我认为整理文献的主要目的就是:能够在任何条件下,快速找到所需信息。任何好用的软件,都不如大批量多批次的文献阅读。
我的思路是:轻整理,重搜索。轻整理,是指不对文献分类,或者只是对文献简单分类。重搜索,是指利用不同的搜索工具,快速定位到我需要的文献。我认为在现在搜索技术已经很强大的情况下,如果利用笔记等手段整理,反而容易造成条条框框,在对于一篇文献关注太长的时间,不利于提高效率。在日常使用中, 除了在文献PDF上直接标注,我很少用其他的软件去记录我看过的文献。因为除了文献本身,其他还有什么载体能够那么直接方便地记录呢?所以整理文献问题就成了:如何快速找出那篇有我笔记的PDF文献。以此为目的,我建立了一套以文献PDF云同步为基础,辅以大量搜索工具的文献整理方案。
其实做过科研工作的人都会发现,其实真正需要把一篇文献从头到尾读完的情况是很少的。在大多数情况下,我们需要的其实是大批量多轮次地阅读文献,因为在一个项目的不同阶段,哪怕是同一篇文献,所关注的点也是不一样的。如果在项目初期,就对所有的文献,都投入同样的时间,阅读同样的深度,势必会浪费大量时间和做无用功。我曾经也走过文献整理的弯路,每阅读一篇文献,都会在Onenote上建立一个条目,按照文献题目,创新点,实验过程,个人感想等分别填空。但是文献读的多了之后,这个方法我觉得效率不高,用的频率也越来越少了。
我现在的主要方法是:以Mendeley建立电子文献索引为主,并以云端同步PDF文献为主要储存手段,通过Everything,Google Scholar,桌面搜索软件,Onenote笔记等多种搜索手段,快速找到自己所要的信息。
==================干货开始=====================
**重搜索部分**
在新项目(写一篇综述,开始一个新课题或者完成一份大作业)开始之前,我会在Mendeley中根据不同项目,建立一个新文件夹。
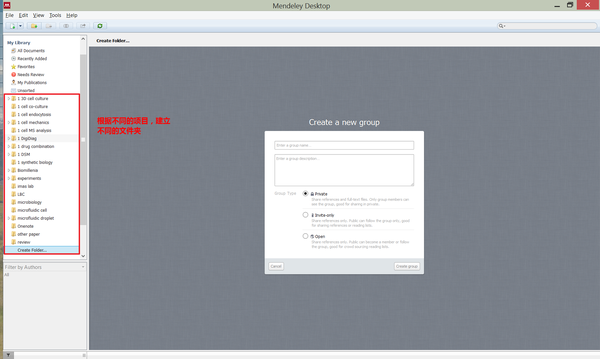
一个项目刚开始的时候,文件夹中没有文献,就需要先建立一份本地的文献原始积累。我习惯在Web of Science上根据关键词去找所需要的文献。
比如我现在想看一下微流控单细胞测序(microfluidic single cell sequencing)最近的进展时,就去WoS搜:
 总共有214篇文献。我会把214篇文献的题目先全部浏览一遍,其中大概100篇需要下载看一下PDF。最后我会剩下大概50篇左右PDF,拖进Mendeley,建立原始的文献积累。Mendeley会自动提取文献信息,按照文献的发表年份,期刊,和文章题目将文献重命名,并将该文献自动整理到指定文件夹中,完成文献的原始积累。
总共有214篇文献。我会把214篇文献的题目先全部浏览一遍,其中大概100篇需要下载看一下PDF。最后我会剩下大概50篇左右PDF,拖进Mendeley,建立原始的文献积累。Mendeley会自动提取文献信息,按照文献的发表年份,期刊,和文章题目将文献重命名,并将该文献自动整理到指定文件夹中,完成文献的原始积累。其他回答中提到了用Endnote。我用Mendeley而不是Endnote做文献索引,主要是因为:Mendeley是我用过所有的文献整理软件中,提取文章题目,发表年份和期刊等信息最准确和方便的软件。看到一篇有意思的文章,我只需要往Mendeley中一拖,它就会帮我自动提取文献信息建立条目,并将文件拷贝到指定文件夹中。其他的软件,要么是提取文献条目的准确度不高,要么就是建立文献条目非常麻烦,需要花大量的时间去建立条目,大大降低文献阅读效率。
我又将这个Mendeley的文件夹中所有文献用dropbox同步。之后我要看文献时,只从这个文件夹中打开文献。这样做的好处就是,把所有的文献和笔记信息全部集中化了,不会造成信息碎片。
做笔记我也只在PDF上做,这样就不用另外开一个软件写笔记,并可以对自己感兴趣的信息直接标注,实现信息最大程度集中化。哪怕打印了纸版的文献,我在看完后也会把纸版上的笔记全部在PDF上标注,避免信息碎片化。
我看一篇文献,除了一些世界上的顶尖超级大牛,一般记不住作者的名字,但是我一般会对文章发表年份和所在期刊有很深的印象。而且一般题目又提供了文章中最主要的信息。所以我设置Mendeley自动根据文献的三个强信息:发表年,发表期刊,和文章题目自动重命名,并结合everything,在本地实现文献的第一重搜索。
如果搜索目标很明确,比如我现在想找一篇之前在Nature Drug Review上看过的关于drug combination的文章,由于关键词很明确,用Everything直接就从本地找到了,耗时不超过3秒。
如果搜索目标不那么明确,比如题主说的,“总感觉有些文献读过就忘记了,想用的时候想不起来”;或者找找一些特定的问题,不确定本地文献有没有。这个时候我一般会把所有能想到的关键词输入,上Google Scholar搜索。
