1、数据库索引之B Tree 百度百科
对于一棵m阶B-tree,每个结点至多可以拥有m个子结点。各结点的关键字和可以拥有的子结点数都有限制,规定m阶B-tree中,根结点至少有2个子结点,除非根结点为叶子节点,
关系型数据库如mysql中数据页有大小限制,在阶数(父节点的横向子节点树数)一定的情况下,B-tree会通过增加树的深度来存储数据.此时会增加系统的IO压力.B-tree会将data数据存储到节点中,所以当索引大字段时,树的深度必然增大.
2、数据库索引之B+ Tree百度百科
B+树在节点访问时间远远超过节点内部访问时间的时候,比可作为替代的实现有着实在的优势。这通常在多数节点在次级存储比如硬盘中的时候出现。通过最大化在每个内部节点内的子节点的数目减少树的高度,平衡操作不经常发生,而且效率增加了。这种价值得以确立通常需要每个节点在次级存储中占据完整的磁盘块或近似的大小。
相较于B Tree的优点如下:
(1)、data数据存放到叶子节点
(2)、最大化在每个内部节点内的子节点的数目减少树的高度
(3)、减少平衡操作
3、数据库索引之聚集索引
(1)、一般来说,聚集索引是基于主键创建的索引,除主键索引以外的索引称为非聚集索引
(2)、聚集索引按照每张表的主键来构建B+树,叶子节点存储每一行的数据,所以聚集所以并不是一种特定的索引类型而是一种数据的存储方式
(3)、如InnerDb,每个表必须有一个主键,如果没有设置主键,InnerDb会默认选择或者添加一个隐藏列来作为主键
(4)、一般选择自增Id来作为主键,使用GUID等会导致随机IO,因为顺序插入不需要做父子节点的链接和平衡。
(5)、如InnerDb,只能有一个聚集索引,多个索引会导致数据存在多个副本,导致资源浪费.
(6)、非聚集索引会存储主键id,查询非聚集索引时,会通过主键id来查询行数据,这个过程称之为回表.
4、数据库索引之非聚集索引
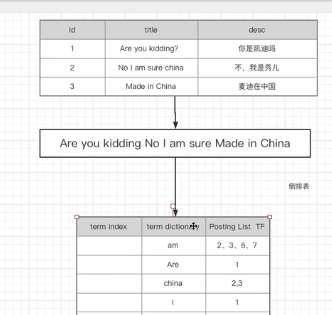
来自网络的图,图的最上方就是ES中的document(可以理解为数据库中的行数据),最下方的表格分为三部分:
i、term index -词项索引 存储的是词项的前缀,用于快速定位词项字典中的词项
ii、Posting List-倒排表 存储的是词项在文档中出现的位置
iii、term dictionary-词项字典 存储的是分词过后的一个个词项,是一个字典
(3)、倒排表压缩相关
倒排表中会存在一种场景,单个词项关联了海量的文档id,假设"张三"这个词关联了100w条文档记录,那么这里差不多要占用4*100*10000/1024/1024≈3.8M,这里仅仅张三一个词就占用4M空间, 所以这里必然要对其进行压缩,压缩方法主要有以下两种:
i、FOR(Frame Of Reference)压缩
FOR压缩采用的增量编码的技术,大致逻辑如下,假设倒排表中存储的是1、2、3、4、..........、100w连续的数.如果不采用压缩算法需要4*8*1000000=32000000bit,这里如果采用增量编码的技术,1、2、3、4.......100w可以改写成1、1、1、1.............1,后者存储的是相邻两个数的插值,这个时候因为全都是1可以用位来存储,不需要用字节,这时1到100w只需要100w个bit,两者相差32倍.这里不具备参考意义.只是大致的原理.因为例子中的连续条件基本不具备,实际的压缩流程大致如下:
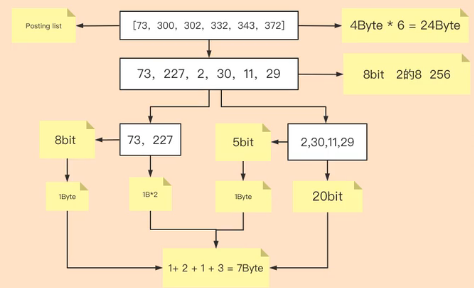
图来自网络.这里需要注意两点:
i、数组不能无限制分下去,因为每分一次数组,该数组会增加一个头标识当前数组中最大的数据需要多少位存储,其余的数字都按照该位数进行存储.但是这个标识会占用空间.
ii、数组拆分的依据时数据的插值是否稠密,如1、3、2、4这种比较稠密的一般不会拆分,但是1、3、2、100000000,这种明显是需要进一步拆分的
iii、具体如何拆分这里只是大概.
ii、RBM压缩算法
有了FOR算法为什么需要别的算法呢?说明FOR算法本身是有缺陷的,那么思考一下FOR算法的缺陷在哪里?
FOR算法的核心是用减法来缩减数值大小,但是减法一定能缩减大小吗?但数值大小很大时,减法能够达到的效果是不明显的,比如100W,200W,300W,相减后是100W,100W,100W,依然很大,这时的压缩效果很不理想,所以引入了RBM算法
那么大家再思考一下,既然减法不能满足,那么还有什么方法能够更快地减小数值大小呢?
