目录结构
| 文件名 | 主要功能 |
|---|
| arjun.py |
发现隐藏的参数 |
| broswerEngine.py |
selenium浏览器引擎,根据弹窗判断xss是否发生 |
| checker.py |
检查过滤器 |
| colors.py |
定义相关颜色变量,这样在输出不同类型信息时就可以有不同的颜色 |
| config.py |
一些重要配置,默认配置,例如:payloads,fuzzs等 |
| dom.py |
搜索dom xss相关特征 |
| encoders.py |
编码相关函数 |
| filterChecker.py |
检查过滤器 |
| fuzzer.py |
fuzz测试的核心代码 |
| generator.py |
payload生成引擎 |
| htmlParser.py |
通过解析html,找出我们的输入输出在了哪种环境下 |
| jsContexter.py |
|
| photon.py |
爬取页面中的表单与链接 |
| prompt.py |
添加headers时会弹出一个编辑器,默认为nano |
| requester.py |
发送http请求的函数 |
| updater.py |
更新时会调用的函数 |
| utils.py |
里面是一些使用的小函数 |
| wafDetector.py |
探测waf |
| zetanize.py |
爬取页面中的表单 |
| 文件名 | 主要功能 |
|---|
| wafSignatures.json |
waf特征库,存储着各个waf的特征,可以根据这些特征去判断waf |
| 文件名 | 主要功能 |
|---|
| bruteforcer.py |
暴力测试每个参数 |
| crawl.py |
爬行页面内的所有链接 |
| scan.py |
扫描功能 |
| singleFuzz.py |
fuzz测试 |
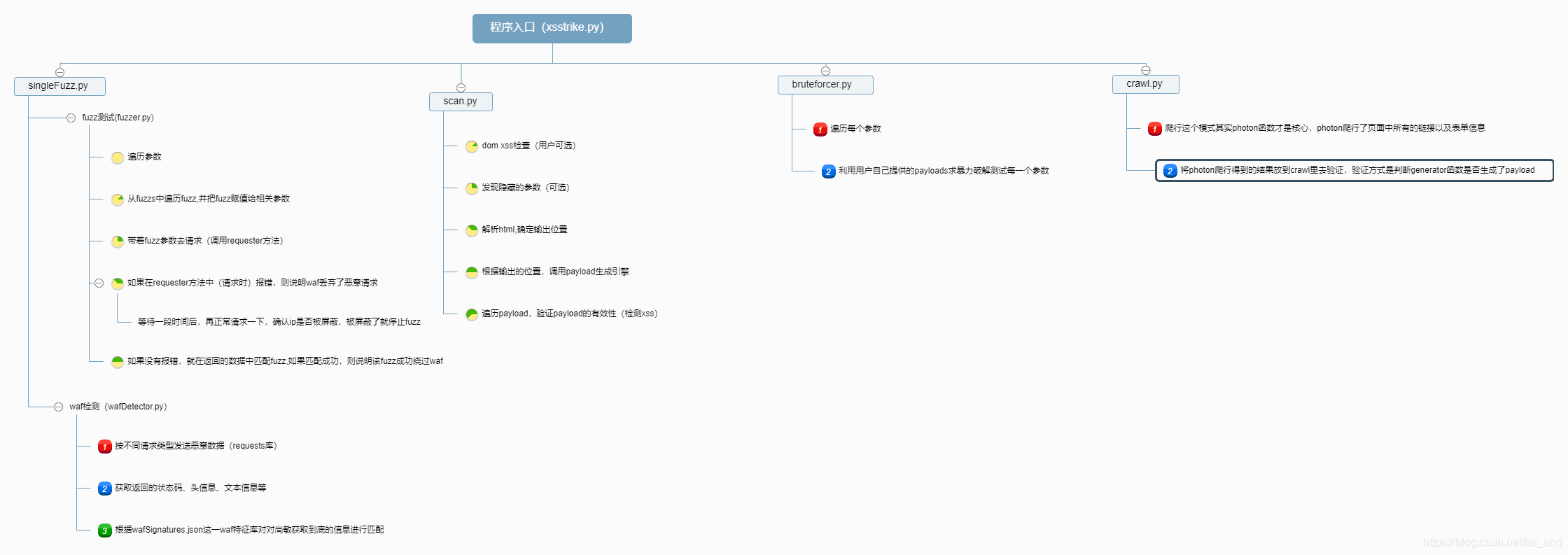
- xsstrike.py(主文件)
主文件做的事其实也很简单,就是处理命令行参数,然后根据用户输入的命令行参数(开关)来调用相关函数
扫描器架构
下图是我整理的一个扫描器大概的工作图谱,比较粗略,后续文章将会就一些重点函数或文件进行细致解读