redis作为缓存,在系统中需要支撑10万+的高并发时,会因单机版而出现性能瓶。在面对这种读远大于写的高并发情况,一般使用redis架构设计是读写分离的主从架构:主服务支撑数据的写入,从服务支撑高并发的读取。随着读取的并发数不断增加,可水平的扩展从服务器来应对。
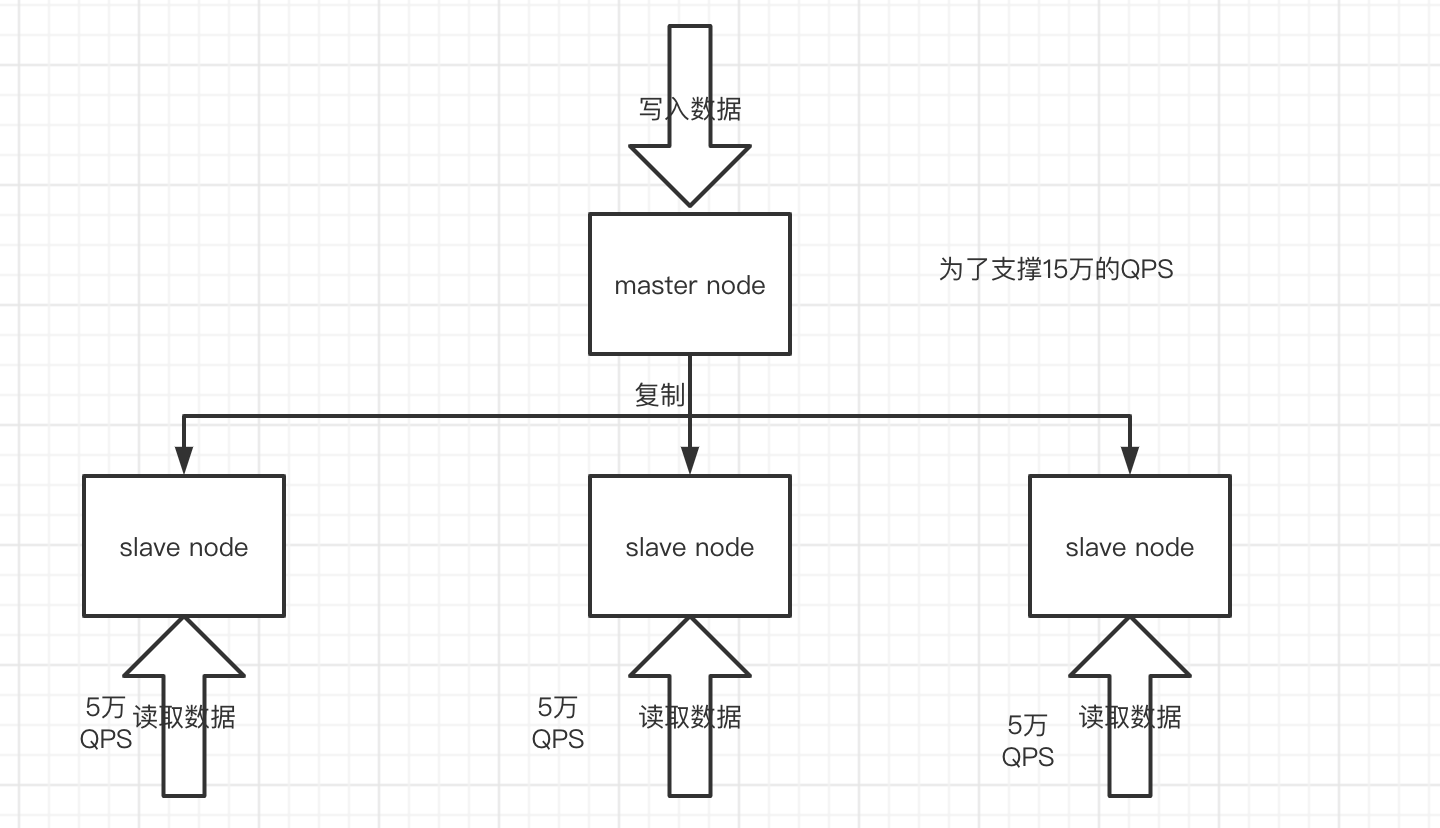
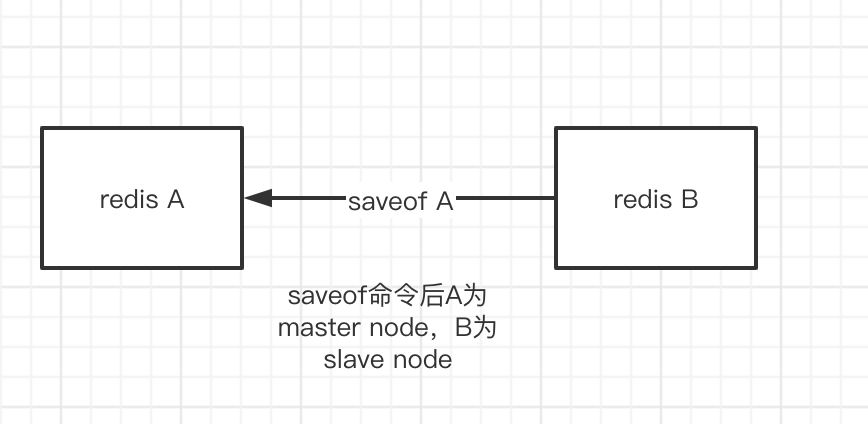
由于从服务只接受读取命令,并数据全部来源于主服务,保证俩者之间数据一致性的因素就是redis提供的复制功能。在redis中用可以使用saveof命令或者是配置saveof,让一个redis服务去复制另一个redis服务。假设:俩个redis服务 A:127.0.0.1:6379、B:127.0.0.2:6379。在A服务中发送saveof 127.0.0.2:6379 命令,那么服务A就会成为master node,服务B就会成为服务A的slave node,通过复制B和A保持数据一致。
旧版复制
在redis早期版本中,复制的实现主要是分为两个操作同步(sync)和命令传播(command propagate)
同步:将从服务的数据库状态更新至当时主服务的数据库状态。 命令传播:主服务的数据库状态被修改后,通过命令传播使从服务数据库状态保证一致。
同步
在命令saveof后,主从服务首先需要同步(sync)操作来保证俩个服务数据的一致性。
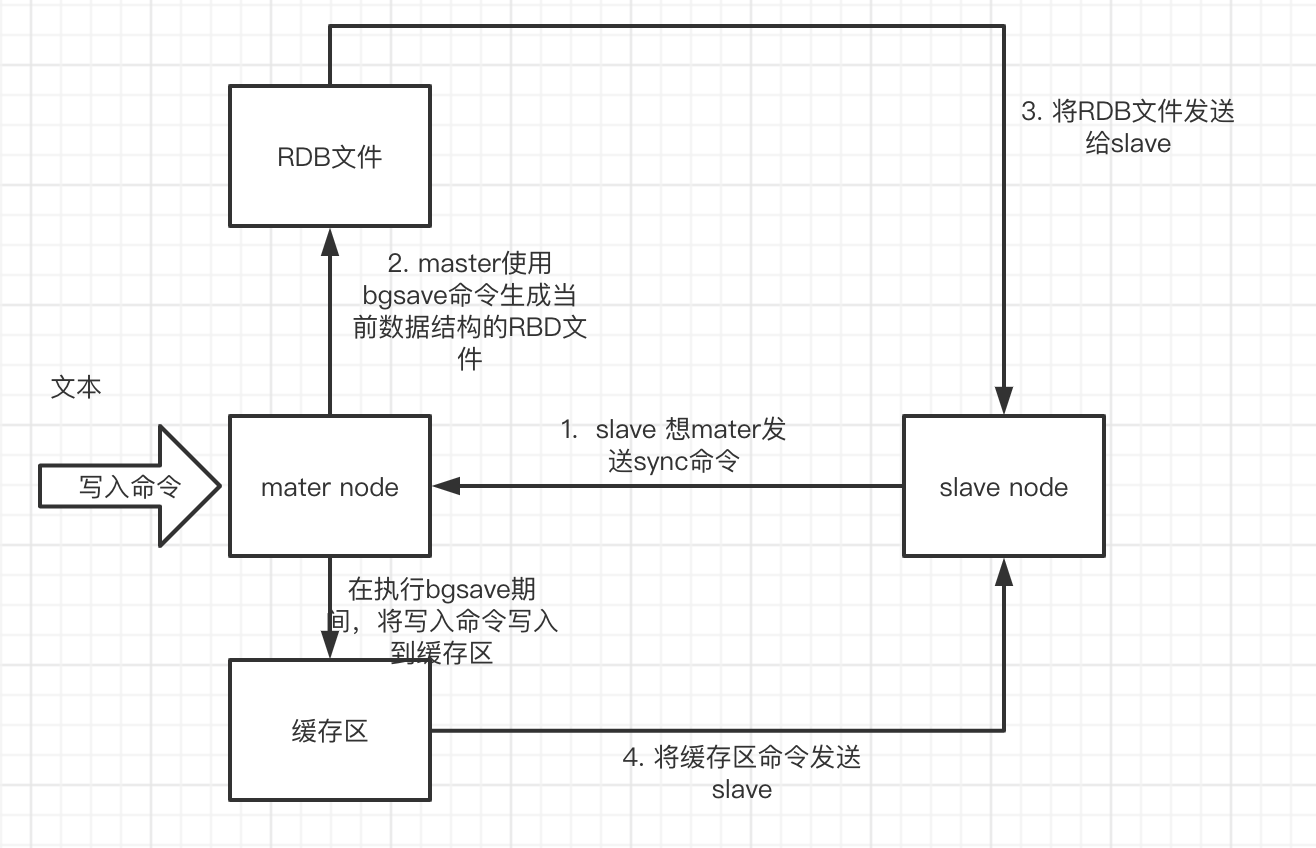
流程:
