因为ik目前最高支持es 8.2.3,所以本文基于8.2.3的环境编写.
1、集群环境构建
参考Es 集群搭建及相关配置和相关参数解读,分别下载Es和kibana 8.2.3版本,部署到相应的服务器,删除es原有的data目录.配置elasticsearch.yml,节点配置如下:
节点配置
cluster.name: test_cluster node.name: node-1 network.host: 0.0.0.0 http.port: 9200 transport.port: 9300 http.cors.enabled: true http.cors.allow-origin: "*" discovery.seed_hosts: ["127.0.0.1:9300", "172.18.100.231:9300","172.18.100.224:9300"] cluster.initial_master_nodes: ["node-1", "node-2","node-3"] xpack.security.enabled: false
注意事项:节点名称、杀毒软件、防火墙等等,否则集群构建会失败
接着运行各自节点的elasticsearch.bat文件.
环境构建到此结束.
2、ik分词器安装部署 下载地址
注意es和ik分词器的版本匹配.这里下载8.2.3的ik分词器
下载完毕之后去es的工作目录的plugins文件夹下新建ik文件夹,将下载下来的ik压缩包解压缩至ik文件夹下,重启es,集群中所有节点重复此操作.
3、ik 分词器简介
3.1 词库介绍
ik分词器主要有以下词库,位于config目录下
(1)、main.dic 主词库,包含日常生活中常用的词
(2)、stopword.dic 英文停用词,当出现该词库中的文本内容时,将不会建立倒排索引
(3)、quantifier.dic 计量单位等
(4)、suffix.dic 后缀名、行政单位等
(5)、surname.dic 百家姓等
(6)、preposition.dic 语气词等
3.2 配置介绍
IKAnalyzer.cfg.xml ik配置文件位于config目录下
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
主要用于扩展配置.
3.3 使用方式
ik分词器主要分为ik_smart 、ik_max_word 下面分别测试,使用kibna dev tools.
ik_smart
GET test_index/_analyze { "tokenizer": "ik_smart", "text": ["中华人民共和国"] }
分词结果如下:
{ "tokens" : [ { "token" : "中华人民共和国", "start_offset" : 0, "end_offset" : 7, "type" : "CN_WORD", "position" : 0 } ] }
ik_max_word
GET test_index/_analyze { "tokenizer": "ik_max_word", "text": ["中华人民共和国"] }
分词结果如下:
{ "tokens" : [ { "token" : "中华人民共和国", "start_offset" : 0, "end_offset" : 7, "type" : "CN_WORD", "position" : 0 }, { "token" : "中华人民", "start_offset" : 0, "end_offset" : 4, "type" : "CN_WORD", "position" : 1 }, { "token" : "中华", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 2 }, { "token" : "华人", "start_offset" : 1, "end_offset" : 3, "type" : "CN_WORD", "position" : 3 }, { "token" : "人民共和国", "start_offset" : 2, "end_offset" : 7, "type" : "CN_WORD", "position" : 4 }, { "token" : "人民", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 5 }, { "token" : "共和国", "start_offset" : 4, "end_offset" : 7, "type" : "CN_WORD", "position" : 6 }, { "token" : "共和", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 7 }, { "token" : "国", "start_offset" : 6, "end_offset" : 7, "type" : "CN_CHAR", "position" : 8 } ] }
根据分词结果,很明显ik_max_word分的粒度更加的细和全面,所以一般都是用ik_max_word作为分词器.
3.4 扩展分词
一般情况下,词库是够用的,但是如果碰到一些特殊词汇如网络用词,这个时候就需要手动添加相关的词汇进入到词库中.ik添加自定义词库的步骤如下
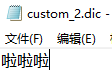
(1)、在config目录下,新增自定义词库文件

内容其中一个文件如下:
(2)、修改配置文件如下:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">custom_1.dic;custom_2.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
(3)、集群中所有的节点重复此操作
(4)、重启所有节点
(5)、测试
dev tools执行以下语句
GET test_index/_analyze { "tokenizer": "ik_max_word", "text": ["啊啦搜"] }
结果如下:
{ "tokens" : [ { "token" : "啊啦搜", "start_offset" : 0, "end_offset" : 3, "type" : "CN_WORD", "position" : 0 } ] }
啊啦搜被作为一个词进行了分词,说明自定义词库生效了.
