总结笔记:对于每个用户请求,由主线程接收并存放于一个事件队列中(不做任何处理),当无请求发生时,即主线程空闲,主线程开始循环处理事件队列中的任务:
对于非阻塞JS程序:
1、若某事件需要I/O操作,则主线程发出I/O请求,然后继续执行,由底层的程序实现I/O并返回I/O数据(底层程序是多线程的,JS是单线程的),底层I/O线程处理完后将该事件重新放入事件队列并释放当前线程;
2、某事件不需要I/O操作,则主线程直接处理;(由其他线程处理后放入的事件此时也被主线程直接处理掉);
对于阻塞JS程序:
1、若某事件需要I/O操作,则主线程发出I/O请求,然后等待I/O结束,由底层的程序实现I/O并返回I/O数据,主线程获得该事件所需数据后继续处理该事件;
2、某事件不需要I/O操作,则主线程直接处理;
综上可知,node.js由js解释程序和底层代码实现,JS代码是主线程,是单线程执行,而底层代码是多线程,可同时处理多个I/O请求,js中的阻塞与非阻塞代码只决定js在I/O时继不继续执行(当然,若阻塞执行,底层多线程也没啥用了),而底层会为每一个I/O请求创建一个线程;
注意:这只是对Node.js的一个分析,用来理解nodejs的线程模型而已,实际使用要具体问题具体分析,建议结合http://www.runoob.com/nodejs/nodejs-callback.html中的阻塞与非阻塞来学习,阻塞即只要一个主线程执行所有操作,当事件需要I/O操作则主线程等待I/O完成再继续执行,而非阻塞,即对事件处理使用了事件回调,此时,主线程将继续执行下一步的代码而不用等待该事件I/O完成,当I/O完成时主线程再针对该事件执行相应的回调函数;
例如:1、
var http = require('http');
http.createServer(function (request, response) {
// 发送 HTTP 头部
// HTTP 状态值: 200 : OK
// 内容类型: text/plain
response.writeHead(200, {'Content-Type': 'text/plain'});
// 发送响应数据 "Hello World"
response.end('Hello World
');
}).listen(8888);
// 终端打印如下信息
console.log('Server running at http://127.0.0.1:8888/');
该主线程只做三件事:1、侦听8888端口(侦听操作也可以理解为是I/O操作,因而应当也是由底层程序实现,即底层程序监听端口,若有事件,则放入事件队列,继续侦听端口); 2、JS主线程处理并生成返回数据; 3、返回处理结果(此步骤是I/O操作,由线程池处理);
2、
var fs = require("fs");
fs.readFile('input.txt', function (err, data) {
if (err) return console.error(err);
console.log(data.toString());
});
console.log("程序执行结束!");
该主线程在执行I/O时不等待I/O完成,直接继续执行,线程池线程执行完后将结果返还给主线程,主线程执行回调函数并处理事件;
正文
Node.js 采用事件驱动和异步 I/O 的方式,实现了一个单线程、高并发的 JavaScript 运行时环境,而单线程就意味着同一时间只能做一件事,那么 Node.js 如何通过单线程来实现高并发和异步 I/O?本文将围绕这个问题来探讨 Node.js 的单线程模型 。
1、高并发策略
一般来说,高并发的解决方案就是提供多线程模型,服务器为每个客户端请求分配一个线程,使用同步 I/O,系统通过线程切换来弥补同步 I/O 调用的时间开销。比如 Apache 就是这种策略,由于 I/O 一般都是耗时操作,因此这种策略很难实现高性能,但非常简单,可以实现复杂的交互逻辑。
而事实上,大多数网站的服务器端都不会做太多的计算,它们接收到请求以后,把请求交给其它服务来处理(比如读取数据库),然后等着结果返回,最后再把结果发给客户端。因此,Node.js 针对这一事实采用了单线程模型来处理,它不会为每个接入请求分配一个线程,而是用一个主线程处理所有的请求,然后对 I/O 操作进行异步处理,避开了创建、销毁线程以及在线程间切换所需的开销和复杂性。
