由于自己平时喜欢在b站看看番剧、学习视频之类的,恰好这段时间等了好几年的Re0 season2开始更新了,打算将视频全部保存到本地,于是打开pycharm开始干活…
- 下载非大会员视频,最高1080p画质
- 使用多线程下载加快下载速度
- 鉴于本地网络环境不佳、考虑加入断点续传功能
- 支持终端^c退出
b站的视频信息全部保存在网页源码中的window.__playinfo__变量中,其实就是个json格式的字符串, 所以我们用正则表达式很容易提取出来,如下图:
获得视频播放地址后如果直接在浏览器中请求服务器会返回403 Forbidden,打开开发者模式发现b站的请求方式为option,所以我们也照着这样去申请服务器资源。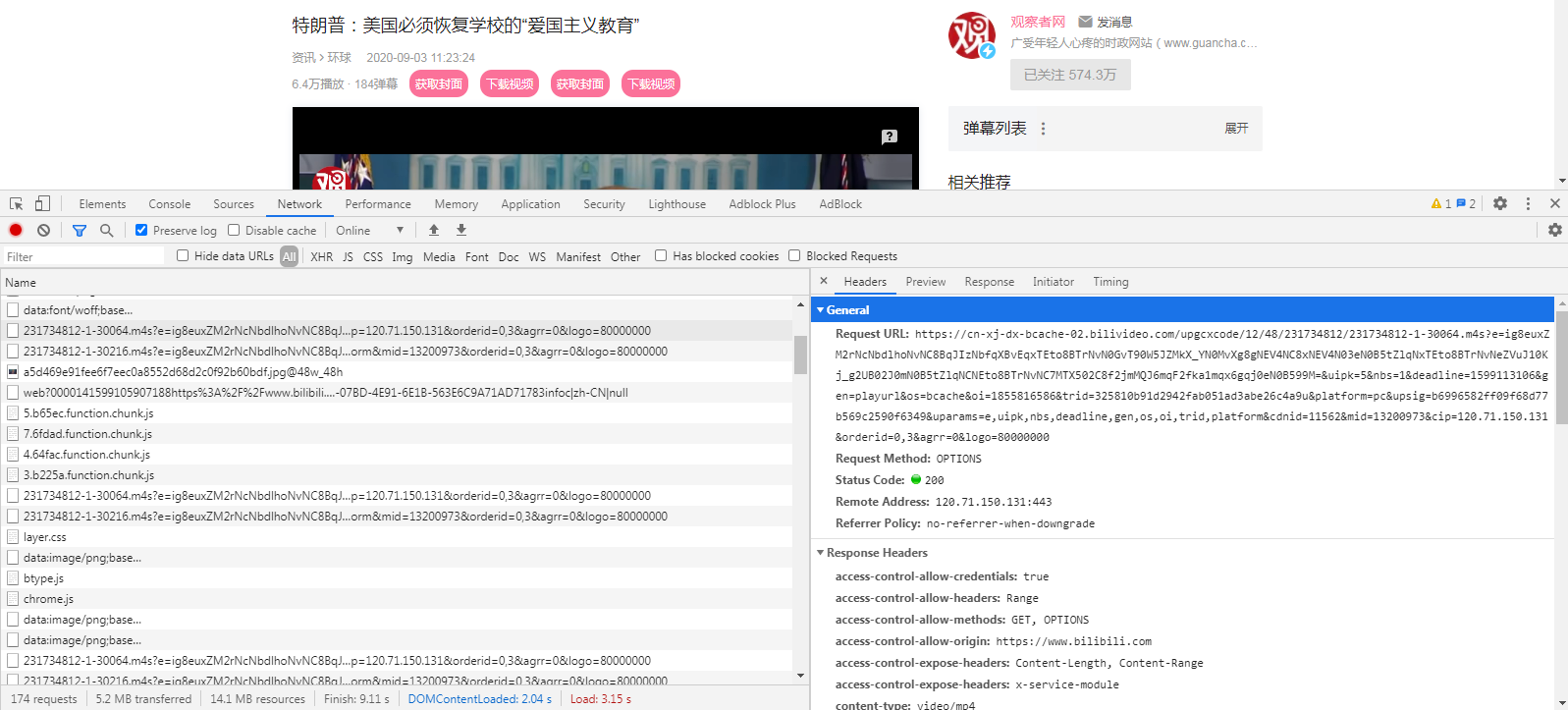
注意我们写脚本去爬取视频的时候需要填入自己的cookie,否则有些视频无法获取,当然如果你有大会员也可以下载大会员专属视频。
补充一点:b站视频都是视频流和音频流分开存储的,所以将视频和音频下载完了之后,最后用 ffmpeg合并视频、音频。
三、编码细节
为了支持断点续传、我们需要记录每次请求头中的'Range': 'bytes=xx-yy'其中xx,yy为我们自定义的请求范围。所以我们再写个日志类用于记录请求信息,使用json格式保存到本地,方便操作。
为了实现ctrl-c结束程序,使用signal模块捕获signal.SIGINT signal.SIGTERM即ctrl-c信号、终端信号,用全局变量is_exit控制线程是否退出,当程序接收到信号时is_exit设置为True线程退出。注意线程创建start之后不要jion方法阻塞,我们轮询的方式判断thread_list[i].is_alive(),如果所以线程运行完毕,程序就正常向下执行。
如果程序因为网络故障某个线程退出之后,其他线程并未设置退出,继续进行下载,直到下载完成或报错为止。
四、具体实现
"""
===================================
-*- coding:utf-8 -*-
Author :GadyPu
E_mail :Gadypy@gmail.com
Time :2020/9/3 0003 上午 11:44
FileName :bili_downloader.py
===================================
"""
import sys
import signal
import requests
import time
import math
import os
import json
import re
import threading
import copy
from lxml import etree
from decimal import Decimal
requests.packages.urllib3.disable_warnings()
is_exit = False
class Logger(object):
def __init__(self, *args):
if len(args) == 1:
with open(os.path.join(os.getcwd(), args[0] + '.log'), 'r', encoding = 'utf-8') as rf:
self.log_file = json.loads(rf.read())
else:
self.log_file = {
'time': None,
'filename': args[0],
'filesize': args[1],
'downsize': 0,
'url': args[2],
'threads': []
}
for i in range(args[3]):
self.log_file['threads'].append({
'start': 0,
'end': 0,
'finshed': False
})
self.lock = threading.Lock()
def update_log(self, start, end, id, step, finshed = False):
with self.lock:
self.log_file['threads'][id]['start'] = start
self.log_file['threads'][id]['end'] = end
self.log_file['downsize'] += step
if finshed:
self.log_file['threads'][id]['finshed'] = True
def load_bound(self):
with self.lock:
return copy.deepcopy(self.log_file['threads'])
def get_cur_size(self):
with self.lock:
return int(self.log_file['downsize'])
def get_tot_size(self):
with self.lock:
return int(self.log_file['filesize'])
def get_file_name(self):
with self.lock:
return self.log_file['filename']
def get_req_url(self):
with self.lock:
return self.log_file['url']
def save_log(self):
with self.lock:
self.log_file['time'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
file_path = os.path.join(os.getcwd(), self.log_file['filename'] + '.log')
with open(file_path, 'w+', encoding = 'utf-8') as wf:
wf.write(json.dumps(self.log_file))
def failed(self):
with self.lock:
for i in self.log_file['threads']:
if not i['finshed']:
return True
return False
def show_log(self):
print(self.log_file)
def clear(self):
file_path = os.path.join(os.getcwd(), self.log_file['filename'] + '.log')
if os.path.exists(file_path):
