Caffe BatchNormalization 推导
总所周知,BatchNormalization通过对数据分布进行归一化处理,从而使得网络的训练能够快速并简单,在一定程度上还能防止网络的过拟合,通过仔细看过Caffe的源码实现后发现,Caffe是通过BN层和Scale层来完整的实现整个过程的。
谈谈理论与公式推导

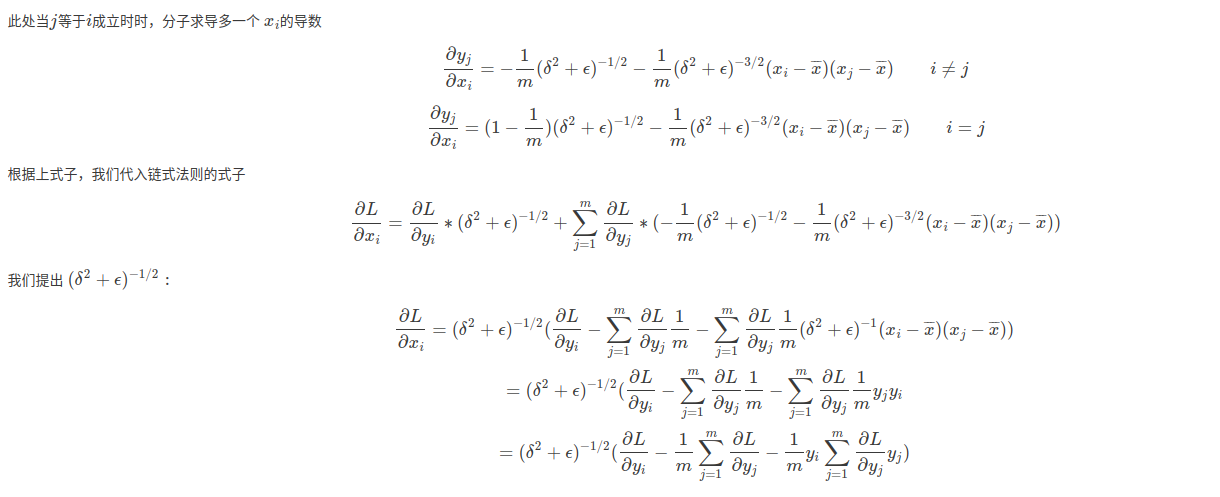
至此,我们可以对应到caffe的具体实现部分
// if Y = (X-mean(X))/(sqrt(var(X)+eps)), then // // dE(Y)/dX = // (dE/dY - mean(dE/dY) - mean(dE/dY cdot Y) cdot Y) // ./ sqrt(var(X) + eps) // // where cdot and ./ are hadamard product and elementwise division,
谈谈具体的源码实现
知道了BN层的公式与原理,接下来就是具体的源码解析,由于考虑到的情况比较多,所以Caffe中的BN的代码实际上不是那么的好理解,需要理解,BN的归一化是如何归一化的:
HW的归一化,求出NC个均值与方差,然后N个均值与方差求出一个均值与方差的Vector,size为C,即相同通道的一个mini_batch的样本求出一个mean和variance
成员变量
BN层的成员变量比较多,由于在bn的实现中,需要记录mean_,variance_,归一化的值,同时根据训练和测试实现也有所差异。
Blob<Dtype> mean_,variance_,temp_,x_norm; //temp_保存(x-mean_x)^2 bool use_global_stats_;//标注训练与测试阶段 Dtype moving_average_fraction_; int channels_; Dtype eps_; // 防止分母为0 // 中间变量,理解了BN的具体过程即可明了为什么需要这些 Blob<Dtype> batch_sum_multiplier_; // 长度为N*1,全为1,用以求和 Blob<Dtype> num_by_chans_; // 临时保存H*W的结果,length为N*C Blob<Dtype> spatial_sum_multiplier_; // 统计HW的均值方差使用
成员函数
成员函数主要也是LayerSetUp,Reshape,Forward和Backward,下面是具体的实现:
LayerSetUp,层次的建立,相应数据的读取
//LayerSetUp函数的具体实现 template <typename Dtype> void LayerSetUp(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top){ // 参见proto中添加的BatchNormLayer BathcNormParameter param = this->layer_param_.batch_norm_param(); moving_average_fraction_ = param.moving_average_fraction();//默认0.99 //这里有点多余,好处是防止在测试的时候忘写了use_global_stats时默认true use_global_stats_ = this->phase_ == TEST; if (param.has_use_global_stat()) { use_global_stats_ = param.use_global_stats(); } if (bottom[0]->num_axes() == 1) { //这里基本看不到为什么.....??? channels_ = 1; } else{ // 基本走下面的通道,因为输入是NCHW channels_ = bottom[0]->shape(1); } eps_ = param.eps(); // 默认1e-5 if (this->blobs_.size() > 0) { // 测试的时候有值了,保存了均值方差和系数 //保存mean,variance, } else{ // BN层的内部参数的初始化 this->blobs_.resize(3); // 均值滑动,方差滑动,滑动系数 vector<int>sz; sz.push_back(channels_); this->blobs_[0].reset(new Blob<Dtype>(sz)); // C this->blobs_[1].reset(new Blob<Dtype>(sz)); // C sz[0] = 1; this->blobs_[2].reset(new Blob<Dtype>(sz)); // 1 for (size_t i = 0; i < 3; i++) { caffe_set(this->blobs_[i]->count(),Dtype(0), this->blobs_[i]->mutable_cpu_data()); } } }
Reshape,根据BN层在网络的位置,调整bottom和top的shape
Reshape层主要是完成中间变量的值,由于是按照通道求取均值和方差,而CaffeBlob是NCHW,因此先求取了HW,后根据BatchN求最后的输出C,因此有了中间的batch_sum_multiplier_和spatial_sum_multiplier_以及num_by_chans_其中num_by_chans_与前两者不想同,前两者为方便计算,初始为1,而num_by_chans_为中间过渡
