6.1 参数化详解:
首先,我还是要巴拉巴拉一下参数化的概念和意义,什么叫做参数化:参数化,就是在我们录制好脚本,或者写好提交请求中那些被写死的值,但是这些值又会因为提交请求不同或者用户要求变化而做的一个工作,其本质就是每次提交中力求能让这个参数的值得到变动更新。那么为什么要参数化:简单的说,就是为了更符合需求,让模拟的提交数据更符合真实数据。比如测试登入功能,如果不做参数化,那么所有的提交请求都是同一个用户在做登入操作,虽然不见得每个系统都对用户登入做了限制值允许同一个用户同一时间登入一次,在没有做这个限制的系统里面,测试登入场景的并发,使用一个账号做并发和使用不同的很多账号做并发,在提交过程中看似并没有什么不一样(服务端缓存除外),但是从数据看,还是显得太没有说服力了,至少真实情况不是这样的,因此为了更贴切的模拟出真实环境的效果。(当然也还有其他原因,比如刚才提到的服务器端缓存,如果同一个用户不断去并发,则实际上登入操作的一些查询是不走库的,直接走缓存了,这样跟我们需求的实际情况是不相符的。)
LR中(不局限于LR)参数化详解:
先允许我拿一个小例子来讲:
web_custom_request("jyzdgateway.aicai.com/gataway",
"URL=http://jyzdgateway.aicai.com/gataway/req?service_name=ec_freeze_balance&partner_id=10001&sign=f745fae2c597ce28b682fd120d76b75e&sign_type=MD5&request_time=20150725120026&out_freeze_no=dj{NewParam}&freeze_amount=10&identity_id={NewParam_1}&account_type=MEMBER&summary=HAHA TEST SUMMARY&ext1=ext11&ext2=ext2222&ip=192.168.1.1&_input_charset=UTF-8",
"Method=get",
"Resource=1",
"Referer=",
"Snapshot=t2.inf",
// "EncType=",
LAST);
上面这个提交是账户资金冻结接口,其中传入了很多参数,其中主要有一个用户ID,以及订单号,这两个是要重点关注并参数化的,一个是用户维度的,这里业务是支付冻结,涉及到账户表计流水表的操作,那么如果同一时间,对同一个用户钱包进行更改操作,会产生什么情况,当然,不同业务下可能还是允许的,但如果同一种业务同时多笔请求对该用户记录进行更新操作,这在真实情况中应该是不存在的,所以这里就对用户ID的参数化提出了一个要求----并发过程中保证同一用户的钱包记录被单个请求占用。所以这样就让我们在选择以何种方式进行参数化提供了依据。显然的,这里我们需要选择unique,至于每次循环是否迭代,我这里选择的once,也就是说只在第一次取值时,每个并发用户都取不一样的,后续每次迭代都使用第一次的取值。当然,如果准备的用户量够大,够多,也可以选择每次迭代(前提是要准备足够多的用户,要不会报错测试不能进行)。
还是按部就班的来,先介绍一下参数化的类型:
图中可以看到,参数化的类型有很多,我大概讲几种把,比较常用的一种,file:就是读取一个制定好的文件按照配资好的规格取值的方式。优势很明显,参数都是自己制定的,可控且保证正确性。麻烦就是,数据量大的时候,要花很多时间去整这个文件。Random Number:随机数参数,这个可以看成一个随机函数生成的值,真的很随机,完了LR自己都不知道下一个是啥值,这种方式在一些场景下能发挥重要作用,比如一些需要客户端生成的参数但对唯一性要求又不是那么高的情况,其实即使我上面的订单号(其实对唯一性要求还是比较高的),也是可以使用这个类型的,大不了设置两个5位的随机数组装起来,这样,跑的时间不长的话,其实重复的可能性很小。unique Number,唯一随机数,自动生成,适用于一些页面传递过来的唯一值。还有一种高端点的链接数据库做参数化,这个后续会开一个单独的章节讲一下。
当同一个脚本中有几个参数进行参数化的时候,比如登入脚本中,用户名和密码,这时候就要保证一个关系,就是当取的用户名是A是,则必须取A对应的密码,才算参数化成功,这样才能正常登入。这种关系实际上在LR中参数化的时候设置一下就好了。比如:
在做这个参数化文件的时候,我们一般会把相关联的参数放到一起,用户名一列,密码一列,并且一一对应好。
然后当我们选择好用户名参数化后,密码参数化的时候,就会在selectcolumn出现一个select by用户名。的选项,就是说,用户名取那个,密码则取同一行的一个,自然就一一对应了。
说完了这些基本的设置,真正参数化比较难以理解的来了。最容易搞混,也最难理解的就是真正在场景中并发跑脚本的时候,每个用户每次循环到底是如何取值的,接下来就详细的来介绍一下:
脚本设置完参数化,脚本运行的每一遍所取的参数化的值都不一样,那么这个值按照个什么情况来取呢?
