一 什么是字符编码
计算机要想工作必须通电,即用‘电’驱使计算机干活,也就是说‘电’的特性决定了计算机的特性。电的特性即高低电平(人类从逻辑上将二进制数1对应高电平,二进制数0对应低电平),关于磁盘的磁特性也是同样的道理。结论:计算机只认识数字 很明显,我们平时在使用计算机时,用的都是人类能读懂的字符(用高级语言编程的结果也无非是在文件内写了一堆字符),如何能让计算机读懂人类的字符? 必须经过一个过程: #字符--------(翻译过程)------->数字 #这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
二 以下两个场景下涉及到字符编码的问题:
#1、一个python文件中的内容是由一堆字符组成的,存取均涉及到字符编码问题(python文件并未执行,前两个阶段均属于该范畴)
#2、python中的数据类型字符串是由一串字符组成的(python文件执行时,即第三个阶段)
三 字符编码的发展史与分类(了解)
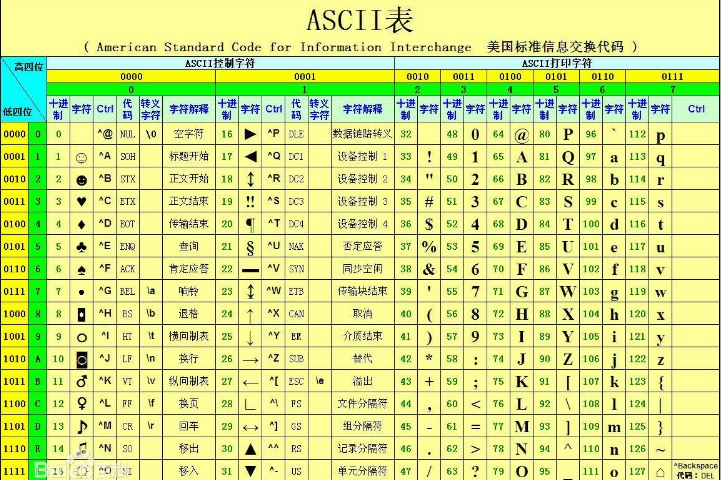
计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系。最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号
#阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII
ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符
ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符),后来为了将拉丁文也编码进了ASCII表,将最高位也占用了
#阶段二:为了满足中文和英文,中国人定制了GBK
GBK:2Bytes代表一个中文字符,1Bytes表示一个英文字符
为了满足其他国家,各个国家纷纷定制了自己的编码
日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里
#阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。如何解决这个问题呢???
#!!!!!!!!!!!!非常重要!!!!!!!!!!!!
说白了乱码问题的本质就是不统一,如果我们能统一全世界,规定全世界只能使用一种文字符号,然后统一使用一种编码,那么乱码问题将不复存在,
ps:就像当年秦始皇统一中国一样,书同文车同轨,所有的麻烦事全部解决
很明显,上述的假设是不可能成立的。很多地方或老的系统、应用软件仍会采用各种各样的编码,这是历史遗留问题。于是我们必须找出一种解决方案或者说编码方案,需要同时满足:
#1、能够兼容万国字符
#2、与全世界所有的字符编码都有映射关系,这样就可以转换成任意国家的字符编码
这就是unicode(定长), 统一用2Bytes代表一个字符, 虽然2**16-1=65535,但unicode却可以存放100w+个字符,因为unicode存放了与其他编码的映射关系,准确地说unicode并不是一种严格意义上的字符编码表,下载pdf来查看unicode的详情:
链接:https://pan.baidu.com/s/1dEV3RYp
很明显对于通篇都是英文的文本来说,unicode的式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的)
于是产生了UTF-8(可变长,全称Unicode Transformation Format),对英文字符只用1Bytes表示,对中文字符用3Bytes,对其他生僻字用更多的Bytes去存
#总结:内存中统一采用unicode,浪费空间来换取可以转换成任意编码(不乱码),硬盘可以采用各种编码,如utf-8,保证存放于硬盘或者基于网络传输的数据量很小,提高传输效率与稳定性。
字符编码必须统一,不然编译会以报错或提示乱码形式提示
首先明确概念
#1、文件从内存刷到硬盘的操作简称存文件
#2、文件从硬盘读到内存的操作简称读文件
乱码的两种情况:
#乱码一:存文件时就已经乱码
存文件时,由于文件内有各个国家的文字,我们单以shiftjis去存,
本质上其他国家的文字由于在shiftjis中没有找到对应关系而导致存储失败
但当我们硬要存的时候,编辑并不会报错(难道你的编码错误,编辑器这个软件就跟着崩溃了吗???),但毫无疑问,不能存而硬存,肯定是乱存了,即存文件阶段就已经发生乱码
而当我们用shiftjis打开文件时,日文可以正常显示,而中文则乱码了
#用open模拟编辑器的过程
可以用open函数的write可以测试,f=open('a.txt','w',encodig='shift_jis'
f.write('你瞅啥\n何を見て\n') #'你瞅啥'因为在shiftjis中没有找到对应关系而无法保存成功,只存'何を見て\n'可以成功