2、事件循环
Node.js 在主线程里维护了一个事件队列,当接到请求后,就将该请求作为一个事件放入这个队列中,然后继续接收其他请求。当主线程空闲时(没有请求接入时),就开始循环事件队列,检查队列中是否有要处理的事件,这时要分两种情况:如果是非 I/O 任务,就亲自处理,并通过回调函数返回到上层调用;如果是 I/O 任务,就从 线程池 中拿出一个线程来处理这个事件,并指定回调函数,然后继续循环队列中的其他事件。
当线程中的 I/O 任务完成以后,就执行指定的回调函数,并把这个完成的事件放到事件队列的尾部,等待事件循环,当主线程再次循环到该事件时,就直接处理并返回给上层调用。 这个过程就叫 事件循环 (Event Loop),其运行原理如下图所示:
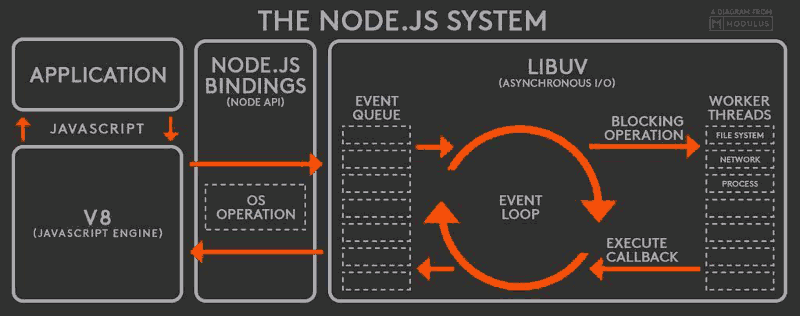
这个图是整个 Node.js 的运行原理,从左到右,从上到下,Node.js 被分为了四层,分别是 应用层、V8引擎层、Node API层 和 LIBUV层。
- 应用层: 即 JavaScript 交互层,常见的就是 Node.js 的模块,比如 http,fs
- V8引擎层: 即利用 V8 引擎来解析JavaScript 语法,进而和下层 API 交互
- NodeAPI层: 为上层模块提供系统调用,一般是由 C 语言来实现,和操作系统进行交互 。
- LIBUV层: 是跨平台的底层封装,实现了 事件循环、文件操作等,是 Node.js 实现异步的核心 。
无论是 Linux 平台还是 Windows 平台,Node.js 内部都是通过 线程池 来完成异步 I/O 操作的,而 LIBUV 针对不同平台的差异性实现了统一调用。因此,Node.js 的单线程仅仅是指 JavaScript 运行在单线程中,而并非 Node.js 是单线程。
3、事件驱动模型
Node.js 实现异步的核心是事件驱动,也就是说,它把每一个任务都当成 事件 来处理,然后通过 Event Loop 模拟了异步的效果,为了更具体、更清晰的理解和接受这个事实,下面我们用伪代码来描述一下这个实现过程 。
【1】定义事件队列
既然是队列,那就是一个先进先出 (FIFO) 的数据结构,我们用JS数组来描述,如下:
|
1
2
3
4
5
6
7
|
/** * 定义事件队列 * 入队:push() * 出队:shift() * 空队列:length == 0 */globalEventQueue: [] |
我们利用数组来模拟队列结构:数组的第一个元素是队列的头部,数组的最后一个元素是队列的尾部,push() 就是在队列尾部插入一个元素,shift() 就是从队列头部弹出一个元素。这样就实现了一个简单的事件队列。
【2】定义接收请求入口
每一个请求都会被拦截并进入处理函数,如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
/** * 接收用户请求 * 每一个请求都会进入到该函数 * 传递参数request和response */processHttpRequest:function(request,response){ //定义一个事件对象 var event = createEvent({ params:request.params, //传递请求参数 result:null, //存放请求结果 callback:function(){} //指定回调函数 }); //在队列的尾部添加该事件 globalEventQueue.push(event);} |
这个函数很简单,就是把用户的请求包装成事件,放到队列里,然后继续接收其他请求。
【3】定义 Event Loop
当主线程处于空闲时就开始循环事件队列,所以我们还要定义一个函数来循环事件队列:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