这个时候,可能会找到一些文献在本地是有的,那就可以根据文献名,用Everything快速在本地找到对应的文献。
如果一些文献本地没有,那就直接下载PDF,阅读后在Mendeley建立本地索引。如果想要搜索特定一句话,或者在写文章的时候想对一些说法进行佐证,就可以用Mendeley的搜索工具,
或者还是上Google Scholar。。。**轻整理部分**
之后随着时间的流逝,一个文件夹下的文献慢慢变多,这个时候就需要在Mendeley中建立子文件夹了(对于我来说,每个项目中前前后后需要阅读的文献大概在300篇左右),也就是传统意义上的整理。但是我不赞成把文献归类做的过细。对一个项目下简单分类,使每个子文件夹中的文献大概不超过50篇,再通过发表年份,期刊名,作者名等信息,也可以很容易找到所需的文章了。
但是我现在不会等文献很多了之后再去建立子文件夹,而是会在平时读文献的时候,根据一个项目下的不同问题,建立一些小的分类。在Mendeley中,同一篇文献是可以归属不同的文件夹的,所以在归文件夹的时候也不用那么纠结。
最后,我想说的是,任何文献整理软件都不能代替人对文献的阅读,任何时候读文献中信息永远是第一位的。整理软件只能够帮助更加快速地找到所需的信息而已。
以上。
20150209 更新一些图和词句,使文章逻辑更加清晰。

分享一张我正在做的社会理论思维导图:
软件:Mindnode Pro
————————————正文—————————————————————————————
分享一下我整理文献的心得,我也是在不断摸索中,希望对各位有所启发:系统:MacOS
1. 收集文献:DEVONthink pro
目的:替代 Mac Finder,收集整理文献
功能:上图是我的DEVONthink页面,介绍一下基本功能,
a. 文件可以以相同或者不同的名称储存在同一个或者不同的文件夹;
b. 文件可以进行不同的标记(Label)和标签(Tag),我把标记用来表示重要程度(待读,当下可用,重要等),标签则涵盖核心信息;
c. 文件可以复制(Duplication)和建立替身(Replication),后者对一个替身文件的修改可以实现在所有文件上。我在文件夹中有Chapter3,这是我正在进行中的论文,我将我需要的文章全部替身到这个文件夹里,完成后再把这个文件夹里的替身全部删掉,但是我阅读的修改和标记已经全部在我的文献中保存了;
d. 左下方紫色文件夹为智能文件夹(Smart Group),可以自定义软件中任何一个规则,我仅仅是作为汇集标记的文件夹;
e. 可以将网页截屏为网页格式,或者pdf格式,平常看到有用信息可以立刻保存。
适用半个月,非常方便,还有更多更加细节的功能,这里只是一些最基础功能。
2. 管理文献:Zotero
目的:直接形成参考
优势:a. 可直接拖曳pdf,自动抓取元数据,导入参考信息b. 可输入书号,自动生成参考信息
c. 可安装插件,显示参考数量
补充:原本用Zotero整理文件,所以建立了文件夹,但是在用DEVONthink之后,就放弃在Zotero里继续整理了,通过插件在word中可以很轻松的实现查找和输入。
3. 管理笔记:Circus Ponies Notebook
目的:记录笔记,形成主题,安排提纲
功能:
a. 收集笔记:
a1. 上图是我的笔记本和主题本,按照“作者_年份_名称”命名,前面标“*”号代表需要归纳整理;
a2. 截图是某一篇期刊的内容,我将期刊分为摘要,摘录,总结,分别记各类信息
b. 形成主题:
b1. 上图是我的主题页面,我将所有读过的文献全部整理到了不同的主题之下,以此建立自己知识体系,并且方便以后查看;
b2. 侧面是参考,告知我具体信息从何而来。
c. 安排提纲c1. 上图是我为最近写作的论文安排的提纲页面;
c2. 不同的信息由笔记和主题以及持续的阅读中丰富提纲,基本上提纲建立完成,按照顺序写作也就可以了,侧面仍是“作者_年份”的参考信息。
——————————————————————————————————————————
总结:这是我用来整理文献和收集笔记的三个基本工具,也仅仅介绍了最最基本的功能,希望各位可以从中开发更多功能,养成更符合自己的习惯。
PS 一个小典故:为了发现文本之中隐藏的联系,罗兰.巴特总是会将自己的所有读书卡片完全打乱任意排列,然后在所有这些被打乱、重置的片段中寻找灵感,重新建构文本之间的逻辑。

与其给 PDF 分类,真不如读完文章之后好好整理「读后的 notes」,以后需要什么内容就直接在 notes 里面搜索。notes 记在印象笔记里面就行(虽然印象笔记的搜索功能还处在初级的关键字匹配阶段,但还算够用)。
首先和大家说,我读的是 Computer Science 相关的文献, 不是很清楚其他专业的文献是否可以用同样的方法来整理 notes。不过工科理科专业应该差不多的。OK,现在开始。
*** 1. 需要在 notes 里面清楚的标注文章的 title,作者信息,和会议信息 ***
那么问题来了,应该用什么样的格式来放置这些数据呢?
