整体单改
路由层、模型层、序列化层不需要做修改,只需要处理视图层:views.py
"""
1) 单整体改,说明前台要提供修改的数据,那么数据就需要校验,校验的数据应该在实例化“序列化类对象”时,赋值给data
2)修改,就必须明确被修改的模型类对象,并在实例化“序列化类对象”时,赋值给instance
3)整体修改,所有校验规则有required=True的字段,都必须提供,因为在实例化“序列化类对象”时,参数partial默认为False
注:如果partial值设置为True,就是可以局部改
1)单整体修改,一般用put请求:
V2BookModelSerializer(
instance=要被更新的对象,
data=用来更新的数据,
partial=默认False,必须的字段全部参与校验
)
2)单局部修改,一般用patch请求:
V2BookModelSerializer(
instance=要被更新的对象,
data=用来更新的数据,
partial=设置True,必须的字段都变为选填字段
)
注:partial设置True的本质就是使字段 required=True 校验规则失效
views.py.实现改的操作
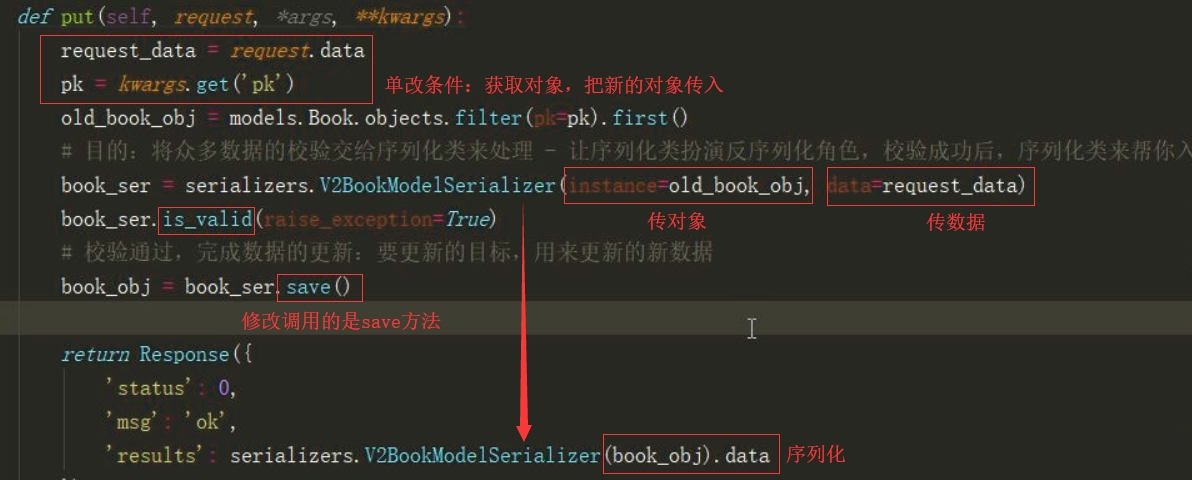
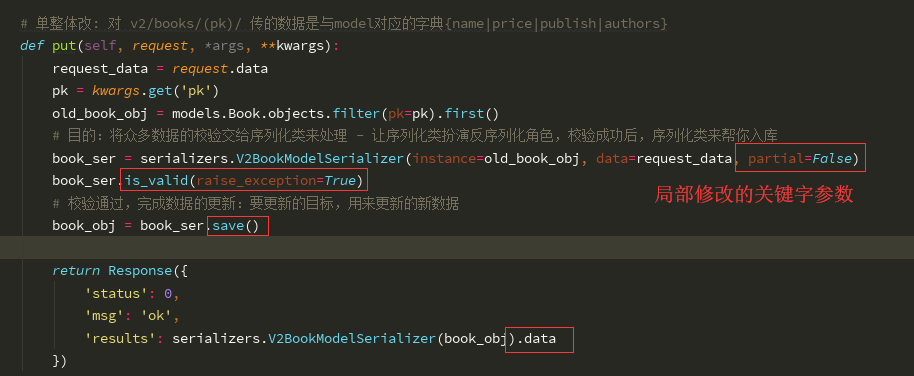
class V2Book(APIView): # 单整体改: 对 v2/books/(pk)/ 传的数据是与model对应的字典{name|price|publish|authors} def put(self, request, *args, **kwargs): request_data = request.data pk = kwargs.get('pk') old_book_obj = models.Book.objects.filter(pk=pk).first() # 目的:将众多数据的校验交给序列化类来处理 - 让序列化类扮演反序列化角色,校验成功后,序列化类来帮你入库 book_ser = serializers.V2BookModelSerializer(instance=old_book_obj, data=request_data, partial=False) book_ser.is_valid(raise_exception=True) # 校验通过,完成数据的更新:要更新的目标,用来更新的新数据 book_obj = book_ser.save() return Response({ 'status': 0, 'msg': 'ok', 'results': serializers.V2BookModelSerializer(book_obj).data })
解析内部源码分析put.save方法
内部源码listSerialiaer类没有书写update方法

报错原因

单与整的局部修改
序列化层:serializers.py
# 重点:ListSerializer与ModelSerializer建立关联的是: # ModelSerializer的Meta类的 - list_serializer_class class V2BookListSerializer(ListSerializer): def update(self, instance, validated_data): # print(instance) # 要更新的对象们 # print(validated_data) # 更新的对象对应的数据们 # print(self.child) # 服务的模型序列化类 - V2BookModelSerializer for index, obj in enumerate(instance): self.child.update(obj, validated_data[index]) return instance # 原模型序列化类变化 class V2BookModelSerializer(ModelSerializer): class Meta: # ... # 群改,需要设置 自定义ListSerializer,重写群改的 update 方法 list_serializer_class = V2BookListSerializer # ...
