一。共享内存模型
共享内存模型指的就是Java内存模型(简称JMM),JMM决定一个线程对共享变量的写入时,能对另一个线程可见。
从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:
线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。
本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。
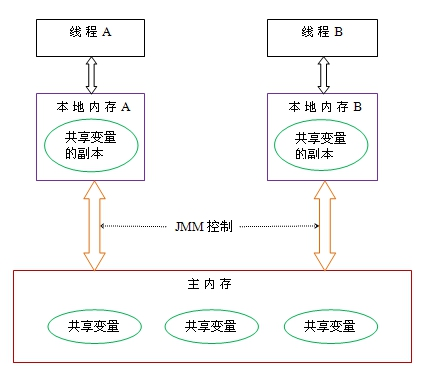
当多个线程同时访问一个数据的时候,可能本地内存没有及时刷新到主内存,所以就会发生线程安全问题。
二。Volatile
一旦某个线程修改了被volatile修饰的基本类型变量,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,可以立即获取修改之后的值。
在Java中为了加快程序的运行效率,对一些变量的操作通常是在该线程的寄存器或是CPU缓存上(即本地内存)进行的,之后才会同步到主存中,而加了volatile修饰符的变量则是直
接读写主存。Volatile 保证了线程间共享变量的及时可见性,但不能保证原子性。
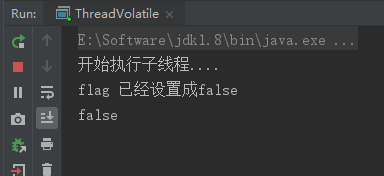
class ThreadVolatileDemo extends Thread { public boolean flag = true; @Override public void run() { System.out.println("开始执行子线程...."); while (flag) { } System.out.println("线程停止"); } public void setRuning(boolean flag) { this.flag = flag; } } public class ThreadVolatile { public static void main(String[] args) throws InterruptedException { ThreadVolatileDemo threadVolatileDemo = new ThreadVolatileDemo(); threadVolatileDemo.start(); Thread.sleep(3000); threadVolatileDemo.setRuning(false); System.out.println("flag 已经设置成false"); Thread.sleep(1000); System.out.println(threadVolatileDemo.flag); } }
可以看到结果为:flag已经设置为false了,但子线程却还在运行,问题就出在线程之间是不可见的,读取的是副本,没有及时读取到主内存结果。
解决办法使用Volatile关键字将解决线程之间可见性, 强制线程每次读取该值的时候都去“主内存”中取值。
1。Volatile特性:
1> 保证基本类型变量的可见性,即一个线程修改了某个基本类型变量的值,这新值对其他线程来说是立即可见的。
但对于引用类型如数组,实体bean,仅仅保证引用的可见性,但并不保证引用内容的可见性,需要基于CAS的原子结构才行(CAS的原子结构在锁的深入会讲到)。
2> 禁止进行指令重排序。(重排序后面会讲到)
2。volatile 性能:
volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,因为它需要在本地代码中插入许多内存屏障指令来保证处理器不发生重排序优化。
3。Volatile与Synchronized区别:
1> volatile仅能使用在变量级别。synchronized则可以使用在变量、方法、和类级别的。
2> volatile仅能实现变量的修改可见性,并不能保证原子性.。synchronized则可以保证变量的修改可见性和原子性。
3> volatile不会造成线程的阻塞。synchronized会造成线程的阻塞。
4> volatile标记的变量不会被编译器优化。synchronized标记的变量可以被编译器优化。
5> volatile修饰的变量在两个线程并行时,一个线程修改其值后会强制改变另外一个线程的该变量值。
例如多线程情况下需要用到某变量共享数据,当进行只读操作时可以使用volatile修饰变量。
当进行写操作的时候,由于volatile无法保证原子性所以建议使用synchronized来修饰变量。
三。重排序
在执行程序时,编译器和处理器会对指令进行重排序,重排序分为:
1> 编译器重排序:在不改变代码语义的情况下,优化性能而改变了代码执行顺序。
2> 指令并行的重排序:处理器采用并行技术使多条指令重叠执行,在不存在数据依赖的情况下,改变机器指令的执行顺序。
3> 内存系统的重排序:使用缓存和读写缓冲区时,加载和存储可能是乱序执行。
比如编译器重排序的典型就是通过调整指令顺序,在不改变程序语义的前提下,尽可能的减少寄存器的读取、存储次数,充分复用寄存器的存储值。
int a = 5;① int b = 10;② int c = a + 1;③ 假设用的同一个寄存器
这三条语句,如果按照顺序一致性,执行顺序为①②③寄存器要被读写三次;但为了降低重复读写的开销,编译器会交换第二和第三的位置,即执行顺序为①③②。
再比如对于不存在数据依赖的操作,前面new操作比较费时间,但也会先执行后面省时间的操作。
1。数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分下列三种类型:
|
名称 |
代码示例 |
说明 |
|
写后读 |
a = 1;b = a; |
写一个变量之后,再读这个位置。 |
|
写后写 |
a = 1;a = 2; |
写一个变量之后,再写这个变量。 |
|
读后写 |
a = b;b = 1; |
读一个变量之后,再写这个变量。 |
上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果将会被改变。
编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
2。as-if-serial语义
不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器,runtime 和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。
但是,如果操作之间不存在数据依赖关系,这些操作可能被编译器和处理器重排序。比如
|
double pi = 3.14; //A double r = 1.0; //B double area = pi * r * r; //C |
上面三个操作的数据依赖关系如下图所示:

如上图所示,A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。
因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。
但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。
3。程序次序规则(Program Order Rule)
根据happens- before的程序顺序规则,上面计算圆的面积的示例代码存在三个happens- before关系:
1> A happens- before B;
2> B happens- before C;
3> A happens- before C;
这里A happens- before B,但实际执行时B却可以排在A之前执行,在Java中,如果A happens- before B,JMM并不要求A一定要在B之前执行。
JMM仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。这里操作A的执行结果不需要对操作B可见;
而且重排序操作A和操作B后的执行结果,与操作A和操作B按happens- before顺序执行的结果一致。
在这种情况下,JMM会认为这种重排序并不非法(not illegal),JMM允许这种重排序。
在计算机中,软件技术和硬件技术有一个共同的目标:在不改变程序执行结果的前提下,尽可能的开发并行度。
编译器和处理器遵从这一目标,从happens- before的定义我们可以看出,JMM同样遵从这一目标。
4。重排序对多线程的影响
重排序可能会改变多线程程序的执行结果。
public class SimpleHappenBefore { private static int a=0; private static boolean flag=false; public static void main(String[] args) throws InterruptedException { for(int i=0;i<1000;i++){ Thread t1 = new Thread(new Runnable() { public void run() { a=1; flag=true; } }); Thread t2 = new Thread(new Runnable() { public void run() { if(flag){ a=a*1; } if(a==0){ System.out.println("ha,a==0"); } } }); t1.start(); t2.start(); t1.join(); t2.join(); a=0; flag=false; } } }
如果按照有序的话,那么在ThreadB中如果if(flag)成功的话,则应该a=1,而a=a*1之后a仍然为1,下方的if(a==0)应该永远不会为真,永远不会打印。而因为重排序却打印了几十次