在这一步推荐使用 dblp(http://dblp.uni-trier.de/),但 dblp 本身并不支持按照文章 title 搜索,所以我们在这里取一个巧,用 Google 里面的「关键字+site:[domain]」功能间接的在 dblp 中按文章 title 搜索。
(如果是非 CS 专业的,也可以通过类似的方法借助 Google 来间接搜索索引类网站,因为这种方法受网站自身内容影响,效果不一定特别好。
注:复制下来的文章标题一定要全+规范,可以提高未来搜索 note 内容时的准确性。)
例如,我们要读一篇名为“eBay in the Sky: Strategy-Proof Wireless Spectrum Auctions”的文献,我们就在 Google 中输入
"eBay in the Sky: Strategy-Proof Wireless Spectrum Auctions site:http://www.informatik.uni-trier.de"进行搜索。我们点击第一个链接便可以看到如下页面,
然后我们直接复制红框当中的内容到印象笔记就OK。这样一来我们便有了准确+规范化的「文章题目,文章作者,以及文章所在会议」*** 2. 总结文章内容 ***
记录好了文章的基本信息,下一步便是阅读文章。
目前(2015年04月),我通过问自己以下几个问题来保证“阅读过程当中思路不跑偏”:
1. What is the problem?
2. Why is the problem interesting?
3. Why is the problem unsolved?
4. What is the authors' idea?
可能有时候会认为:“一篇还比较重要的文章,我就从头到尾一点一点去看,然后看完第一段看第二段,直至看完”。
但其实这样的做法是有点问题的,因为很可能读到中间还不知道这篇文章到底在讲什么。这样就很“致命”。
“致命”是因为,在没有掌握文章的基本逻辑的时候,就很难分辨出什么部分是重点,什么部分不是重点。虽然说文章内容都有其意义,但是意义的重要程度却不尽相同。所以推荐先使用上面四个问题来理顺文章框架,然后再针对感兴趣的内容仔细研读文章。
[精力有限,慢慢一点点的分享给大家喽]
如果大家觉得我写的对整理文献有一点启发,欢迎点赞!等我有空会持续更新 :)
--- ChangeLog 2015-04-25 19:42:11 ---
修改了原来答案当中不通顺的语句


直到遇到org-mode后,我才真正找到完美的文献管理哲学:在论文中管理文献,即在最终的论文中管理文献。那么如何实现呢。
阅读文献的最终目的就将阅读到的重点内容最终反映在自己的论文中。如果可以在论文写作中管理文献,那么在反复阅读与校对论文时,就能随时根据引用的内容来了解该篇参考文献的主题内容等。然而论文中引用文献时,一般的方法也就是在文中给出类似[1]的引用号,文章末尾列入参考文献等内容,真正的交叉引用效果都不太令人满意,那么也就很难将引用内容与参考文献灵活联系起来。但此时如果有一种方法,在不需翻页的情况下,在论文引用处可以链接到引用文档的信息,比如作者,题目,页码,出版社,甚至链接到pdf文档供一键打开,那就是无穷的方便。而org-mode恰巧提供了这样的优势。
用org-mode管理参考文献的优势在于,所有数据都是纯文本,可以任意的修改,可以版本管理,
,也就是说你的任意一次修改都可以被记录并恢复(需要借助git)。并且因为你的数据是纯文本的,所以通过dropbox,google drive同步后,所有的系统平台都可以访问。并且由于emacs elisp的灵活性,org-mode缺失的功能你都可以自己添加,这种软件扩展性也不是其他参考文献管理工具可以比拟的。
更更重要的是,org-mode是免费的!
答案较长,为了便于大家阅读,先给出目录:
1. 独一无二的功能展示
2. 管理参考文献所需基本条件
3. 文献搜寻与添加
3.1 文献条目搜索
3.2 与该条文献相关文献的搜索与添加
4. 参考文献的分类
4.1 利用标题进行分类
4.2 利用标签进行分类
5. 文献重要优先级
6. 如何阅读文献
6.1 分辨已阅读和未阅读
6.2 相似内容文献的链接
6.3 笔记与pdf页码的链接
6.4 文献内容阅读
6.5 导出思维导图
以下为正式回答:
--------------------------------------------------------------------------------------------------------------
1. 独一无二的功能展示
先看下图,这是一篇在org-mode中完成的测试文章,类似在word中完成的完整简单文章。文中蓝色*代表一级标题,黄色*代表二级标题,类似于word的1.和1.1标题。最后的两条link将参考文献文件和其引用样式链接到该文档中,这在后面会介绍。
可以看到文中有可以点击的链接,这其实就是在文章中引用了该篇文献,类似于word中引用的[1],这里只不过是以文献key形式引用,原理是一样的。
cite:rowe-1979-grain
org-mode是纯文本写作,但是可以通过latex,导出为pdf文档(还可以导出到txt,html,reveal.js presentation)。下图为这篇文章的pdf截图,论文的基本架构,引用内容一应俱全,还可以利用org-mode与latex的优势,只关注内容无需在意排版,只需要做的只是写写写!!