template <typename Dtype> void BatchNormLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { if (bottom[0]->num_axes() >= 1) { CHECK_EQ(bottom[0]->shape(1),channels_); } top[0]->ReshapeLike(*bottom[0]); // Reshape(bottom[0]->shape()); vector<int>sz; sz.push_back(channels_); mean_.Reshape(sz); variance_.Reshape(sz); temp_.ReshapeLike(*bottom[0]); x_norm_.ReshapeLike(*bottom[0]); sz[0] = bottom[0]->shape(0); //N // 后续会初始化为1,为求Nbatch的均值和方差 batch_sum_multiplier_.Reshape(sz); caffe_set(batch_sum_multiplier_.count(),Dtype(1), batch_sum_multiplier_.mutable_cpu_data()); int spatial_dim = bottom[0]->count(2);//H*W if (spatial_sum_multiplier_.num_axes() == 0 || spatial_sum_multiplier_.shape(0) != spatial_dim) { sz[0] = spatial_dim; spatial_sum_multiplier_.Reshape(sz); //初始化1,方便求和 caffe_set(spatial_sum_multiplier_.count(),Dtype(1) spatial_sum_multiplier_.mutable_cpu_data()); } // N*C,保存H*W后的结果,会在计算中结合data与spatial_dim求出 int numbychans = channels_*bottom[0]->shape(0); if (num_by_chans_.num_axes() == 0 || num_by_chans_.shape(0) != numbychans) { sz[0] = numbychans; num_by_chans_.Reshape(sz); } }
Forward 前向计算
前向计算,根据公式完成前计算,x_norm与top相同,均为归一化的值
template <typename Dtype> void BatchNormLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { // 想要完成前向计算,必须计算相应的均值与方差,此处的均值与方差均为向量的形式c const Dtype* bottom_data = bottom[0]->cpu_data(); Dtype* top_data = top[0]->mutable_cpu_data(); int num = bottom[0]->shape(0);// N int spatial_dim = bottom[0]->count(2); //H*W if (bottom[0] != top[0]) { caffe_copy(top[0]->count(),bottom_data,top_data);//先复制一下 } if (use_global_stats_) { // 测试阶段,使用全局的均值 const Dtype scale_factory = this_->blobs_[2]->cpu_data()[0] == 0? 0:1/this->blobs_[2]->cpu_data()[0]; // 直接载入训练的数据 alpha*x = y caffe_cpu_scale(mean_.count(),scale_factory, this_blobs_[0]->cpu_data(),mean_.mutable_cpu_data()); caffe_cpu_scale(variance_.count(),scale_factory, this_blobs_[1]->cpu_data(),variance_.mutable_cpu_data()); } else{ //训练阶段 compute mean //1.计算均值,先计算HW的,在包含N // caffe_cpu_gemv 实现 y = alpha*A*x+beta*y; // 输出的是channels_*num, //每次处理的列是spatial_dim,由于spatial_sum_multiplier_初始为1,即NCHW中的 // H*W各自相加,得到N*C*average,此处多除以了num,下一步可以不除以 caffe_cpu_gemv<Dtype>(CBlasNoTrans,channels_*num,spatial_dim, 1./(spatial_dim*num),bottom_data,spatial_sum_multiplier_.cpu_data() ,0.,num_by_chans_.mutable_cpu_data()); //2.