slave向master发送sync命令; master收到sync命令后,执行bgsave命令生成基于当时master数据库状态的RDB文件,并且在bgsave命令执行期间,master将该期间的写入命令,写入到一个缓存区; 将RDB文件发送给slave,slave同步数据; RDB同步完成,将缓存区命令发送给slave,同步数据; master和slave数据一致。
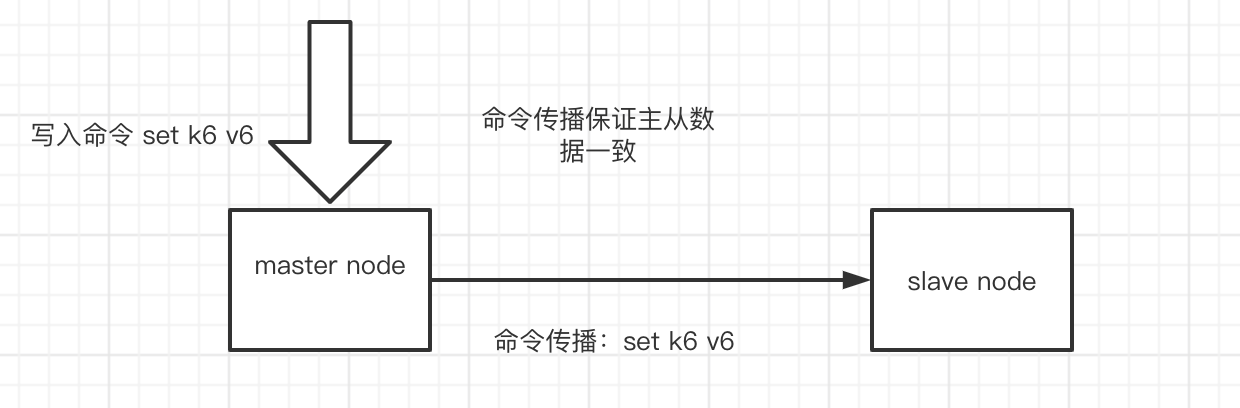
命令传播
在同步操作完成之后,基于当时的状态,主从服务数据达成一致状态。但是当后续master继续接受写入命令后,保证主从一致,通过命令传播操作完成。
缺陷
目前的复制功能可以完成主从服务的数据一致性。但是当slave掉线后,再次重新连接master服务后,为了保证数据一致性,就需要再次完成同步操作。同步操作是一个很消耗性能的操作,并且可能slave已存在一大半的数据,并不需要全量的RDB文件。在这种情况下,为了让从服务器补足一小部分缺失的数据,却要让主从服务器重新执行一次同步操作,这种做法无疑是非常低效的。
新版复制
为了解决旧版复制功能在处理断线重复制情况时的低效问题,Redis从2.8版本开始,使用PSYNC命令代替SYNC命令来执行复制时的同步操作。PSYNC命令具有完整重同步(full resynchronization)和部分重同步(partialresynchronization)两种模式:
完整重同步(full resynchronization):slave首次连接上master服务的同步操作,与sync基本一致。 部分重同步(partialresynchronization):slave在断线后重连master,master将slave断线期间产生的命令,发送给slave,同步缺失的数据。
部分重同步