以上只是org-mode的冰山一角,下面我详细介绍如何利用org-mode来管理参考文献。
---------------------------------------------------------------------------------------------------------------
2. 管理参考文献所需基本条件:
利用org-mode管理文献时,需要建立两个基本文件。
a. 新建一个参考文献bibtex文件,bibtex的简介和优势参考BibTeX。bibtex文件是由各种类似以下格式的文献条目组成的。这个文献条目包含了一篇参考文献的所有信息。建立好这些文献条目后就可以在文章中引用了,如上所述,minibuffer中显示的内容均来自这个文件。bibtex是文献管理通用格式,并且是纯文本,可以被不同其他文献管理软件导入,也可以从不同软件生成。但我建议每条条目都自己添加,这样格式什么的自己都能控制把握,后面会讲简洁的条目添加方法。
@article{rowe-1979-grain,
author = {R. Grant Rowe},
title = {Grain Boundary Segregation and Grain Growth
Inhibition in Silicon Iron: The Effect of Boron and
Nitrogen},
journal = MTA,
volume = 10,
number = 8,
pages = {997-1011},
year = 1979,
doi = {10.1007/bf02811646},
url = {http://dx.doi.org/10.1007/BF02811646},
}
c. 一个目录用于放置参考文献的pdf文档,然后在以上文件中链接。完成者三个条件之后,就可以在论文中引用,然后点击引用链接,来打开笔记,pdf,url等等内容了。
---------------------------------------------------------------------------------------------------------------
3. 文献搜索与添加
3.1 文献条目搜索
对于搜寻文献,没有比google scholar更方便了,但是对于从google scholar搜寻到的文献条目,我往往不会只简单复制它的cite内容,因为我发现总是数据不齐全。所以我的操作方法就是直接点击进去该条链接,然后打开文献数据库的该条条目页面,从该页面中提取文献信息,这样是最准确的。好吧,当然我是不会一条一条复制的,org-mode提供了更简捷的方法。
开始介绍:网络中搜索文献时,每一个文献链接对应一个数字对象唯一标识符,即doi,参考doi _百度百科。也就是说只要我们找到了这条文献的doi,我们就可以找到它的详细信息。如以搜索Annealing behavior of cold-rolled low-carbon phosphorus-containing steels with variations in silicon content该条文献为例说明。
打开http://dx.doi.org/10.1007/BF02811644会重定向到上面的文献。然后拉到页面底部,找到doi栏,复制10.1007/BF02811644。
然后在org-mode中一条命令即可从doi中获取该文献的参考信息,并自动插入到.bib文件中,然后会自动在笔记文档中建立该文献的条目。如果这篇文献的pdf在网站上是免费提供的,那么这条命令还会自动下载该pdf,并且将其置于pdf目录中。
重点:要知道在网上复制文献的引用信息往往缺少某些内容,而从doi中获得的信息可以说是健壮的。
3.2 与该条文献相关文献的搜索与添加
同时在阅读文献时会有这样的需求,比如我想知道该条文献被引用,引用的文章的list,那么org-mode照样有解决的妙法。
利用org-mode独特的link方法,如下图所示
图中有doi:10.1007/BF02811644的链接,在点击链接后会看到minibuffer处又出现了好多选项,分别是wos, citting articles, related articles, google scholar, CrossRef doi等等。点击不同的选项,实现不同的功能,我依次介绍:
a. wos, 在浏览器中打开该文献在web of science中的位置,Web of Science [v.5.15]
b. citting articles,在浏览器中打开引用的文献列表。 Web of Science [v.5.15]
c. related articles,打开相关文献列表,Web of Science [v.5.15]
d. google scholar,打开在google scholar中的位置。
e. crossrefdoi, 打开在CrossRef中的位置。
好吧,这样搜索参考文献等等是足足的了。
--------------------------------------------------------------------------------------------------------------
4. 参考文献的分类
在.bib文件中对文献条目分类必要性不大,而在org-mode的笔记文件中对文献分类那是再合适不过了。
4.1 利用标题进行分类
下图为部分文献的笔记条目。不同蓝色标题的内容为不同的参考文献条目,这样就以大标题的形式对文献进行了分类。
其实标题是可以折叠的,点击ctrl+tab,以上内容会变成:而其实将所有内容显示后,是这样的:这样显示或者隐藏不同分类的文献,阅读性是不是很强。当然你还可以用 `org-narrow-to-subtree`来隐藏其他所有条目,只剩下该条方便记笔记。4.2 利用标签进行分类
上图右下部分有:@domain_theory:类似字样,这在org-mode中被称为tags。你可以对相同主题的文献进行相同tags,这样在你想至阅读全部文献的某个tags的条目时,只需要点击该tags,如下图所示:
----------------------------------------------------------------------------------------------------------------
5. 文献重要优先级以及排序问题
在阅读文献的过程中,对文献重要性的判断排列很重要,那么怎么利用org-mode对温度进行重要性分级呢。
如图所示为一个文档的条目,注意那个标题中的[#A],意思就是将该文献定位最重要的A级,其余还有B级和C级。对于按照等级对文献进行排序等等,更不是问题。
看到图中文献标题中的年份了吗?然后进行年份排序,那么某标题分类下的文献就按照年份排列下来,年份由于在标题的醒目位置,所以年份什么的,一目了然。再也不用担心忽略这篇文章的出版日期了!
-------------------------------------------------------------------------------------------------------------------------
6. 如何阅读与温习文献
这是管理文献的核心内容,好不容易搜来的文献你不阅读,就让它们一直在那躺尸么。。
6.1 分辨已阅读和未阅读
org-mode用todo和done来标记未阅读和已阅读。在你想下一步阅读某条文献时你还可以添加next,其实添加什么都是自由的,你甚至可以添加killed。
这样文献阅读与否,一目了然。
6.2 相似内容文献的链接
在阅读文献时,往往会遇到互相引用的文献,那么有必要在记录各自文献条目笔记时互相引用下,这样所有相关文献就紧密联系起来了。方法呢,你可以通过以上的cite:rowe-1979-grain,来随时链接相关笔记的内容和pdf,还可以6.3节所说的直接连接pdf至页码,点击一下,就可以找到引用的pdf位置与内容。
同时还可以文献文件内部引用,这样操作就更方便了。
Ctrl-c l
然后移动到需要引用的位置,
Ctrl-c Ctrl-l
6.3 笔记与pdf页码的链接
相信大家在阅读文献做笔记的时候,往往想标记自己所做的笔记来源于文献的哪个部分,或者哪一页。普通的软件的操作流程是,你只能打开pdf,然后根据自己笔记内容翻到那一页,这还是会浪费一些时间的,更何况如果是阅读一本厚厚的pdf专著呢,总不至于每次都狂翻吧?用org-mode呢,可以直接链接到pdf的那一页,如下图所示,点击page1和page5的链接,你就可以直接到达pdf的第一页和第五页。其实这条连接还是可以修改,比如第一页的哪一部分你都是可以添加的,用于提示该页的重要内容。
6.4 文献内容阅读
在org-mode中做笔记时,除了以上各种交叉引用,各种链接之外,还有就是可以做图片笔记。想想在阅读文献时,某一个试料的加工流程,某个结果的数据图往往是文献的核心内容,而用其他工具做笔记时,你不得不打开文档,定位到图片,然后问题内容,而用org-mode后,一个快捷键截图,并显示在你的笔记文件中。以后温习时会省去不少麻烦。示意图如下:
你可以标明这个图在文献的哪个位置,用以上介绍的方法。你可以在caption中说明这个图的重点。
这样你在后面温习的时候甚至有时不用打开pdf了。
当然到这一步哪能完,如果需要在图中进行标注呢,好吧,org-mode配合mspaint.exe再次实现一次快捷键截图加标注功能,效果如下图所示:
此处应该有掌声。。6.5 导出思维导图
org-mode可以导出其他不同格式的内容,今天更新一张参考文献导出到思维导图的图片:
完美导出,母节点子节点导出功能俱全。待续,请期待更加精彩的内容。




2. 通过做presentation加深印象;
3. 最终印到脑子里,达到随时可以给人画草图讲解的地步。
看文献的最终目的是让自己完全记住,同时能清楚的表达给同行,所以从一开始就应当围绕这个目的做笔记。
以下是同一份文献的PPT整理版和草图讲解版。

文献总结整理:Endnote
文献阅读:网页版fulltext
做笔记:Onenote
为什么使用这几个软件?