/** * 事件循环主体,主线程择机执行 * 循环遍历事件队列 * 处理非IO任务 * 处理IO任务 * 执行回调,返回给上层 */eventLoop:function(){ //如果队列不为空,就继续循环 while(this.globalEventQueue.length > 0){ //从队列的头部拿出一个事件 var event = this.globalEventQueue.shift(); //如果是耗时任务 if(isIOTask(event)){ //从线程池里拿出一个线程 var thread = getThreadFromThreadPool(); //交给线程处理 thread.handleIOTask(event) }else { //非耗时任务处理后,直接返回结果 var result = handleEvent(event); //最终通过回调函数返回给V8,再由V8返回给应用程序 event.callback.call(null,result); } }} |
主线程不停的检测事件队列,对于 I/O 任务,就交给线程池来处理,非 I/O 任务就自己处理并返回。
【4】处理 I/O 任务
线程池接到任务以后,直接处理IO操作,比如读取数据库:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
/** * 处理IO任务 * 完成后将事件添加到队列尾部 * 释放线程 */handleIOTask:function(event){ //当前线程 var curThread = this; //操作数据库 var optDatabase = function(params,callback){ var result = readDataFromDb(params); callback.call(null,result) }; //执行IO任务 optDatabase(event.params,function(result){ //返回结果存入事件对象中 event.result = result; //IO完成后,将不再是耗时任务 event.isIOTask = false; //将该事件重新添加到队列的尾部 this.globalEventQueue.push(event); //释放当前线程 releaseThread(curThread) })} |
当 I/O 任务完成以后就执行回调,把请求结果存入事件中,并将该事件重新放入队列中,等待循环,最后释放当前线程,当主线程再次循环到该事件时,就直接处理了。
总结以上过程我们发现,Node.js 只用了一个主线程来接收请求,但它接收请求以后并没有直接做处理,而是放到了事件队列中,然后又去接收其他请求了,空闲的时候,再通过 Event Loop 来处理这些事件,从而实现了异步效果,当然对于IO类任务还需要依赖于系统层面的线程池来处理。
因此,我们可以简单的理解为:Node.js 本身是一个多线程平台,而它对 JavaScript 层面的任务处理是单线程的。
4、CPU密集型是短板
至此,对于 Node.js 的单线程模型,我们应该有了一个简单而又清晰的认识,它通过事件驱动模型实现了高并发和异步 I/O,然而也有 Node.js 不擅长做的事情:
上面提到,如果是 I/O 任务,Node.js 就把任务交给线程池来异步处理,高效简单,因此 Node.js 适合处理I/O密集型任务。但不是所有的任务都是 I/O 密集型任务,当碰到CPU密集型任务时,即只用CPU计算的操作,比如要对数据加解密(node.bcrypt.js),数据压缩和解压(node-tar),这时 Node.js 就会亲自处理,一个一个的计算,前面的任务没有执行完,后面的任务就只能干等着 。如下图所示:
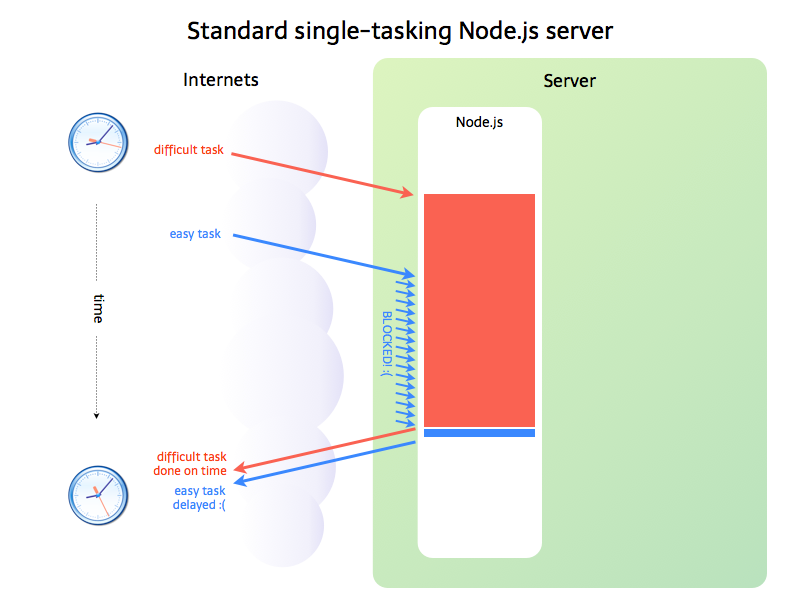
在事件队列中,如果前面的 CPU 计算任务没有完成,后面的任务就会被阻塞,出现响应缓慢的情况,如果操作系统本身就是单核,那也就算了,但现在大部分服务器都是多 CPU 或多核的,而 Node.js 只有一个 EventLoop,也就是只占用一个 CPU 内核,当 Node.js 被CPU 密集型任务占用,导致其他任务被阻塞时,却还有 CPU 内核处于闲置状态,造成资源浪费。
因此,Node.js 并不适合 CPU 密集型任务。
5、适用场景
- RESTful API: 请求和响应只需少量文本,并且不需要大量逻辑处理, 因此可以并发处理数万条连接。
- 聊天服务: 轻量级、高流量,没有复杂的计算逻辑。