os.remove(file_path)
class DownThread(threading.Thread):
def __init__(self, headers: dict, log: Logger, id: int, start, end, url, session):
super().__init__()
self.headers = copy.deepcopy(headers)
self.file_name = log.get_file_name()
self.thread_id = id
self.log = log
self.__start = start
self.__end = end
self.url = url
self.session = session
def run(self):
fp = open(self.file_name, 'rb+')
__start, __end = self.__start, self.__end
__step = 1024 * 512
finshed = True
b_read = 0
print(f'thread[{self.thread_id}] 开始下载 Range:{__start}-{__end}')
t1 = time.time()
i, tm = 0, (__end - __start + 1) // __step + 1
while __start <= __end:
__to = __end if __start + __step > __end else __start + __step
self.headers.update({'Range': 'bytes=' + str(__start) + '-' + str(__to)})
try:
res = self.session.get(url = self.url, headers = self.headers, verify = False, timeout = 5)
if res.status_code in [200, 206]:
fp.seek(__start)
fp.tell()
fp.write(res.content)
#print(f'thread[{self.thread_id}] 正在下载 Range:{__start}-{__to}')
print('
thread[{}] 正在下载{:^3.0f}%'.format(self.thread_id, (i / tm) * 100), end = '')
i += 1
b_read += len(res.content)
#self.log.update_log(__start, __end, self.thread_id, len(res.content))
if is_exit:
print('
', f'接收到^c信号 thread[{self.thread_id}]退出')
self.log.update_log(__start, __end, self.thread_id, b_read)
finshed = False
break
except Exception as e:
print(e)
print('
', f'thread[{self.thread_id}]:网络错误请重新下载')
self.log.update_log(__start, __end, self.thread_id, b_read)
finshed = False
break
__start = __to + 1
if finshed:
print('
', f'thread[{self.thread_id}]->下载完成 花费:{round(time.time() - t1, 2)}s')
self.log.update_log(__start - 1, __end, self.thread_id, b_read, True)
fp.close()
class DownBilibili(object):
def __init__(self, url, thread_num, path, sesdata):
self.headers = {
'Cookie': "SESSDATA=96b2608a%2C1617615923%2C7e662*a1;",
'origin': 'https://www.bilibili.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
}
self.url = url
self.pat_src = r'window.__playinfo__=(.*?)</script>'
self.pat_tit = r'<title.*>(.*?)</title>'
self.pat_inf = r'window.__INITIAL_STATE__=(.*?)</script>'
self.video_url = ''
self.audio_url = ''
self.titles = ''
self.sesdata = sesdata
self.thread_num = thread_num
self.log = None
self.out_put = []
if path != '':
os.chdir(path)
def get_file_size(self, e: int) -> str:
if e <= 0:
return ''
t = ["B", "KB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB"]
n = math.floor(math.log2(e) / math.log2(1024))
return str(Decimal(e / math.pow(1024, n)).quantize(Decimal("0.00"))) + t[n]
def get_video_info(self):
try:
self.headers.update({'Referer': self.url})
if self.sesdata:
self.headers.update({'Cookie': self.sesdata})
resp = requests.get(url = self.url, headers = self.headers, verify = False)
self.titles = re.findall(self.pat_tit, resp.text)[0].split('_')[0]
except Exception as err:
print(err, '
无法获取视频信息请重试')
return False
try:
info_json = json.loads(re.findall(self.pat_src, resp.text)[0])