因为这样最符合我的需求。
我们的需求是什么?
1. 阅读文献的时候:
- 排版舒服容易阅读(网页版和pdf都合适)
- 不懂的内容,即时google(网页版较合适)
- 例如,内容中出现:“xxxxx[11]”。我希望马上看看这个参考文献[11]是什么。pdf版太烦了——要拖下去找这个参考文献[11],然后再滚上来,忘了刚刚看到哪了。这点(大部分文献的)网页版就很好,鼠标虚指一下[11]这个链接,参考文献的citation信息就显示出来,再点一下,直接就可以打开这个参考文献的页面(如图)。
- 在内容中highlight关键部分:IE可用imarkup扩展;firefox可用wired-marker(如图)。高亮记录永不丢失,并可搜索。
- 阅读的同时做笔记:onenote可贴到屏幕右边,记录你的总结和火花。如果使用IE,onenote还可以自动记住你是在阅读原文哪一段时做的这一句笔记。
- 所以,我阅读文献采用网页版,笔记采用onenote。
2. 做文献整理的时候:
我对文献整理软件的唯一需求,就是能快速找到想要的那一篇/几篇文献。想找哪篇找哪篇,忘了关键信息也能找到,模糊检索也能找到。想象以下场景:
- 我想找那篇之前读过的(标记已读/未读功能);
- 2005年发表的(排序功能);
- 分组在"Crystallography"组的(分组功能);
- 曾被我标记了"mTOR"标签的(标签功能);
- 忘了是题目还是内容中含有"pET28a"的(全文内搜索功能)
- 的文献
综上所述,我的选择是网页版阅读+Onenote笔记+Endnote整理。


最近发现bing也有学术了,百度你去死去死吧
界面大致是上面这样一种感觉好的,说到整理文献,用excel整理其实不错
比如说现在要找一下针对一种中药成分有哪些研究,这些研究又一般做些什么实验这样的问题(应该算是一个挺普适的情景了)
那这个表格可以这么设计
#|文章题目|实验对象|体内/体外|建模方式|分组|观察指标
然后根据文献内容往里面填空就好了
这样子会看的很有目的性,看文献会很快,然后也很容易对比,整合ps:图片是我瞎弄的。吐槽一下,沉香这东西还能治病么?嘛,TCM博大精深非我等俗人可以理解
2015-7-18 更新
关于引文下载的两个更新:
1. 虽然百度可以去死去死,不过国内的网络环境百度学术还是一个比较靠谱的选择
http://xueshu.baidu.com
用过google scholar 的话用百度学术是没问题的,基本上界面都差不多,引用那里也可以下载各种文献管理可以识别的文件
2. pubmed是可以直接下载引文的,居然最近才发现……
选中要下引文的文献,send to,下面选择citation manager。下载的文件endnote亲测可以打开如果进入一个文献条目以后也可以send to
3. 写综述,写discussion经常会参照别人引用的文献来进行引用。一般 作者名 + 杂志名 + 年代在百度学术或者google scholar都能搜到。偶尔搜不到的话加上标题里面的一些词也行。
书籍的引文资料往往不是很全,经常会有明明全部都是从网上下载好了引文数据,但是引文格式还是不符合要求的情况。一般来说出问题的都是对于书摘的引用
---
想起来就加一点:看到很多人推荐onenote,都是记笔记的软件,比起07版的时代现在的onenote好用很多很多了,ios和mac上的也是免费的,和evernote相比各有千秋吧,知乎里面另外有题目讨论这个
OneNote 和 Evernote 应如何取舍? - 互联网
个人最开始用的是07版的onenote,因为同步功能不行所以改用evernote,现在虽然发现onenote在这一块进步了很多,但是也懒得切换回去了。想花花绿绿的话,evernote有一个sketch组件可以试试
----------------------
断断续续也看了很多文献了,虽然没发过几篇文章,不过各种文献整理的办法都用到过,试试分享一下自己的经验吧。
因为题主主要是问以前看过的文献后面想用的时候怎么避免找不到,我就主要从这一块答吧。
先直接说我现在最喜欢用的,那就是evernote
对啊,这个软件只能记笔记,虽然可以在pdf上做标记,不过无论是mac上的还是windows下面的都感觉怪怪的,不如acrobat自己的高亮功能好用,而且最重要最重要的是不能作为引文系统,为什么要推荐呢?