#以任何编码打开文件a.txt都会出现其余两个无法正常显示的问题
f=open('a.txt','wb')
f.write('何を見て\n'.encode('shift_jis'))
f.write('你愁啥\n'.encode('gbk'))
f.write('你愁啥\n'.encode('utf-8'))
f.close()
三、python2与python3字符串类型的区别
在python2中有两种字符串类型str和unicode
str类型:
当python解释器执行到产生字符串的代码时(例如x='上'),会申请新的内存地址,然后将'上'编码成文件开头指定的编码格式
要想看x在内存中的真实格式,可以将其放入列表中再打印,而不要直接打印,因为直接print()会自动转换编码
#coding:gbk
x='上'
y='下'
print([x,y]) #['\xc9\xcf', '\xcf\xc2']
#\x代表16进制,此处是c9cf总共4位16进制数,一个16进制四4个比特位,4个16进制数则是16个比特位,即2个Bytes,这就证明了按照gbk编码中文用2Bytes
print(type(x),type(y)) #(<type 'str'>, <type 'str'>)
unicode类型:
当python解释器执行到产生字符串的代码时(例如s=u'林'),会申请新的内存地址,然后将'林'以unicode的格式存放到新的内存空间中,所以s只能encode,不能decode
转换在字符前加u‘,Windows默认的编码是“gbk”格式,而pycharm默认的是--**--Unicode--**--utf-8格式,编码如果不统一,解码时就会显示乱码,或者会报错,保证不乱码的前提是编码要统一,不 然就进行强制转换
#coding:gbk
x=u'上' #等同于 x='上'.decode('gbk')
y=u'下' #等同于 y='下'.decode('gbk')
print([x,y]) #[u'\u4e0a', u'\u4e0b']
print(type(x),type(y)) #(<type 'unicode'>, <type 'unicode'>)
二 在python3 中也有两种字符串类型str和bytes
str是unicode
#coding:gbk
x='上' #当程序执行时,无需加u,'上'也会被以unicode形式保存新的内存空间中,
print(type(x)) #<class 'str'>
#x可以直接encode成任意编码格式
print(x.encode('gbk')) #b'\xc9\xcf'
print(type(x.encode('gbk'))) #<class 'bytes'>
很重要的一点是:看到python3中x.encode('gbk') 的结果\xc9\xcf正是python2中的str类型的值,而在python3是bytes类型,在python2中则是str类型
三、文件处理:
计算机系统分为:计算机硬件,操作系统,应用程序三部分。
我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程:
二 在python中
#1. 打开文件,得到文件句柄并赋值给一个变量
1 f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r
2
3 #2. 通过句柄对文件进行操作
4 data=f.read()
5
6 #3. 关闭文件
7 f.close()
文件的操作:读、写、修改、添加(f.read、f.close、f.open、f.(with.open)要定义打开的模式不然默认为 mode='r' 后面跟 os f )# r取消转义
格式例如:
1 with open(r'E:\PY\venv\01.txt',mode='r',encoding='utf-8') as f:
示例1:
1 1 f=ope(file=’C:\Windows.txt‘,mode='r'.encoding='utf-8')
2 2 data=f.read()
3 3 f.close()
上述就是一个打开文本文件的一系列操作:获取文件>>>打开文件>>>关闭文件的过程
# mode='r' 表示只读(也可以选择为其他模式)
#encoding='utf-8' 表示将硬盘的01010101按照utf-8的规则去编码
#f.read() 表示读取要获取的内容,内容已经转换完毕
f.close # 表示关闭文件
示例2:
1 1 f=ope(file=’C:\Windows.txt‘,mode='rb')# mode='rb' 表示只读(也可以选择为其他模式)
2 2 data=f.read()
3 3 f.close()
示列1和示例2的区别在于对文件操作时没有定义“encoding='utf-8'”字符码格式。这样获取的文件内容就会不一样