self.video_url = info_json['data']['dash']['video'][0]['baseUrl']
self.audio_url = info_json['data']['dash']['audio'][0]['baseUrl']
except:
bv_info = json.loads(re.findall(self.pat_inf, resp.text)[0].split(';')[0])
ep_id = self.url.split('/')[-1]
ep_id = ep_id[2:] if ep_id.startswith('ep') else ''
vip_api = f"https://api.bilibili.com/pgc/player/web/playurl?cid={bv_info['epList'][0]['cid']}&bvid={bv_info['epList'][0]['bvid']}&ep_id={ep_id}&fnval=80"
info_json = requests.get(url = vip_api, headers = self.headers, verify = False).json()
if info_json['message'] != 'success':
print('大会员专属视频,请填入SESSDATA后重试!')
return False
self.video_url = info_json['result']['dash']['video'][0]['baseUrl']
self.audio_url = info_json['result']['dash']['audio'][0]['baseUrl']
return True
def get_download_size(self, src_url):
try:
session = requests.session()
self.headers.update({'referer': self.url})
session.options(url = src_url, headers = self.headers, verify = False)
self.headers.update({'Range': 'bytes=' + str(0) + '-' + str(1024)})
res = session.get(url = src_url, headers = self.headers, verify = False)
size = int(res.headers['Content-Range'].split('/')[1])
return size, session
except Exception:
print('无法获取服务器资源请重试')
return -1, None
def handler(self, signum, frame):
global is_exit
is_exit = True
def assigned_tasks(self, size: int, log_exit: bool, src_url: str, session):
step = size // self.thread_num
thread_list = []
if log_exit:
bound = self.log.load_bound()
for i in range(self.thread_num):
__session = copy.copy(session)
if log_exit:
__x, __y = bound[i]['start'], bound[i]['end']
# if __x == __y:
# continue
t = DownThread(self.headers, self.log, i, __x, __y, src_url, __session)
else:
start = 0 if not i else end + 1
end = start + step if i != self.thread_num - 1 else size - 1
t = DownThread(self.headers, self.log, i, start, end, src_url, __session)
t.setDaemon(True)
t.start()
thread_list.append(t)
#[_.join() for _ in thread_list]
signal.signal(signal.SIGINT, self.handler)
signal.signal(signal.SIGTERM, self.handler)
while True:
alive = False
for i in range(self.thread_num):
alive |= thread_list[i].is_alive()
if not alive:
break
time.sleep(0.5)
def download(self, src_url, file_name):
global is_exit
is_exit = False
size, session = self.get_download_size(src_url)
if size == -1:
print('无法获取服务器资源请重试')
return False
log_exit = os.path.exists(os.path.join(os.getcwd(), file_name + '.log'))
if log_exit:
self.log = Logger(file_name)
if not self.log.failed():
return True
cur = self.log.get_cur_size()
url = self.log.get_req_url()
print(f'继续上次下载进度[已下载:{self.get_file_size(cur)} {round(cur / size * 100, 2)}%]', url)
print('开始重新下载')
else:
print(f'开始下载【{file_name}】、文件大小为{self.get_file_size(size)}')
self.log = Logger(file_name, size, src_url, self.thread_num)
with open(file_name, 'wb') as fp:
fp.truncate(size)
self.assigned_tasks(size, log_exit, src_url, session)
self.log.save_log()
if self.log.failed():
return False
