本人并没有真正接触过信息论,对信息熵也只能算是道听途说,但是基于对《信号与系统》这个学科的兴趣和理解力,本人惊叹信息熵的实用性,经常以理论指引的方式用于物理理论的理解和算法的通俗化思考。比如,本人写过的《压缩算法引申》。信息熵可以称得上伟大的论著,对很多领域的现象都能给予很好的概括性论述。
信息熵的直观理解
要理解信息熵,其实并不难,因为生活中无处不是信息熵的体现。比如,假设你是一个伪球迷,对各国家足球队实力一点都不了解,问你冠军赛两支队伍谁可能夺冠。首先经过你脑海的是,这两家国家队可能实力相当,用概率学的说法,即两支球队夺冠的概率都是50%,那么结果就像是掷硬币,正反靠天时地利人和,并无从考证——我们设定这种情景为A。这个时候,有个人跑过来和你说,他是一个足球评论员,对各足球对非常了解,然后告诉你此次冠军赛实力相差悬殊,德国队近来年表现优秀,主帅勒夫策略非凡,而另外一支队伍已经有很多届未进入世界杯总决赛了;基于这些不完整信息,作为伪球迷的你,心理肯定给德国队夺冠加分,假设这个时候你心理的夺冠概率变成了德国队80%的夺冠率,而另一支队伍只剩20%的夺冠率——我们设定这种情景为A+。我们知道,比赛的结果只有一个,冠军也只有一支队伍。结果出来了,有人跑过来准备跟你说到底谁夺冠了,如果你只是在A情境下,这个夺冠信息对你肯定很有诱惑力,因为你本来就无法判断谁可能夺冠;如果你是在A+情境下,这个夺冠信息对你来说多少有点失去新鲜,因为世界级的赛事,出差错的可能性不高,所以你会觉得你其实已经大概知道了结果,听或不听没有太大意义。换种说法表述,晚上冠军赛开战,如果你身处情景A,你肯定比较好奇,势均力敌的双方到底谁能夺冠;而如果你身处情景A+,你会觉得这是一场结果已定的赛事,没有太大兴趣。
好的,举了这么一个例子,你应该已经开始恍然了,信息会改变你对事物的未知度和好奇心,信息量越大,你对事物越了解,进而你对事物的好奇心也会降低,因为你对事物的确定性越高。至此,为了抽象这个模型,聪明的香农总结出了信息熵这个概念。信息熵用以表示一个事物的非确定性,如果该事物的非确定性越高,你的好奇心越重,该事物的信息熵就越高。我们先抛出信息熵的公式
为什么是这个表达式,我们慢慢表述。
信息熵和热力学熵
对于熵(Entropy)的理解,学术讨论早就已经上升到哲学的范畴,我们只是从最基本的角度去直观地理解这个概念。熵来源于热力学,是由鲁道夫·克劳修斯提出的,用来表示任何一种能量在空间中分布的混乱程度,能量分布得越混乱,熵就越大。一个体系的能量达到完全均匀分布时,这个系统的熵就达到最大值。 怎么直观地理解这个定义呢?比如一个热力学体系内,有一个冰块和一杯热水,二者在独立的情况下,冰块和热水内部的分子状态是有差别的,冰块是固态,分子主要是有限振动,而热水中分子快速做布朗运动。也就说,在这个热力学系统中,有两个队伍存在,可以认为他们分别是有序的。如果把冰和热水混合在一起,冰会融化,水温会降低,最终他们的状态达到了一致,都成了凉水(这个有前提,不赘述)。至此,系统从两个有序状态转向了无序状态,热力学系统就均匀分布了,熵就增加了。这是一个最简单的例子。但是,大家都知道,熵的来源是热力学第二定律,在热力学第一定律阐述了能量是守恒的朴素定理后,热二的熵要表述的就是即使能量是守恒的,但是能量引起的变化不一定是可以修复的。就好比冰化成了水,如果不引入外界系统做功,水不可能再恢复到冰的状态——也就说,这不是一个可逆的过程——有没有像俗语“说出去的话,像泼出去的水”。
回顾历史,这是一个伟大的论断,解决了永动机是不可行的理论证明,探讨了宇宙的熵增加宿命,甚至上升到了哲学层面。
好的,从热力熵回到信息熵的理解。熵表述的是一种状态,信息熵表述的就是事物的信息状态。事物的信息怎么定义呢?用我们最开始的例子解说,如果你确定一件事件的发生概率是100%,你认为这件事情的信息量为0——可不是吗,既然都确定了,就没有信息量了;相反,如果你不确定这件事,你需要通过各种方式去了解,就说明这件事是有意义的,是有信息量的。好的,你应该注意到了一个词“确定”。是的,信息熵表述的就是事物的不确定程度。一场势均力敌的比赛结果的不确定性高于一场已经被看到结果的比赛,多么符合直观理解啊!
信息熵公式解析:

从上面的直观表述,我们发现信息熵其实可以有很直观的表述,表征的是事物的不确定性。继续抽象,我们应该定量表述事物的不确定性呢?这就是信息熵的数学表述了。
我们知道,合理的数据定理都需要满足数学自洽性验证,我们已经知道确定的事件表述为P(A)=100%,则熵为0;假设一件事情,只有两种可能,则概率分布是P(A)和P(-A),其熵表述为
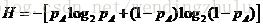
该式子对应的数据分布是

可以发现,但P(A)=0.5的时候,也就是事件结果最难预测的时候,信息熵是最大的,值达到1——这同样是符合直觉判断的。
那么,为什么求熵的时候用的是对数log2呢?这个就得从香农提出的信息熵使用的场景说起,大家都知道,香农提出的信息熵是用户信息论的,而信息论主要解决的是通讯问题,所以说,信息熵是和计算机通讯相关的理论。计算机的基本存储单位是二进制位,即1bit,每个bit都尤其只有两种表达——0或1。如果一个事件有两种可能性,且概率均等,都为50%,那么需要用1bit表示;如果有4种可能,且概率均等,则用2bit表示——你会发现,1bit刚好就是我们上面证明的H的最大值。这样就解释通了,底数为何为2了。
信息熵的应用:
个人觉得信息熵是个分析的利器,从熵的角度看,如果没有信息输入,系统不管用什么手段都不可能产生新的信息。这点就体现在我写过的《压缩算法引申》。这个思想同样可以应用在很多数据分析的场所,后续我将结合实际开发,一一整理。有机会也将我考虑的有关市场有效的弊端用熵的角度阐述。