强调第一点:
打开一个文件包含两部分资源:操作系统级打开的文件+应用程序的变量。在操作完毕一个文件时,必须把与该文件的这两部分资源一个不落地回收,回收方法为: 1、f.close() #回收操作系统级打开的文件 2、del f #回收应用程序级的变量 其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源, 而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close() 虽然我这么说,但是很多同学还是会很不要脸地忘记f.close(),对于这些不长脑子的同学,我们推荐傻瓜式操作方式:使用with关键字来帮我们管理上下文 with open('a.txt','w') as f: pass with open('a.txt','r') as read_f,open('b.txt','w') as write_f: data=read_f.read() write_f.write(data)
#强调第二点:
f=open(...)是由操作系统打开文件,那么如果我们没有为open指定编码,那么打开文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。
这就用到了上节课讲的字符编码的知识:若要保证不乱码,文件以什么方式存的,就要以什么方式打开。
f=open('a.txt','r',encoding='utf-8')

二 打开文件的模式
文件句柄 = open('文件路径', '模式')
1 #1. 打开文件的模式有(默认为文本模式):
2 r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
3 w,只写模式【不可读;不存在则创建;存在则清空内容】
4 a, 之追加写模式【不可读;不存在则创建;存在则只追加内容】
5
6 #2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式)
7 rb
8 wb
9 ab
10 注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
11
12 #3. 了解部分
13 "+" 表示可以同时读写某个文件
14 r+, 读写【可读,可写】
15 w+,写读【可读,可写】
16 a+, 写读【可读,可写】
17
18
19 x, 只写模式【不可读;不存在则创建,存在则报错】
20 x+ ,写读【可读,可写】
21 xb
三 、操作文件的方法
注意:文件操作时,以“w”或“wb”模式打开,则只能写,并且在打开的同时会先将内容清空(’f.write‘:文件不存在时会自动创建新的文件,文件存在的时候会自动清除内容,谨慎使用)
文件的追加: f.write 默认添加在尾部
文件的读写,打开关闭模式:
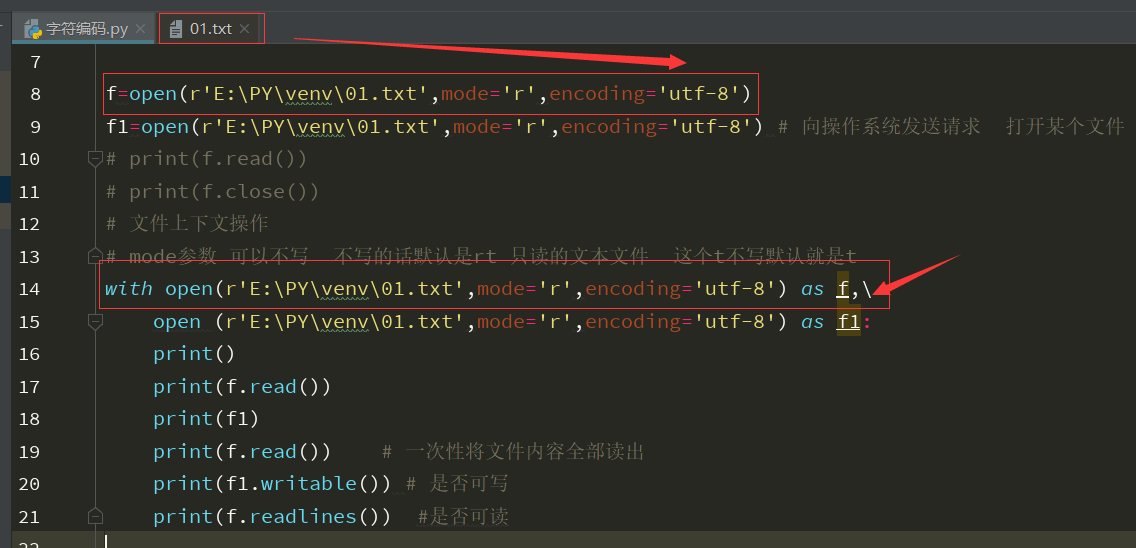
上述代码执行的结果:# readlinse()输出的结果是一个列表
常用的文件操作方法:
1 #掌握
2 f.read() #读取所有内容,光标移动到文件末尾
3 f.readline() #读取一行内容,光标移动到第二行首部
4 f.readlines() #读取每一行内容,存放于列表中
5
6 f.write('1111\n222\n') #针对文本模式的写,需要自己写换行符
7 f.write('1111\n222\n'.encode('utf-8')) #针对b模式的写,需要自己写换行符
8 f.writelines(['333\n','444\n']) #文件模式
9 f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式
10
11 #了解
12 f.readable() #文件是否可读
13 f.writable() #文件是否可读
14 f.closed #文件是否关闭
15 f.encoding #如果文件打开模式为b,则没有该属性
16 f.flush() #立刻将文件内容从内存刷到硬盘
17 f.name
四 文件内光标移动
一: read(3):
1. 文件打开方式为文本模式时,代表读取3个字符
2. 文件打开方式为b模式时,代表读取3个字节
二: 其余的文件内光标移动都是以字节为单位如seek,tell,truncate(截断)
注意:
1. seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
2. truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果