return True
def work(self):
res = self.get_video_info()
if not res:
print('无法获取视频下载链接请重试')
return None
self.titles = re.sub('[/:*?"<>|]', '-' , self.titles)
self.out_put = [self.titles + '-video_out.m4s', self.titles + '-audio_out.m4s']
for i in range(2):
if not i:
finshed = self.download(self.video_url, self.out_put[i])
else:
finshed = self.download(self.audio_url, self.out_put[i])
if not finshed:
print(f'【{self.out_put[i]}】' + '下载失败请重试')
return None
self.merge()
print('Done!')
def merge(self):
print('开始合并视频音频文件')
os.popen('ffmpeg -i ' + f'"{self.out_put[0]}"' + ' -i ' + f'"{self.out_put[1]}"' + ' -codec copy ' + f'"{self.titles}.mp4"').read()
print('合并完成开始删除缓存文件')
[os.remove(os.path.join(os.getcwd(), i)) for i in self.out_put]
[os.remove(os.path.join(os.getcwd(), i + '.log')) for i in self.out_put]
def print_usage():
print('''usage: bili_downloader [OPTION]...
A simple tools for download bilibili videos.
Support ctrl-c cancel task and restart task.
You can run it by command line arguments.
download options:
-b bilibili videos id. eg: 'BV1J5411b7XQ'
-t download threads number, default 4
-d the path that you want to save videos, default current dir path
-s input your cookies, eg: 'SESSDATA=xx' to get the vip videos
-h show this help message and exit
ps: If you need to download a member video please enter your 'SESSDATA', otherwise you'd better not do that.
Refer: <https://www.cnblogs.com/GadyPu/>
''')
if __name__ == '__main__':
url = 'https://www.bilibili.com/video/'
args = sys.argv
length = len(args)
if length == 1:
print_usage()
else:
kwargs = {
'bv': '',
'num': 4,
'path': '',
'sesdata': ''
}
if '-b' in args:
id = args.index('-b')
if id != length - 1:
bv = args[id + 1]
kwargs['bv'] = bv
if bv.startswith('ss') or bv.startswith('ep'):
url = 'https://www.bilibili.com/bangumi/play/'
if '-h' in args:
print_usage()
sys.exit()
if '-t' in args:
id = args.index('-t')
if id != length - 1:
num = int(args[id + 1])
kwargs['num'] = num
if '-d' in args:
id = args.index('-d')
if id != length - 1 and os.path.exists(args[id + 1]):
kwargs['path'] = args[id + 1]
if '-s' in args:
id = args.index('-s')
if id != length - 1:
sesdata = args[id + 1]
kwargs['sesdata'] = sesdata
if kwargs['bv'] == '':
print_usage()
sys.exit()
d = DownBilibili(url + kwargs['bv'], kwargs['num'], kwargs['path'], kwargs['sesdata'])
d.work()
如果出现:“[WinError 10048] 通常每个套接字地址(协议/网络地址/端口)只允许使用一次“,关闭终端重新打开终端再运行程序即可。
本人没有大会员所以某些番剧不能第一时间观看,所以又在互联网上找了其它网站,简单分析了一下他的视频存储方式保存在m3u8文件里,具体实现如下,支持断点续传,有兴趣的小伙伴可以看一下(此网站需要自备梯子)
"""
===================================
-*- coding:utf-8 -*-
Author :GadyPu
E_mail :Gadypy@gmail.com
Time :2020/8/22 0022 下午 01:41
FileName :fetch_video.py
===================================
"""
import os
import re
import sys
import time
import requests
import urllib.parse
import threading
from queue import Queue
import warnings
warnings.filterwarnings("ignore")
class FetchVideos(object):
def __init__(self, url):
self.url = url