Select next row【选择下一行】:
select next row的意思就是,取下一个参数的方式,有三种,按顺序一个个取,从第一个取值到最后一个,或者随机取值,就是每次迭代的时候,随机在所有参数里面抽取一个作为这次迭代的值。还有就是唯一,唯一的意思是每次参数取值时,都取跟其他参数不一样的值,并且每次迭代都保证不一样,所以才说,唯一的取值方式能保证每个用户的每次迭代取值唯一,因此这时候所需要的参数值的量十分巨大,比如一个脚本打算用5个虚拟用户去并发跑场景,而跑5分钟,每个用户假如能迭代50次,那么这5个用户在这5分钟所需要的参数就是50*5=250个参数。当然,这里的250个参数是指参数的个数,至于这250个参数里面,可能存在值一样的,则没关系,因为LR取值时按照行号(可以认为是ID号来取的),只要ID号不一样,则被认为是不一样的参数。
顺序(Sequential):按照参数化的数据顺序,一个一个的来取。
随机(Random):参数化中的数据,每次随机的从中抽取数据。
唯一(Unique):为每个虚拟用户分配一条唯一的数据
Update value on【更新时的值】:
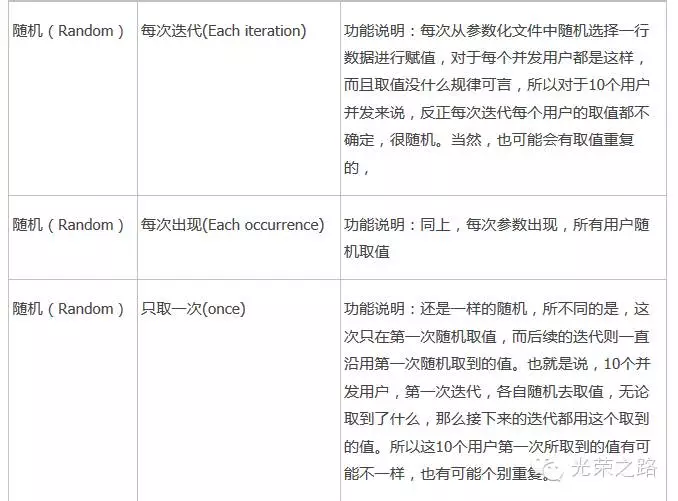
update value on XXX,就是说参数的值在什么时候更新,为什么要有这个设置呢?是因为我们脚本中有可能同一个参数会出现多次,也有可能我们业务需求,需要这几个同样的参数在每次循环中保证一致的值,但有时候业务需要又需要这几个同样的参数每次出现都以不同的值出现,甚至有时候,因为业务特性,这些值只需要在第一次循环的时候进行参数化,之后的数据可以一致保持不变。因此这里会有按每次迭代更新参数值,按每次参数出现时,更新参数值,和once,即只在第一次参数化时更新参数值。
每次迭代(Each iteration):每次迭代时取新的值,假如50个用户都取第一条数据,称为一次迭代;完了50个用户都取第二条数据,后面以此类推。
每次出现(Each occurrence):每次参数时取新的值,这里强调前后两次取值不能相同。
只取一次(once):参数化中的数据,一条数据只能被抽取一次。(如果数据轮次完,脚本还在运行将会报错)
上面两个选项都有三种情况,如果将他们进行组合,将产生九种取值方式。