没错,就是除法!
RBM的核心就是通过除法来缩减数值大小,但是并不是直接的相除。
比如数组为1000,62101,131385,191173,196658
其中196658的二进制表示为0000 0000 0000 0011 0000 0000 0011 0010
然后将其高16位和低16位分别转换为10进制:
0000 0000 0000 0011 -> 3
0000 0000 0011 0010 -> 50
那么196658就转换成了(3,50)的表示形式,其效果就相当于除以2^16,商3余50
这里的计算用位运算会更快更好理解,除以2^n相当于将这个数的二进制向右位移n位(不含符号位),并且用0补足空位。容易得出196658二进制右移16位后为
0000 0000 0000 0000 0000 0000 0000 0011
也就是其高16位,前面用0补足,而被位移顶替掉的就是其余数0000 0000 0011 0010
因为商和余数都不超过16位,那么我们最大用16bit来存储足够了。也就是short类型,占用2个字节。因此商和余数都可以用一个short来盛装,那么所有的商就是一个short[],所有的余数就是一个short[][]将原数组除以2^16得:
(0,1000),(0,62101),(2,313),(2,980),(2,60101),(3,50)
转化为二维数组盛装
0: 1000,62101
2: 313,980,60101
3: 50
我们把每一个商所对应的余数short[]称之为一个容器Container,使用上述所说的short盛装也称为ArrayContainer
我们也容易观察发现到,每一个Container实际上都是有序数值数组,是不是能够联想到什么?
数组还能进行压缩吗?
数组能用FOR算法再压缩吗?
有别的方式再进行压缩吗?
首先回答前两个问题:数组肯定可以压缩,而且正是我们需要去做的;用FOR算法在这里进行压缩是可以的,不算错,但是我们说不合适,正如在FOR算法中介绍的那样,压缩的同时我们还有考虑解码时的效率,其实这里已经经过除法做了一次处理了,那么再用减法做一次处理,再解码时效率会降低不少,所以我们追求的是一种解码更加容器,但又能具备压缩能力的方法。