self.m3u8_url = None
self.que = Queue()
self.headers = {
'Referer': url,
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36',
'Connection': 'close'
}
self.is_write = False
self.lock = threading.Lock()
self.m4s_headers_url = None
self.m4s_headers_bytes = b''
self.pat = r'mac_url=unescape((.*))'
self.download_failed_lists = []#'faild.txt'
def unescape(self, _str):
_str = urllib.parse.unquote(_str)
return re.sub(r'%u([a-fA-F0-9]{4}|[a-fA-F0-9]{2})', lambda m: chr(int(m.group(1), 16)), _str)
def get_m3u8_url(self):
try:
response = requests.get(url = self.url, headers = self.headers, verify = False)
res = re.findall(self.pat, response.text)[0]
res = self.unescape(res).split(r"'")[1].split('#')[-1]
self.m3u8_url = res[res.find('$') + 1:]
print('the m3u8 url is:' + self.m3u8_url)
except:
print('cannot get the m3u8_url...')
sys.exit()
def get_m4s_headers(self):
try:
response = requests.get(url = self.m4s_headers_url, headers = self.headers, verify = False)
self.m4s_headers_bytes = response.content
except:
print('cannot get m4s headers...')
sys.exit()
def init_ts_url(self):
page = 1
try:
response = requests.get(url = self.m3u8_url, headers = self.headers, verify = False)
api_url = self.m3u8_url[: self.m3u8_url.rfind('/') + 1]
time.sleep(0.5)
resp = requests.get(url = api_url + response.text.split('
')[2], headers = self.headers, verify = False)
print(resp.url)
for i in resp.text.split('
'):
if i.endswith('.m4s'):
self.que.put((page, api_url + i))
page += 1
elif i.startswith('#EXT-X-MAP:URI='):
self.m4s_headers_url = api_url + i.split('#EXT-X-MAP:URI=')[1].split('"')[1]
print(self.m4s_headers_url)
print(f'total {self.que.qsize()} files to be downloading...')
except:
print('cannot get m4s_url_lists...')
sys.exit()
def download_ts_thread(self, path):
while not self.que.empty():
d = self.que.get()
try:
resp = requests.get(url = d[1], headers = self.headers,
verify = False, stream = True, timeout = 6)
if resp.status_code == 200:
file_path = os.path.join(path, f'{d[0]}.m4s')
content = b''
for data in resp.iter_content(1024):
if data:
content += data
with open(file_path, 'wb') as wf:
wf.write(self.m4s_headers_bytes + content)
print(f'{d[0]}.m4s is download complished...')
time.sleep(0.2)
else:
print(f'the {d[0]}.m4s download failed...')
with self.lock:
self.download_failed_lists.append(d)
except:
print(f'the {d[0]}.m4s download failed...')
if not self.is_write:
with open('header.bin', 'wb') as wf:
wf.write(self.m4s_headers_bytes)
self.is_write = True
with self.lock:
self.download_failed_lists.append(d)
def merge_ts_files(self, filename):
print('start merging...')
dir = os.getcwd() + r'downloadvideos'
merge_txt = [_ for _ in os.listdir(dir)]
merge_txt.sort(key = lambda x: int(x.split('.')[0]))
src = ''
first = True
for i in merge_txt:
if first:
src = i
first = False
else:
src = src + '+' + i
os.chdir(dir)
os.system('copy /b ' + src + f' {filename}.mp4')
print('video merge completed...')