第一点,你看文献,找文献,总要靠网页浏览器吧,evernote在chrome上面有插件,按一下·,就是1左边的那个按键就可以把当前页做成笔记了,这个尤其在你觉得当前这个摘要挺有意思,应该用得着,但是一时间又搞不到全文的时候非常好用。否则你怎么保存?把网页存下来然后在文件名里面注明为什么要存这篇文章?还是用evernote抓下当前页面,然后你可以在题目,在内容,在tag里面想怎么标注就怎么标注。
pdf也可以用evernote存,有的时候pdf是直接在chrome里面打开了,这个时侯也是用·键记录,但是不推荐这么干就是了,最好先存到硬盘,然后再把pdf转存到evernote里面。(有的时候虽然pdf全文都能显示,但是evernote就是抓不进去,回头你再想下载是件很郁闷的事情)
第二点,当你回头要找文献的时候,你就知道evernote有多好用了。话说回来我用的是premium版的,不知道普通版能不能搜pdf里面的内容。就算不能搜索,你只需要在pdf文件外面的笔记里面好好注明,回头都不怕找不到的。
不要想着依靠evernote里面的笔记本做归类,那就和用文件夹给pdf做归类一样不靠谱
tag是一个办法,但是你能保证从头到尾都用一致的tag么,你能保证前列腺癌不标成PCa,不标成prostate cancer,pst Cancer么。tag是很重要的,能加的话尽量加,但是只能作为辅助
其实标记文献说到底就是怎么用最短的语句说明白这篇文献对自己有什么用,不过这个也不好办,因为毕竟初看文献也不大清楚嘛,但是这篇文献里面你觉得特别的,在别的地方不见得能重复出现的,一定要写下来
烂大街的结论,就算这篇文献你回头找不到了,还可以去google scholar搜,一抓一大把
但是这篇文献特有的,特别的,那真的是不见得就能在其他文献上看到了,自己文献库里面找不到那你就只能回去网上重新找了。
哦,然后如果自己的文献库里面怎么也找不到你以前存过的那篇文献的话,最好还是上网找。一来搜索引擎的算法怎么都比你自己的搜索方式要好,二来很可能你当时根本就没存过那篇文献。
-----------------------
加一点:evernote在看文献上面的优势也是杠杠的,全平台支持,免费版也可以下pdf来看。当然了,如果要标注的话还是怪怪的。
以前用过papers这个文献管理软件,后来直接弃了,因为它的搜索真就一个坑爹啊,虽然这个软件整合了引文功能,但是你能有endnote好用么?不能啊,你的windows版本有D版吗,没有啊,关键你能在手机上看文献么?不越狱不行啊。对了,好像这货还没有安卓版。所以还是算了,虽然界面很酷炫,功能很强大,但是不适合就是不适合。
虽然题主没问过引文管理(就是弄了一大堆文献然后往word里面插插插,插完以后按个键自动把[1],[2],[3]和后面的reference都给你做好的这个功能),我也顺便说一下吧。
我的方案是google scholar+endnote
endnote自己也可以检索,不过没有google scholar好用
搜索界面
点一下引用然后点endnote就可以下载引文数据了。国内文章投稿的话直接把gb/t那个拷贝出来放到word里面自己写引文都可以了,前提是引文数量不多,文章也写的差不多不用改了。一般来说还是endnote格式把文献数据放到endnote里面,以后就你想怎么折腾都行了啦


本文原文发布在简书:http://www.jianshu.com/p/6bf14803dc99
文献无疑是目前科研成果的最主要载体。在大家坚持不懈地灌水努力下,现在的文献是越来越多,大有涛涛江河汇成大海之势。然而,怎样才能在大海里畅游而不迷失方向?怎样才能在海里钓到大鱼呢?今天我就来介绍一下我个人的经验。
1. Readcube——最好的文献管理器
Readcube是近乎完美的文献管理器,如果没有墙而你又是付费用户的话,它会更完美。
文献管理器是阅读和管理文献的核心,因而选择一款好用的文献管理器十分重要。目前主流的选择包括ReadCube, Mendeley和Endnote。根据笔者自己的实际使用体验,这几种文献管理软件中最好的是Readcube。无论从美观程度、功能性、平台覆盖面上都有碾压其他软件的势头,缺点是略微有点卡顿。下面我来具体介绍一下它的主要功能和特色。
Enhanced PDF——PDF文件自动识别和强化
目前几乎所有的文献都是以PDF格式存在,对PDF文件的处理方式和识别能力直接决定了一款文献管理软件的好坏,而ReadCube的杀手锏正是PDF自动识别。
当我们从期刊网站或者课题组主页上下载了某篇文件的PDF文件之后,通过Readcube的导入按钮,将文献拖动到Readcube界面或者直接定位到文献所在文件夹,就可以将PDF文件批量导入Readcube。一旦导入,Readcube就会自动识别文献的具体信息。识别成功的文献会在软件界面右侧显示文献的信息,包括期刊、编号、标题、作者、摘要等等。甚至会显示该文献的引用量。这样,你的文献就不再只是以PDF文件的形式存在,而是以信息完备,分类详细的数据库的形式存在。管理将更为方便。你还可以选择将数据库中的文献自动按照作者、发表时间或者标题进行重命名,重新保存到指定文件夹中。
