.Net Framework中处理字符和字符串的主要有以下这么几个类:
(1)、System.Char类 一基础字符串处理类
(2)、System.String类 一处理不可变的字符串(一经创建,字符串便不能以任何方式修改)
(3)、System.Text.StringBuilder类 一更高效地构建字符串
(4)、System.Secureity.SecureString类 一对字符串进行保护操作,它可以保护密码和信用卡资料等敏感字符串.
一、Char类型

Char是值类型,这点和String类型不同,因为String类型派生自object.
1、简介
在.Net Framework中,字符总是表示成16位Unicode代码值,这简化了国际化应用程序的开发.每个字符都是System.Char结构(一个值类型)的实例.
(1)、常量属性
Char提供了两个公开的只读常量字段,MinValue和MaxValue,分别为'�'和'uffff'.分别为最小和最大的字符值.
2、判断字符的类型
(1)、通过GetUnicodeCategory()静态方法来判断当前字符的类型.该方法返回一个System.Globalization.UnicodeCategory枚举类型的一个值,这个值是由Unicode标准定义的控制字符、货币符号、小写字符、大写字母、标点符号、数学字符还是其他符号,具体类型如下:
// // 摘要: // 定义字符的 Unicode 类别。 [ComVisible(true)] public enum UnicodeCategory { // // 摘要: // 大写字母。 由 Unicode 代码“Lu”(字母,大写)表示。 值为 0。 UppercaseLetter = 0, // // 摘要: // 小写字母。 由 Unicode 代码“Ll”(字母,小写)表示。 值为 1。 LowercaseLetter = 1, // // 摘要: // 词首字母大写的字母。 由 Unicode 代码“Lt”(字母,词首字母大写)表示。 值为 2。 TitlecaseLetter = 2, // // 摘要: // 修饰符字母字符,它是独立式的间距字符,指示前面字母的修改。 由 Unicode 代码“Lm”(字母,修饰符)表示。 值为 3。 ModifierLetter = 3, // // 摘要: // 不属于大写字母、小写字母、词首字母大写或修饰符字母的字母。 由 Unicode 代码“Lo”(字母,其他)表示。 值为 4。 OtherLetter = 4, // // 摘要: // 指示基字符的修改的不占位字符。 由 Unicode 代码“Mn”(符号,不占位)表示。 值为 5。 NonSpacingMark = 5, // // 摘要: // 间隔字符,它指示基字符的修改并影响基字符的标志符号的宽度。 由 Unicode 代码“Mc”(符号,间隔组合)表示。 值为 6。 SpacingCombiningMark = 6, // // 摘要: // 封闭符号字符,它是将基字符前面的所有字符(包括基字符)括起来的不占位字符。 由 Unicode 代码“Me”(符号,封闭)表示。 值为 7。 EnclosingMark = 7, // // 摘要: // 十进制数字字符,即范围 0 到 9 内的字符。 由 Unicode 代码“Nd”(数字,十进制数字)表示。 值为 8。 DecimalDigitNumber = 8, // // 摘要: // 由字母表示的数字,而不是十进制数字,例如,罗马数字 5 由字母“V”表示。 此指示符由 Unicode 代码“Nl”(数字,字母)表示。 值为 9。 LetterNumber = 9, // // 摘要: // 既不是十进制数字也不是字母数字的数字,例如分数 1/2。 此指示符由 Unicode 代码“No”(数字,其他)表示。 值为 10。 OtherNumber = 10, // // 摘要: // 没有标志符号但不属于控制或格式字符的空格字符。 由 Unicode 代码“Zs”(分隔符,空格)表示。 值为 11。 SpaceSeparator = 11, // // 摘要: // 用于分隔文本各行的字符。 由 Unicode 代码“Zl”(分隔符,行)表示。 值为 12。 LineSeparator = 12, // // 摘要: // 用于分隔段落的字符。 由 Unicode 代码“Zp”(分隔符,段落)表示。 值为 13。 ParagraphSeparator = 13, // // 摘要: // 控制代码字符,其 Unicode 值为 U+007F,或者属于 U+0000 到 U+001F 或 U+0080 到 U+009F 的范围内。 由 Unicode // 代码“Cc”(其他,控制)表示。 值为 14。 Control = 14, // // 摘要: // 格式字符,它影响文本的布局或文本处理操作,但通常不呈现。 由 Unicode 代码“Cf”(其他,格式)表示。 值为 15。 Format = 15, // // 摘要: // 高代理项或低代理项字符。 代理项代码值在 U+D800 到 U+DFFF 的范围内。 由 Unicode 代码“Cs”(其他,代理项)表示。 值为 16。 Surrogate = 16, // // 摘要: // 专用字符,其 Unicode 值在在 U+E000 到 U+F8FF 的范围内。 由 Unicode 代码“Co”(其他,专用)表示。 值是 17。 PrivateUse = 17, // // 摘要: // 连接两个字符的连接符标点字符。 由 Unicode 代码“Pc”(标点,连接符)表示。 值为 18。 