计算均值,计算N各的平均值. // 由于输出的是channels个均值,因此需要转置 // 上一步得到的N*C的均值,再按照num求均值,因为batch_sum全部为1, caffe_cpu_gemv<Dtype>(CBlasTrans,num,channels_,1, num_by_chans_.cpu_data(),batch_sum_multiplier_.cpu_data(), 0,mean_.mutable_cpu_data()); } // 此处的均值已经保存在mean_中了 // 进行 x - mean_x 操作,需要注意按照通道,即先确定x属于哪个通道. // 因此也是进行两种,先进行H*W的减少均值 // caffe_cpu_gemm 实现alpha * A*B + beta* C // 输入是num*1 * 1* channels_,输出是num*channels_ caffe_cpu_gemm<Dtype>(CBlasNoTrans,CBlasNoTrans,num,channels_,1,1, batch_sum_multiplier_.cpu_data(),mean_.cpu_data(),0, num_by_chans_.mutable_cpu_data()); //同上,输入是num*channels_*1 * 1* spatial = NCHW // top_data = top_data - mean; caffe_cpu_gemm<Dtype>(CBlasNoTrans,CBlasNoTrans,num*channels_, spatial_dim,1,-1,num_by_chans_.cpu_data(), spatial_sum_multiplier_.cpu_data(),1, top_data()); // 解决完均值问题,接下来就是解决方差问题 if (use_global_stats_) { // 测试的方差上述已经读取了 // compute variance using var(X) = E((X-EX)^2) // 此处的top已经为x-mean_x了 caffe_powx(top[0]->count(),top_data,Dtype(2), temp_.mutable_cpu_data());//temp_保存(x-mean_x)^2 // 同均值一样,此处先计算spatial_dim的值 caffe_cpu_gemv<Dtype>(CblasNoTrans,num*channels_,spatial_dim, 1./(num*spatial_dim),temp_.cpu_data(), spatial_sum_multiplier_.cpu_data(),0, num_by_chans_.mutable_cpu_data(); ) caffe_cpu_gemv<Dtype>(CBlasTrans,num,channels_,1., num_by_chans_.cpu_data(),batch_sum_multiplier_.cpu_data(), 0,variance_.mutable_cpu_data());// E((X_EX)^2) //均值和方差计算完成后,需要更新batch的滑动系数 this->blobs_[2]->mutable_cpu_data()[0] *= moving_average_fraction_; this->blobs_[2]->mutable_cpu_data()[0] += 1; caffe_cpu_axpby(mean_.count(),Dtype(1),mean_.cpu_data(), moving_average_fraction_,this->blobs_[0]->mutable_cpu_data()); int m = bottom[0]->count()/channels_; Dtype bias_correction_factor = m > 1? Dtype(m)/(m-1):1; caffe_cpu_axpby(variance_.count(),bias_correction_factor, variance_.cpu_data(),moving_average_fraction_, this->blobs_[1]->mutable_cpu_data()); } // 方差求个根号,加上eps为防止分母为0 caffe_add_scalar(variance_.count(),eps_,variance_.mutable_cpu_data()); caffe_powx(variance_.count(),variance_.cpu_data(),Dtype(0.5), variance_.mutable_cpu_data()); // top_data = x-mean_x/sqrt(variance_),此处的top_data已经转化为x-mean_x了 // 同减均值,也要分C--N*C和 N*C --- N*C*H*W // N*1 * 1*C == N*C caffe_cpu_gemm<Dtype>(CBlasNoTrans,CBlasNoTrans,num,channels_,1,1, batch_sum_multiplier_.cpu_data(),variance_.cpu_data(),0, num_by_chans_.mutable_cpu_data()); // NC*1 * 1* spatial_dim = NCHW caffe_cpu_gemm<Dtype>(CBlasNoTrans,CBlasNoTrans,num*channels_,spatial_dim, 1, 1.,num_by_chans_.cpu_data(),spatial_sum_multiplier_.cpu_data(), 0, temp_.mutable_cpu_data()); // temp最终保存的是sqrt(方差+eps) caffe_cpu_div(top[0].count(),top_data,temp_.cpu_data(),top_data); }
整个forward过程按照x-mean/variance的过程进行,包含了求mean和variance,他们都是C*1的向量,然后输入的是NCHW,因此通过了gemm操作做广播填充到整个featuremap然后完成减mean和除以方差的操作。同时需要注意caffe的inplace操作,所以用x_norm保存原始的top值,后续修改也不会影响它。
Backward过程,根据梯度,反向计算
Backward过程会根据前面所推导的公式进行计算,具体的实现如下面所示.