点击阅读按钮,我们可以打开增强后的PDF文件。文献中的所有作者姓名和参考文献的引用上标都变成了可以点击的状态,点击之后,可以直接跳转到该引用文献的下载界面或者作者主页。而右侧的一系列选项卡除了提供了参考文献列表以外,还提供了很多非常有用的功能。比如Metrics选项卡,以图表形式给出了该文献的引用数随时间的变化。下方给出了具体的引用文献,直接点击就可以下载。它甚至还能给出其他引用文献引用该文献时的具体描述。这一功能简直是科研工作者做梦都想要的功能。当我们找到一篇我们感兴趣的重要文献时,只需要结合ReadCube提供的引用和被引用文献列表,就能够非常迅速的勾勒出一个文献网络,一旦在这个网络中发现其他感兴趣的文献,只需要一次点击(在你的学校购买了相关数据库的情况下),ReadCube就能够自动帮你从学校代理连接到期刊网站,甚至能自动帮你下载好,放入你的数据库。理想情况下,全程不需要任何额外操作。文献查找和下载的效率得到了极大的提升。
Files选项卡给出了PDF文件在电脑中储存的位置,更重要的是,如果该文献有Supporting Information,即使你没有下载,Readcube也能够在这个选项卡中显示,点击后就可以直接下载。而Cite选项卡则让你能够导出文献各种格式的引用,方便在Word、PPT等软件中插入。
Recommendations——推荐功能
Readcube另一个核心功能是自动化推荐,它能够根据你文件库中已有的文献自动计算出你感兴趣的文献,推荐给你,同样只需要简单点击就可以下载。而且它可以根据你导入文献时创建的文件夹,针对性地推荐某一特定类别和特定时间段的文献给你。这样你就不需要费时费力地到网上检索了。
All Platforms——全平台特性
相对于其他文献管理软件,Readcube的全平台同步特性非常强大。它几乎覆盖所有平台,包括Web、PC、Mac、iPad、Android等等。而且在各个平台上,Readcube的使用体验几乎一致,功能性并没有损失。在网页版上,Readcube还能够自动列出文献中的图片和图片标注,方便在阅读文献时定位到提及的图片。
Readcube Web Importor——Chrome插件Readcube Web Importor是Readcube新出的Chrome插件,付费用户才能使用。通常,文献需要将PDF文件下载下来,再导入软件中才能够进行管理,这个插件通过在浏览器中提供入口,将这一过程进一步简化。当你打开Google Scholar或者Pubmed的时候,它会在页面中的每个搜索结果后面直接加上一个按钮,点击以后可以直接将结果加入Readcube数据库。而点击插件栏上的按钮,插件将自动识别搜索结果中的文献,你可以通过勾选你感兴趣的结果,将文献直接批量加入Readcube数据库中。这样,你连下载PDF的时间都省了。
关于付费功能
Readcube的全平台同步和Metrics功能是需要购买按年付费的高级版的,高级版还提供一个付费功能是监控特定文件夹,有新文件后自动导入。新用户可以获得3个月高级版的免费试用,推荐十个人使用Readcube的话还可以获得一年高级版。Readcube高级版的正常价格是55美金一年,但是黑色星期五之类的促销季会打折。至于值不值,各位自己衡量啦。
2. Google图片——进行直观的发散式搜索很少有人会喜欢阅读满屏幕的英文,尤其当这些英文中还夹杂着很多字典也查不出来的专业词汇的时候。但是图片却不一样。优秀的学术文章大多会有简洁美观的示意图。通常情况下,看到这些图片,你就能够大致明白文献的主题。人脑的强大之处在于形象思维和抽象能力。通常情况下,人们更能够从满屏幕的图片而不是满屏幕的文字中发现相关信息。从这一点出发,我自创了一种快速查找文献的方法,那就是利用Google图片。Google图片搜索的优良算法能够很好的将相关或者近似领域的搜索结果显示到一起。而且针对单一图片,能够进一步展示类似图片。并且,相对于其他搜索引擎,我个人感觉,Google给予学术结果的权重更大。
下面我们以Self-assembly为例,来看看怎么利用Google图片搜索学术资料。
我们可以看到搜索结果基本都是简洁明了的学术文献的示意图。大部分图片我们不需要看注释文字就可以大致猜出它要表示的内容。点击排在前面的一幅图片,这幅图片来自nature网站,图片标题下方给出了图片的文字描述,我们可以根据描述进一步理解图片表达的意思。而文字描述下方,Related images给出了类似的其他图片,我们不需要离开当前页面就可以进一步查看。而点击View More,我们就可以查找和当前图片相关的其他图片,注意,这时候新的搜索是以图片为基础,而不需要输入关键词,也就是说Google可以根据你感兴趣的图片自动帮你联想关键词。这样你就不要煞费脑汁的去思考用什么英文单词来搜索了。
这一系列看似简单的功能,实际上使得我们能够以一两个关键词为出发点,极其方便的构建一个庞大的搜索网络,而整个过程中,所有结果都是以图片形式呈现,你甚至不需要输入文字,只需要点击鼠标就行了。你所有的注意力只需要集中到对图片想要表达意思的抽象判断上。这无疑让查找文献的过程变得极为高效和简化。
相关插件搜索结果图片中,前面的一排方形文字是安装了Chrome谷歌搜索优化插件之后显示的关键词进一步精确化的建议,它能将原来网页搜索结果上方的搜索建议进一步细化,并且以更美观的形式呈现出来,同时以相同颜色表示相同类别的关键词,方便识别。
同时推荐安装Power Zoom图片放大插件,按下Ctrl键,鼠标移过图片的同时可显示该图片的全尺寸放大图。
3. 文献订阅自从被Google抛弃之后,RSS订阅服务似乎渐趋没落,使用者越来越少。但是由于科研领域的特殊性,RSS在科研领域还是有它的用武之地,尤其是在文献推荐方面。这里,我介绍两个新颖的RSS文献推荐和订阅服务。
一览阅读——新时代的最佳RSS阅读器之一作为一款本土应用,一览是一个令人欣慰的存在。它界面简洁美观,提供瀑布流式的浏览方式。而且它自带颇为丰富的订阅源,除了可以订阅专业学术期刊网站外,还可以订阅很多泛科学领域的知名网站,如知乎、果壳等。可以说是目前国内RSS阅读器最好的选择之一。