因此我们就可以使用bitmap来存储数据,按照规定一个Container的最大值是65534(这里为什么最大值是65534,思考一下,如果不明白往上看看原数组是怎么处理的),也就需要65535bit=8k的容器来存储,当然bitmap有个很明显的缺点,那就是无论Container中有多少个数,都要占用8k的大小,所以当数量不超过65535bit /16bit = 4096个时,使用short (16bit)来存储更划算,当每个Container的数量超过4096个时使用bitmap更加划算,那么使用bitmap的Container称为BitmapContainer
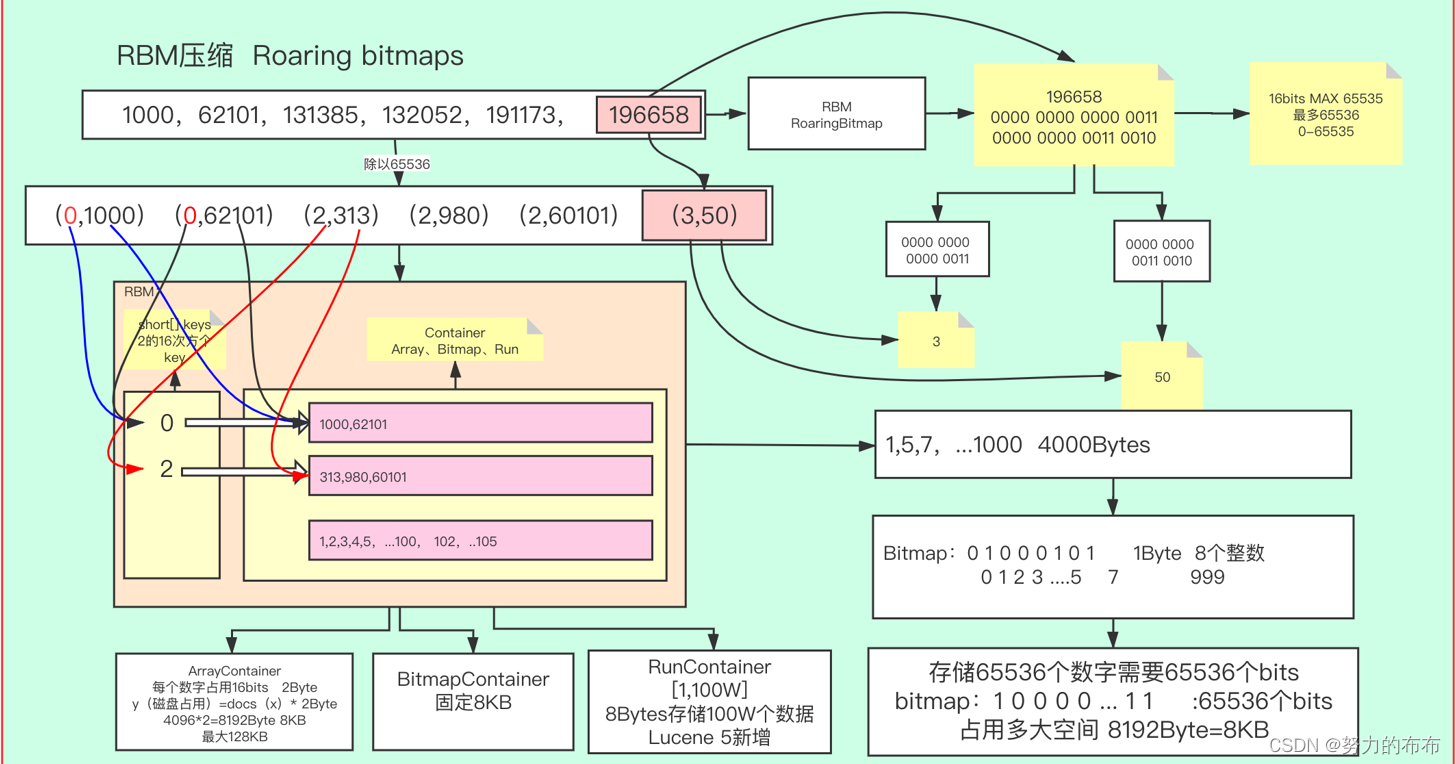
进行一个小小的总结,RBM的算法核心就是把数据表示成2进制共32位,分为高16和低16.分别存储,所以最大就是2的16次方65536,65536。
如果用short存储,需要65536个short数据类型就是65536x2byte再除以1024就是128KB。
如果用BitMapContainer存储,需要的是65536个比特位,当前索引有数据就是1没有就是0,还是用二进制01表示,65536比特位除以8是8192个比特再除以1024就是8KB。
用数组short最大是128KB,bitmap最大是8KB且固定。
再算一下,8KB可以存储多少个short类型的数据,8x1024=8192个byte,8192除以2是4096表示可以存储4096个short数组,所以低于4096用short存储比较节省空间,高于4096用bitmap比较好节省空间。
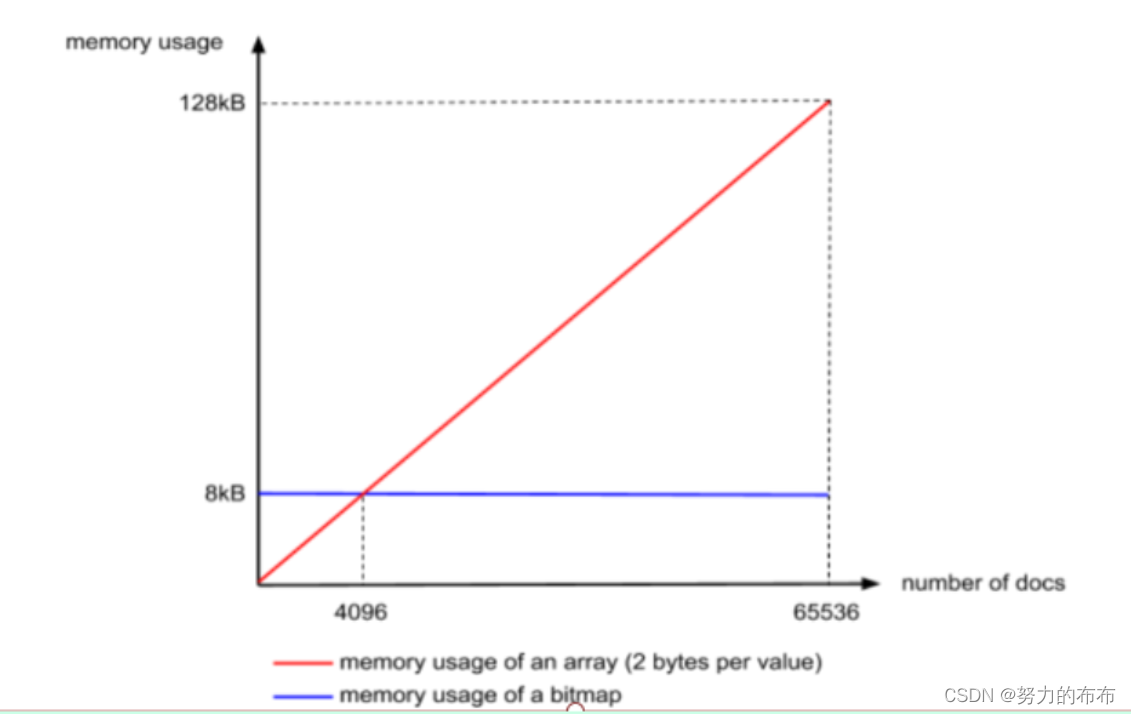
RBM算法的核心步骤如下:
(1)数组中每个数除以2^16,以商,余数的形式表示出来
(2)将相同商的归在一个Container,如果Contaniner中数值容量超过4096使用bitmap的形式来存储一个Container中的数,如果没有超过那就使用short[]来存储,如果是连续数组那就使用RunContainer来存储
来自努力的布布
(4)、FST