4、ik 分词器字库远程热更新
这里用dotnet举例,版本net6,远程词库的要求请参考官方文档
net6 api接口如下:
[HttpGet("extdics")] [HttpHead("extdics")] public async Task GetExtDicsAsync(string type) { var filePath = type == "stop" ? Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "TokenizerExtFiles", "remote_ext_stopwords.txt") : Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "TokenizerExtFiles", "remote_ext_dict.txt"); using (var fileStream =System.IO.File.Open(filePath, FileMode.Open)) { byte[] result = new byte[fileStream.Length]; await fileStream.ReadAsync(result, 0, (int)fileStream.Length, _httpContextAccessor.HttpContext.RequestAborted); var contentWithNoBom= Encoding.UTF8.GetString(result).WithNobom(); if (_httpContextAccessor.HttpContext != null) { _httpContextAccessor.HttpContext.Response.Headers["Last-Modified"] = result.Length.ToString(); _httpContextAccessor.HttpContext.Response.Headers["ETag"] = result.Length.ToString(); _httpContextAccessor.HttpContext.Response.ContentType = "text/plain;charset=utf-8"; await _httpContextAccessor.HttpContext.Response.Body.WriteAsync(Encoding.UTF8.GetBytes(contentWithNoBom), _httpContextAccessor.HttpContext.RequestAborted); } } }
将api所在站点发布至服务器,接着修改ik配置文件IKAnalyzer.cfg.xml,集群中所有节点重复此操作
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <entry key="remote_ext_dict">http://172.18.100.231:12342/ik/extdics?type=dict</entry> <!--用户可以在这里配置远程扩展停止词字典--> <entry key="remote_ext_stopwords">http://172.18.100.231:12342/ik/extdics?type=stop</entry> </properties>
上述操作完成后,执行以下代码:
GET test_index/_analyze { "tokenizer": "ik_max_word", "text":"你好 张三 阿拉索" }
分词结果如下:
{ "tokens" : [ { "token" : "你好", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "张三", "start_offset" : 3, "end_offset" : 5, "type" : "CN_WORD", "position" : 1 }, { "token" : "三", "start_offset" : 4, "end_offset" : 5, "type" : "TYPE_CNUM", "position" : 2 }, { "token" : "阿拉", "start_offset" : 6, "end_offset" : 8, "type" : "CN_WORD", "position" : 3 }, { "token" : "索", "start_offset" : 8, "end_offset" : 9, "type" : "CN_CHAR", "position" : 4 } ] }
阿拉索被拆分成了两个词,你好 张三也被分成两个词,接着修改远程词库.强制将阿拉索分成一个词,同时禁用你好和张三两个词
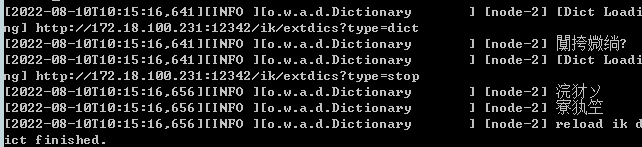
es控制台显示词库加载完毕,看下效果.分词结果如下:
{ "tokens" : [ { "token" : "三", "start_offset" : 4, "end_offset" : 5, "type" : "TYPE_CNUM", "position" : 0 }, { "token" : "阿拉索", "start_offset" : 6, "end_offset" : 9, "type" : "CN_WORD", "position" : 1 }, { "token" : "阿拉", "start_offset" : 6, "end_offset" : 8, "type" : "CN_WORD", "position" : 2 }, { "token" : "索", "start_offset" : 8, "end_offset" : 9, "type" : "CN_CHAR", "position" : 3 } ] }
内容正确,说明远程词库生效.
其余内容参考官方文档