,"PRODUCT_ID":114388613151072,"PROD_CATEGORY":"RDAx","USER_ID":2869248,"ACCOUNT_ID":492,"DAILY_INCOME":null,"INCOME_DATE":null,"TOTAL_INCOME":null,"VERSION":1,"REMARK":"MQ==","UNPAID_INCOME":0,"ADVANCE_ACHIEVED_AMOUNT":null}}
{"table":"alcmydata.alc_asset_equity","op_type":"U","op_ts":"2019-08-08 18:11:50.968788","current_ts":"2019-08-08T18:11:57.664000","pos":"00000000010000003443","before":{},"after":{"ID":1,"HOLD_SHARE":20000.0000000000}}
参考
https://blog.csdn.net/TXBSW/article/details/87915942
http://www.voidcn.com/article/p-cadcicbv-bm.html
https://dongkelun.com/2018/05/23/oggOracle2Kafka/
https://docs.oracle.com/goldengate/bd123010/gg-bd/index.html