SciReader
SciReader
是专注于学术领域的免费文献个性化推荐服务。它的主页面提供三个基本功能,一个是根据你设置的关键词和兴趣领域推荐相关的最新文献给你,可以自动发送到你的邮箱,第二个是在tweeter上讨论最多的文献,第三个是来自Science Daily上的学术新闻。见面美观简洁,功能实用,是一个值得考虑的服务。
4. 浏览器插件
除了独立的网站和软件之外,有一些优秀的浏览器插件也能够给我们的学术生活带来很大便利。
Wiki2 or WikiwandWiki2 和 Wikiwand 都是维基百科美化和功能增强插件。维基百科是目前最为庞大的网络百科全书,储藏了海量的知识,但是界面却略显简陋。这两个插件的主要作用是给维基百科穿上漂亮的衣服,同时提供链接预览、页面收藏等增强功能。两者的界面风格几乎是两个极端。Wikiwand是灰白色调为主的现代风格,提供平板和手机客户端,而Wiki2非常绚丽多彩,并且,Wiki2在每个维基页面还集成了Youtube搜索功能,能自动在维基百科页面中插入相关的Youtube视频。笔者个人更喜欢Wiki2。萝卜白菜各有所爱,各位自己选择一个更顺眼的吧。
Google学术搜索按钮
这个插件是谷歌公司官方出品的,功能非常实用。当你打开某个期刊的文献页面的时候,点击这个插件的按钮,它能够自动显示页面中文献的谷歌学术搜索结果。如果有免费的PDF提供,就会有一个绿色按钮,点击即可免费下载文献,不需要你的学校购买相关的数据库。点击引号还可以直接输出参考文献的引用,非常方便。
5. 写在后面
必要的硬件升级
如果你的电脑还用着2G内存和机械硬盘,那么这篇文章其实对你不会有太大帮助。因为相对于优秀软件带来的便利,更多的时候,你得忍受令人不悦的卡顿。如果你无法保持一个愉悦的心情,效率的提升就无从谈起。我强烈推荐你升级到8G以上内存,并且至少将系统盘换成SSD。即使你的老板很抠门,需要你自己掏这笔钱(500元以内)。
另外,如果你需要经常码字,我推荐你给自己装备一个机械键盘,它能让你爱上打字的感觉。
大部分好的软件是免费的,但是它们的增值服务是收费的。这也是绝大部分优秀软件公司的生存方式。中国用户在使用这些软件的时候,很少考虑购买增值服务。也有一些即使有购买的意愿,也会受到支付渠道的限制。虽然不是每个人都需要增值服务,但是我希望当你真的需要的时候,不要犹豫。
我写过一些相关文章,推荐给大家:



回头上个界面截图。
我的NoteExpress界面:
临时下了个Skitch,用得不熟,随便涂了涂,凑合看吧。。。
PS,马上毕业了,就要远离科研了,以后可能再也不用NE了,竟然感觉自己的使用经验特别可惜。。。
PPS.:平时很容易陷入捣鼓软件的时间黑洞无法抽离 /大哭,也很热衷于分享些微捣鼓所得。所以,欢迎交流 ~^_^~
~~~~~~~~~~~~~~~~~~~
再补几张图吧。
我认为用好NoteExpress的一个关键在于,你要习惯先导入题录再导入附件的flow。或者可以这样理解:你先完善了一篇文章(可以狭义理解为pdf文件)的“ID”信息,然后让NE帮你把这篇文章的pdf文件放到对应的位置去。
Step 01:在文献数据库网站找到“export citation”选项,导出题录文件,一般都是支持导出为EndNote格式的,选择这个就可以了,NE是可以识别的。此处示例为ScienceDirect,其他数据库类似。
Step 02:NE界面,Ctrl+M键,打开导入题录对话框,选择刚刚下载的题录文件,选择对应的过滤器(偶尔会出现过滤器不正确的情况,可以多试试其他过滤器;话唠一句,其实题录文件可以用Notepad打开,很容易就可以明白过滤器或者题录文件的格式只是指定了不同字段对应的题头标记)。这样就可以导入题录到NE了。Step 03:导入附件。ScienceDirect下载的附件文件通常是一堆字符,别担心,NE可以帮你自动重命名。(注意设置项的最后一行。其他选项,我比较建议的是移动附件要勾选。可以自己弄个三五篇文献的NE数据库随便倒腾,直到明白区别在哪儿。)下图是自动重命名的效果。同时可以看到题录前面多了个红色的小方块,这是该题录有对应附件的标记。粉色的小方块表示该题录有对应的笔记(参见前面的截图)。Step 04:来个预览吧。在细节里可以更改题录细节;左上方的锁标记,不妨自己试试看是什么功能哦。“笔记”选项卡标出了字母“N”,所以Alt+N键即可快速切换到笔记选项卡;其他同理。
到这里就可以愉快地做文件笔记啦。基本这样。
Ctrl+Shift+1/2/3/4/5分别可以快速设置当前选中文章的优先级为低~高。
Ctrl+T可以快速打开当前选中文章的标签对话框。
NE同样可以满足EndNote在Word文档里管理参考文献列表的功能,摸索摸索就熟了。
另外,我在上手NE的过程中,还用过的一些功能包括:无法添加NE选项卡到Word的手动解决方案、通过更改字段实现批量更改题录类型、批量自动更新完善题录信息、批量附件链接修复、手动修改/定义某一期刊的参考文献样式。暂时先想到这些,如果你能看明白这些问题,热烈欢迎交流哈 ~^_^~
实践是王道!先找10篇左右的文章,建立一个数据库,随意折腾,把一些感觉可能会用到的功能都试过来,也就熟了。学习成本是有的,不过学完之后生产力是会提高不少的,尤其是对于要在科研界三年以上的筒子 ~^_^~
PS:我的NE数据库,包括题录文件和附件全都是保存在云盘(金山快盘)上的,两台电脑之间保持同步。很好用。
PPS:知乎回答的格式编辑起来不太容易,或许是我太low本来就没答过几题。。。有些截图截的时候没太在意,就这样吧,可能会有相关我本人的信息,请不要肆意人肉。。。对大家有帮助,我就很开心啦,哈哈~