ConnectorPunctuation = 18, // // 摘要: // 短划线或连字符字符。 由 Unicode 代码“Pd”(标点,短划线)表示。 值为 19。 DashPunctuation = 19, // // 摘要: // 成对的标点符号(例如括号、方括号和大括号)的开始字符。 由 Unicode 代码“Ps”(标点,开始)表示。 值为 20。 OpenPunctuation = 20, // // 摘要: // 成对的标点符号(例如括号、方括号和大括号)的结束字符。 由 Unicode 代码“Pe”(标点,结束)表示。 值为 21。 ClosePunctuation = 21, // // 摘要: // 左引号或前引号字符。 由 Unicode 代码“Pi”(标点,前引号)表示。 值为 22。 InitialQuotePunctuation = 22, // // 摘要: // 右引号或后引号字符。 由 Unicode 代码“Pf”(标点,后引号)表示。 值为 23。 FinalQuotePunctuation = 23, // // 摘要: // 不属于连接符、短划线、开始标点、结束标点、前引号或后引号的标点字符。 由 Unicode 代码“Po”(标点,其他)表示。 值为 24。 OtherPunctuation = 24, // // 摘要: // 数学符号字符,如“+”或“=”。 由 Unicode 代码“Sm”(符号,数学)表示。 值为 25。 MathSymbol = 25, // // 摘要: // 货币符号字符。 由 Unicode 代码“Sc”(符号,货币)表示。 值为 26。 CurrencySymbol = 26, // // 摘要: // 修饰符符号字符,它指示环绕字符的修改。 例如,分数斜线号指示其左侧的数字为分子,右侧的数字为分母。 此指示符由 Unicode 代码“Sk”(符号,修饰符)表示。 // 值为 27。 ModifierSymbol = 27, // // 摘要: // 不属于数学符号、货币符号或修饰符符号的符号字符。 由 Unicode 代码“So”(符号,其他)表示。 值为 28。 OtherSymbol = 28, // // 摘要: // 未分配给任何 Unicode 类别的字符。 由 Unicode 代码“Cn”(其他,未分配)表示。 值为 29。 OtherNotAssigned = 29 }
该方法有两种传参方式,如下:
// // 摘要: // 将指定字符串中位于指定位置的字符分类到由一个 System.Globalization.UnicodeCategory 值标识的组中。 // // 参数: // s: // System.String。 // // index: // s 中的字符位置。 // // 返回结果: // 一个 System.Globalization.UnicodeCategory 枚举常数,标识包含 index 中位于 s 处的字符的组。 // // 异常: // T:System.ArgumentNullException: // s 为 null。 // // T:System.ArgumentOutOfRangeException: // index 小于零或大于 s 中最后一个位置。 public static UnicodeCategory GetUnicodeCategory(string s, int index); // // 摘要: // 将指定的 Unicode 字符分类到由一个 System.Globalization.UnicodeCategory 值标识的组中。 // // 参数: // c: // 要分类的 Unicode 字符。 // // 返回结果: // 一个 System.Globalization.UnicodeCategory 值,它标识包含 c 的组。 public static UnicodeCategory GetUnicodeCategory(Char c);
测试代码如下:
判断目标字符是否是空格符
var chatType=Char.GetUnicodeCategory(' '); //判断' '是否是一个空格符 var isEqual = chatType.Equals(UnicodeCategory.SpaceSeparator); Console.WriteLine(isEqual);
输出:True
判断目标字符是否是大写字母
var chatType=Char.GetUnicodeCategory('S'); //判断'S'是否是一个大写字母 var isEqual = chatType.Equals(UnicodeCategory.UppercaseLetter); Console.WriteLine(isEqual);
输出:True
(3)、为了简化开发,Char类型还提供了几个静态方法,如下:
IsDigit()、IsLetter()、IsUpper()、IsLower()、IsPunctuaion()等方法.大多数都在内部调用了GetUnicodeCategory方法,并返回true和false;
3、字符转大小写
(1)、忽略语言文化的字符大小写转换
通过Char的ToUpperInvariant和ToLowerInvariant静态方法可完成忽略语言文化的字符的大小写转换,代码如下:
var lower = Char.ToLowerInvariant('S'); var upper = Char.ToUpperInvariant('s'); Console.WriteLine("s的小写形式:{0},s的大写形式:{1}",lower,upper);

