一. 引言
Mysql 我们平常用的很多,了解的很多,今天别的不说,直接说mysql的底层是什么,说到底层,就想到数据结构,那么,mysql的数据结构是什么呢? 是B + tree 。那么数据库中的索引是什么呢?
二. 索引是什么?
数据库的目的是为了存储数据,那么索引的概念是什么呢? 最合理的解释,也是官方的解释就是:索引是帮助MySQL高效获取数据的数据结构。关键就是这个数据结构,什么目录的解释都是不合理的。
接下来我们去看看索引到底是如何高效获取数据的
先建一张student表简单的存放数据
id name
1 tom
2 jerry
3 jack
回到很久之前,大家先设想一下,如果之前没有mysql这种RDBMS(关系数据库管理系统)时,这些表存放在哪里呢?肯定是存放在文件之中。
那么,执行一个简单的查询,如 select * from student where id = 1;
如果要执行逐条筛选的话会特别慢,比如要找到 id =100的,就要筛选100条数据,显然是不合理的,那么索引究竟是如何高效获取数据的。
文件系统
首先,我们先看一下我们电脑中的文件系统,数据库数据是如何保存在文件中的
文件系统重要包括柱面 、 磁道和扇区,这是一种比较原始的存储方式

如图所示,如果每次查询都要从头转到尾的检索,效率性能都会很低,那么如果我们将id 与这条数据在扇区的位置记录(address)的对应记录起来的话,每次可以直接找到数据的位置,那么速率则会大大加快,如同我们看书时的目录一样,不需要讲前面的所有内容都过一遍。如下图所示:

到现在为止,我们已经对索引的概念和实现方式有了基本的认识 ,现在我们要谈论两个概念,一般存在于操作系统中,一个是时间局部性原理,一个是空间局部性原理。
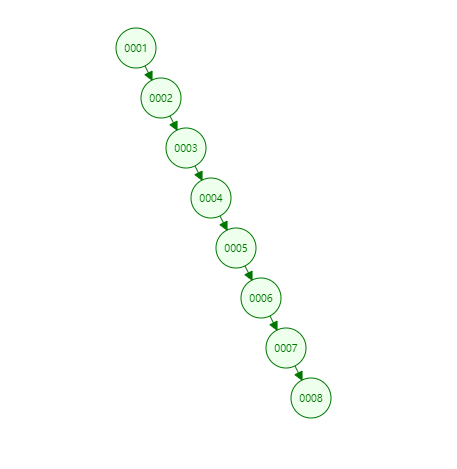
渐进复杂度是递增的!!!
二叉树是线性增加的,而且每个节点只能放一个数据,每查询一个数据,都会从头到尾执行一次,如果查询一次算一个IO的话,查询第1万条数据就要执行1万次IO,显然是不合理的。
红黑树:
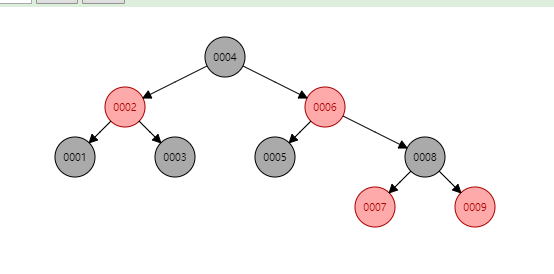
渐进复杂度是递增的!!!
虽然高度减少了,但是高度还是不可控的,IO执行次数还是过多
B + tree
 →
→ 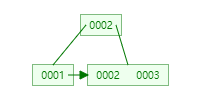 →
→ 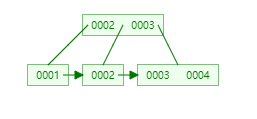 →
→ 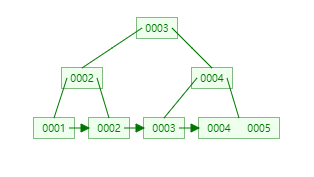
在这里我们发现b+ tree的高度居然是不变的,大家看这些图,如果想查某一id 的值,只需要查两次,比如最后一张图,查id为1 的: 0003 -> 0002 ->0001 ,其余的也都是查两次,这样我们可以得到结论:
在B + Tree中,渐进复杂度是恒定不变的!!!
在B + Tree中,渐进复杂度是恒定不变的!!!
在B + Tree中,渐进复杂度是恒定不变的!!!
重要的事说三遍