视图层:views.py
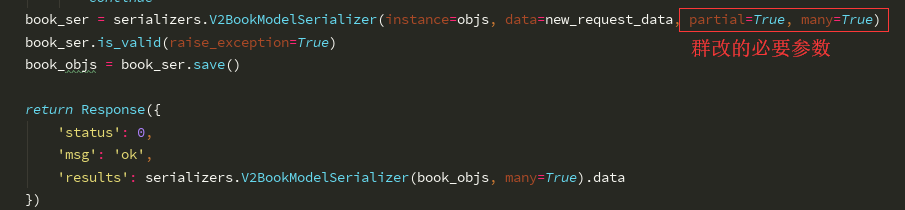
class V2Book(APIView): # 单局部改:对 v2/books/(pk)/ 传的数据,数据字段key都是选填 # 群局部改:对 v2/books/ # 请求数据 - [{pk:1, name:123}, {pk:3, price:7}, {pk:7, publish:2}] def patch(self, request, *args, **kwargs): request_data = request.data pk = kwargs.get('pk') # 将单改,群改的数据都格式化成 pks=[要需要的对象主键标识] | request_data=[每个要修改的对象对应的修改数据] if pk and isinstance(request_data, dict): # 单改 pks = [pk, ] request_data = [request_data, ] elif not pk and isinstance(request_data, list): # 群改 pks = [] for dic in request_data: # 遍历前台数据[{pk:1, name:123}, {pk:3, price:7}, {pk:7, publish:2}],拿一个个字典 pk = dic.pop('pk', None) if pk: pks.append(pk) else: return Response({ 'status': 1, 'msg': '数据有误', }) else: return Response({ 'status': 1, 'msg': '数据有误', }) # pks与request_data数据筛选, # 1)将pks中的没有对应数据的pk与数据已删除的pk移除,request_data对应索引位上的数据也移除 # 2)将合理的pks转换为 objs objs = [] new_request_data = [] for index, pk in enumerate(pks): try: # pk对应的数据合理,将合理的对象存储 obj = models.Book.objects.get(pk=pk) objs.append(obj) # 对应索引的数据就需要保存下来 new_request_data.append(request_data[index]) except: # 重点:反面教程 - pk对应的数据有误,将对应索引的data中request_data中移除 # index = pks.index(pk) # request_data.pop(index) continue book_ser = serializers.V2BookModelSerializer(instance=objs, data=new_request_data, partial=True, many=True) book_ser.is_valid(raise_exception=True) book_objs = book_ser.save() return Response({ 'status': 0, 'msg': 'ok', 'results': serializers.V2BookModelSerializer(book_objs, many=True).data })
单改-局部修改
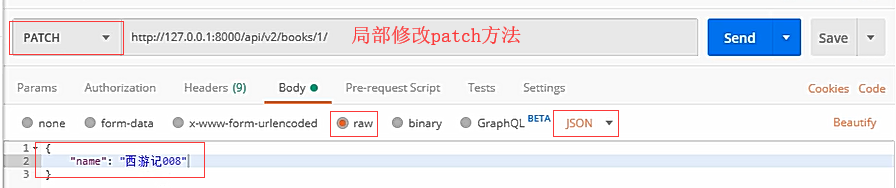
postman测试
群改的实现