(2)、不忽略语言文化的字符大小写转换
通过Char的ToLower和ToUpper方法来转换大小写,但转换时调用线程关联的语言文化信息(方法在内部查询)System.Threading.Thread类的静态属性CurrentCultrue属性来获取,代码如下:
var lower = Char.ToLower('s', Thread.CurrentThread.CurrentCulture); var upper = Char.ToUpper('S', Thread.CurrentThread.CurrentCulture); Console.WriteLine("s的小写形式:{0},s的大写形式:{1}",lower,upper);
ToUpper和ToLower之所以需要文化信息,是因为字母的大小写转化是一种依赖于语言文化的操作.
每种语言转换字母的方式不同.
3、判断字符是否相等
(1)、通过Char的实例Equals方法来判断
Console.WriteLine("字符{0}和字符{1}相等?答案:{2}", 's', 's', 's'.Equals('s'));

(2)、判断两个字符的大小
通过Char的实例CompareTo方法(该方法由IComparable和IComparable<Char>接口来定义)来判断,结果返回两个Char实例的忽略语言文化的比较结果.
Console.WriteLine("字符{0}和字符{1}相差的位置?答案:{2}", 's', 's', 'b'.CompareTo('a')); Console.WriteLine("字符{0}和字符{1}相差的位置?答案:{2}", 's', 's', 'a'.CompareTo('b'));

4、ConvertToUtf32方法和ConvertFromUtf32方法
自行百度
5、返回字符的数值形式
通过GetNumericValue()将字符转换成数字,这个方法将返回字符的数字形式.代码如下:
Console.WriteLine(Char.GetNumericValue('u0039'));//9的二进制代码 Console.WriteLine(Char.GetNumericValue('9')); Console.WriteLine(Char.GetNumericValue('a'));

如果目标字符串不是数字返回-1;
6、字符转换数值其他的方法
(1)、强制类型转换
将Char转换成数值例如int32最简单的方法就是转型.这是三种方法中效率最高的,因为编译器会生成中间语言(IL)指令来执行转换,而且不必调用方法.且C#允许指定转换时使用checked还是unchecked代码,C# checked和unchecked详解
(2)、使用Convert类型
System.Convert类型提供的几个静态方法来实现Char和数值类型的相互转换,所有的这些转换都以checked方式执行,发现转换造成数据丢失就抛出OverflowException异常.
(3)、使用IConvertible接口
Char类型和FCL中的所有数值类型都实现了IConvertible接口.该接口定义了像ToUint32和ToChar这样的方法,这种技术效率最差,因为在值类型上调用接口方法要求对实例进行装箱一Char和所有数值类型都是值类型.如果某个类型不能转换(比如Char转换成Boolean),或者转换造成数据丢失,IConvertible的方法会抛出System.InvalidCastException异常.注意,许多类型(包括FCL的Char和数值类型)都将IConvertible的方法实现为显式成员接口,这意味着为了调用接口的任何方法,都必须先将实例显式转型为一个IConvertible.IConvertible的所有方法(GetTypeCode除外)都接受对实现了IFormatProvider接口的一个对象的引用.如果转换时需要考虑语言文化信息,该参数就很有用.但大多数时候可以忽略语言文化,为这个参数传递null值.
(4)、示例代码
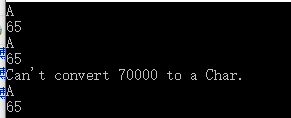
var c = (char)65; Console.WriteLine(c); var n = (int)c; Console.WriteLine(n); c = unchecked((char)(65536+65)); Console.WriteLine(c); n = Convert.ToInt32(c); Console.WriteLine(n); //Convert的范围检查 try { c = Convert.ToChar(70000);//对于16位来说过大 Console.WriteLine(c); //不执行,上面的异常被catch } catch (OverflowException) { Console.WriteLine("Can't convert 70000 to a Char."); } c = ((IConvertible)65).ToChar(null); //可以传递一个IFormatProvider参数,但是大多数情况下不需要,应为大多数情况下可以忽略语言文化 Console.WriteLine(c); n = ((IConvertible)c).ToInt32(null); Console.WriteLine(n); Console.ReadKey();