template <typename Dtype> void BatchNormLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down,const vector<Blob<Dtype>*>& bottom) { const Dtype* top_diff; if (bottom[0] != top[0]) { // 判断是否同名 top_diff = top[0]->cpu_diff(); } else{ caffe_copy(x_norm_.count(),top[0]->cpu_diff(),x_norm_.mutable_cpu_diff()); top_diff = x_norm_.cpu_diff(); } Dtype* bottom_diff = bottom[0]->mutable_cpu_diff(); if (use_global_stats_) { // 测试阶段 caffe_div(temp_.count(),top_diff,temp_.cpu_data(),bottom_diff); return ; // 测试阶段不需要计算梯度。 } const Dtype* top_data = x_norm_.cpu_data(); int num = bottom[0]->shape(0); //n int spatial_dim = bottom[0]->count(2); // H*W // 根据推导的公式开始具体计算。 // dE(Y)/dX = // (top_diff- mean(top_diff) - mean(top_diff cdot Y) cdot Y) // ./ sqrt(var(X) + eps) // sum(top_diff cdot Y) ,y为x_norm_ NCHW,求取的均先求C通道的均值 caffe_mul(temp_.count(),top_data,top_diff,bottom_diff); //NC*HW* HW*1 = NC*1 caffe_cpu_gemv<Dtype>(CblasNoTrans,channels_*num,spatial_dim,1., bottom_diff,spatial_sum_multiplier_.cpu_data(),0, num_by_chans_.mutable_cpu_data()); // (NC)^T*1 * N*1 = C*1 caffe_cpu_gemv<Dtype>(CBlasTrans,num,channels_,1., num_by_chans_.cpu_data(),batch_sum_multiplier_.cpu_data(), 0,mean_.mutable_cpu_data()); //reshape broadcast // N*1 * 1* C = N* C caffe_cpu_gemm<Dtype>(CblasNoTrans,CblasNoTrans,num,channels_,1,1, batch_sum_multiplier_.cpu_data(),mean_.cpu_data(),0, num_by_chans_.mutable_cpu_data()); // N*C *1 * 1* HW = NC* HW caffe_cpu_gemm<Dtype>(CblasNoTrans,CblasNoTrans,num*channels_,spatial_dim, 1,1.,num_by_chans_.cpu_data(),spatial_sum_multiplier_.cpu_data(),0, bottom_diff); //相当与 sum (DE/DY .cdot Y) // sum(dE/dY cdot Y) cdot Y caffe_mul(temp_.count(), top_data, bottom_diff, bottom_diff); // 完成了右边一个部分,还有前面的 sum(DE/DY)和DE/DY // 再完成sum(DE/DY) caffe_cpu_gemv<Dtype>(CblasNoTrans,channels_*num,spatial_dim,1, top_diff,spatial_sum_multiplier_.cpu_data(),0., num_by_chans_.mutable_cpu_data()); caffe_cpu_gemv<Dtype>(CBlasTrans,num,channels_,1., num_by_chans_.cpu_data(),batch_sum_multiplier_.cpu_data(),0, mean_.mutable_cpu_data()); //reshape broadcast caffe_cpu_gemm<Dtype>(CblasNoTrans,CblasNoTrans,num,channels_,1, 1,batch_sum_multiplier_.cpu_data(),mean_.cpu_data(),0, num_by_chans_.mutable_cpu_data()); // 现在完成了sum(DE/DY)+y*sum(DE/DY.cdot y) caffe_cpu_gemm<Dtype>(CblasNoTrans,CblasNoTrans,num*channels_,spatial_dim, 1,1.,num_by_chans_.cpu_data(),spatial_sum_multiplier_.cpu_data(),1, bottom_diff); //top_diff - 1/m * (sum(DE/DY)+y*sum(DE/DY.cdot y)) caffe_cpu_axpby(bottom[0]->count(),Dtype(1),top_diff, Dtype(-1/(num*spatial_dim)),bottom_diff); // 前面还有常数项 variance_+eps caffe_div(temp_.count(),bottom_diff,temp_.cpu_data(),bottom_diff); }
backward的过程也是先求出通道的值,然后广播到整个feature_map,来回两次,然后调用axpby完成 top_diff - 1/m* (sum(top_diff)+ysum(top_diffy)))这里的y针对通道进行。
本文作者: 张峰
本文链接:http://www.enjoyai.site/2017/11/06/
版权声明:本博客所有文章,均采用CC BY-NC-SA 3.0 许可协议。转载请注明出处!