def down_faild(self, lists: list):
for i in lists:
if i:
d = i.split(' ')
self.que.put((d[0], d[1]))
#print(d)
with open('header.bin', 'rb') as rf:
self.m4s_headers_bytes = rf.read()
def remove_temp_files(self):
path_text = os.path.join(os.getcwd(), 'failed.txt')
path_bin = os.path.join(os.getcwd(), 'header.bin')
if os.path.exists(path_text):
os.remove(path_text)
if os.path.exists(path_bin):
os.remove(path_bin)
def run(self):
failed = False
self.get_m3u8_url()
with open('failed.txt', 'a+') as rf:
rf.seek(0)
lists = rf.read()
if len(lists) > 1 and lists.split('
')[0][:86] == self.m3u8_url[:86]:
lists = lists.split('
')
self.down_faild(lists[1:])
failed = True
else:
self.init_ts_url()
self.get_m4s_headers()
down_path = os.getcwd() + r'downloadvideos'
if not os.path.exists(down_path):
os.makedirs(down_path)
if not failed:
[os.remove(os.path.join(down_path, i)) for i in os.listdir(down_path)]
thred_list = []
print('start downloading...')
for i in range(3):
t = threading.Thread(target = self.download_ts_thread, args = (down_path, ))
t.setDaemon(True)
thred_list.append(t)
t.start()
[t.join() for t in thred_list]
if not len(self.download_failed_lists):
self.remove_temp_files()
self.merge_ts_files(self.m3u8_url.split('/')[4])
else:
with open('failed.txt', 'w+', encoding = 'utf-8') as wf:
wf.write(self.m3u8_url + '
')
[wf.write(str(i[0]) + ' ' + i[1] + '
') for i in self.download_failed_lists]
print(f'total {len(self.download_failed_lists)} files download failed...')
if __name__ == '__main__':
#Re0 season2 ep9
url = 'https://www.olevod.com/?m=vod-play-id-19657-src-1-num-9.html'
d = FetchVideos(url = url)
d.run()
五、运行效果
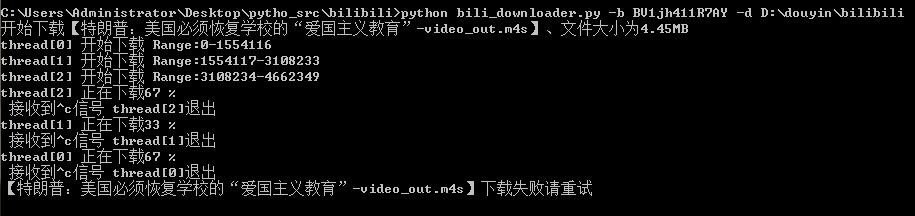
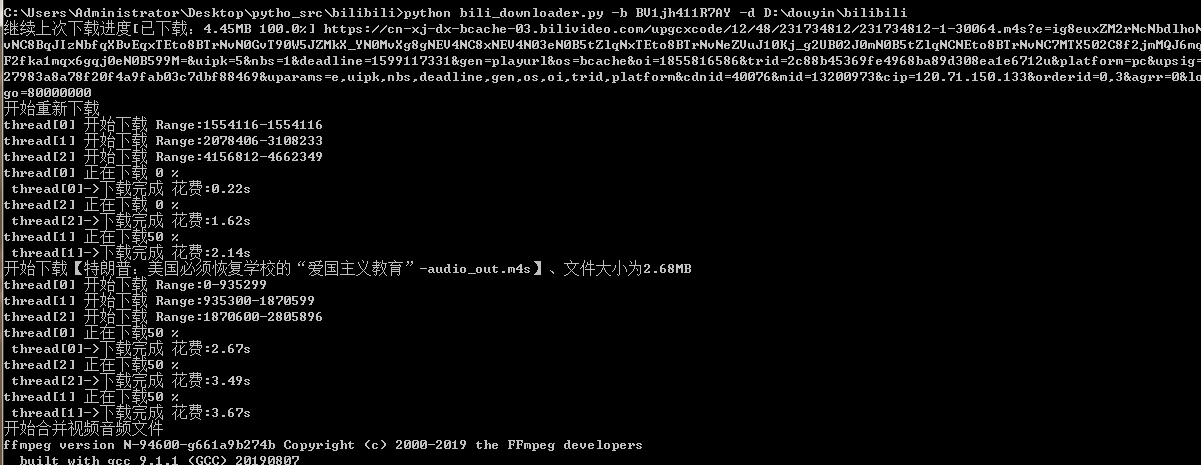
1、https://www.cnblogs.com/W-Y-C/p/13406392.html
2、https://www.cnblogs.com/yuanyb/p/12296815.html
3、https://blog.csdn.net/weixin_43107613/article/details/104754426
七、更新日志
- 2020.10.13 如果有大会员可以下载仅大会员可见的视频,默认最高画质,填入相应'SESSDATA'即可