1 with open (r'E:\PY\venv\01.txt',encoding='utf-8',mode='r') as f: # 在rt模式下 read内的数字 表示的是字符的个数 2 print(f.read(11)) 3 with open(r'E:\PY\venv\01.txt', encoding='utf-8', mode='rb') as f: 4 ser=f.read(11) # rb 模式读取的是字节数 不用‘encoding='utf-8'’ 5 print(ser) 6 # print(ser.decode('utf-8')) 7 # f.seek(offset.whence) 8 # offset:相对偏移量,光标的移动位数 9 # whence:'0,1,2' 10 # 0:参照文件的开头 t和b 都可以使用 11 # 1:参照光标所在的当前位置 只能在b模式下用 12 # 2: 参照文件末尾 只能在b模式下使用
# 在rt模式下 read内的数字 表示的是字符的个数,除此之外的都是字节('r','rt','rb')
with open (r'E:\PY\venv\01.txt',mode='rb') as f: 不需要转成 encoding='utf-8' print(f.read(1)) set=f.seek(6,0) # 一个文字对应3个字节,一个英文对应一个字节 print(set) print(f.seek(6,0)) #rb模式下的都是移动字节数,出了r模式外 print(f.seek(0,0)) print(f.read(1)) print(f.read(9)) print(f.seek(9,0)) print(f.read(3)) print(f.seek(0,0)) print(f.read())
末尾开始往后读取字4个节数:
# with open(r'test','rb') as f:
# print(f.read())
# f.seek(-4,2)
# print(f.read().decode('utf-8'))
文件的添加:
with open(r'test','r+',encoding='utf-8') as f:
# f.seek(3,0)
# f.write('过')
五 文件的修改:
修改文件
1.先将数据由硬盘读到内存(读文件)
2.在内存中完成修改(字符串的替换)
3.再覆盖原来的内容(写文件)
with open(r'test02.txt','w',encoding='utf-8') as f: res = data.replace('egon','jason') # 直接替换 print(data) f.write(res)
优点:任意时间硬盘上只有一个文件 不会占用过多硬盘空间
缺点:当文件过大的情况下,可能会造成内存溢出
文件修改方式2
# 创建一个新文件
# 循环读取老文件内容到内存进行修改 将修改好的内容写到新文件中
# 将老文件删除 将新文件的名字改成老文件名
import os with open(r'test02.txt','r',encoding='utf-8') as read_f,\ open(r'test02.swap','a',encoding='utf-8') as write_f: for line in read_f: new_line = line.replace('jason','egon') write_f.write(new_line) ## 添加新内容 os.remove('test02.txt') os.rename('test02.swap','test02.txt') ## 重命名
优点:内存中始终只有一行内容 不占内存
缺点:再某一时刻硬盘上会同时存在两个文件
两种修改方式:f.replace f.write,利用for循环
import os with open (r'E:\PY\venv\01.txt',mode='r',encoding='utf-8')as f: setr=f.read() print(setr) print(type(setr)) with open (r'E:\PY\venv\01.txt',mode='w',encoding='utf-8') as f: date=setr.replace('一杯','两杯') print(setr) print(f.write(date))
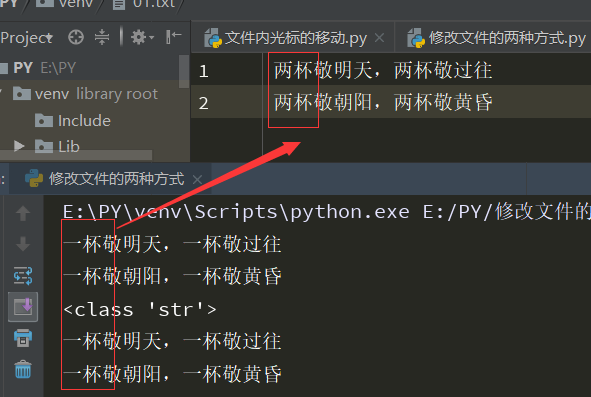
1 import os 2 3 with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f: 4 data=read_f.read() #全部读入内存,如果文件很大,会很卡 5 data=data.replace('alex','SB') #在内存中完成修改 6 7 write_f.write(data) #一次性写入新文件 8 9 os.remove('a.txt') 10 os.rename('.a.txt.swap','a.txt')