部分重同步很好的解决了旧版复制的出现问题。它的实现主要依赖:
主服务器的偏移量和从服务器的偏移量 主服务的复制积压缓存区 服务的运行ID(RUNID)
偏移量
执行复制之后,主服务和从服务都会去维护一个各自的复制偏移量,主服务命令传播N个字节,偏移量增加N;从服务接受N个字节的命令,偏移量增加N。当主从服务的偏移量相等,主从数据即保持一致。
复制积压缓存区(backlog)
在主服务给从服务命令传播时,主服务会维护一个固定大小(默认1M)先进先出的队列作为复制积压缓存区。
当每次发生命令传播时,该命令既会被发送给从服务,也会被写入到积压缓存区。 进入队列后,队列会对每一个字节设置当前的所对应偏移量。 当队列已满时,会弹出最先进入的命令。

当slave服务断线重连后,会优先用slave的偏移量去队列查找,队列存在该偏移量,将该偏移量后面的命令发送给slave服务,部分重同步数据;负责,执行完整同步操作。
当需要自定义配置积压缓存区大小时,不易过大过小。可以根据平均断线重连时间(S)seconds和平均每秒产生的写命令数据量(协议格式的写命令的长度总和)writeSize判断:
配置:
// 默认1M
# repl-backlog-size 1mb
运行ID
运行ID在服务器启动时自动生成,由40个随机的十六进制字符组成。当从服务器对主服务器进行初次复制时,主服务器会将自己的运行ID传送给从服务器,而从服务器则会将这个运行ID保存起来。
当从服务断线重连之后,从服务将之前保存的主服务的运行ID发送给主服务,主服务和自身比较运行ID。
运行ID相同,主服务为断线之前的服务,尝试执行部分重同步操作。 运行ID不相同,主服务重启或者不是断线之前的主服务,执行完整重同步操作。
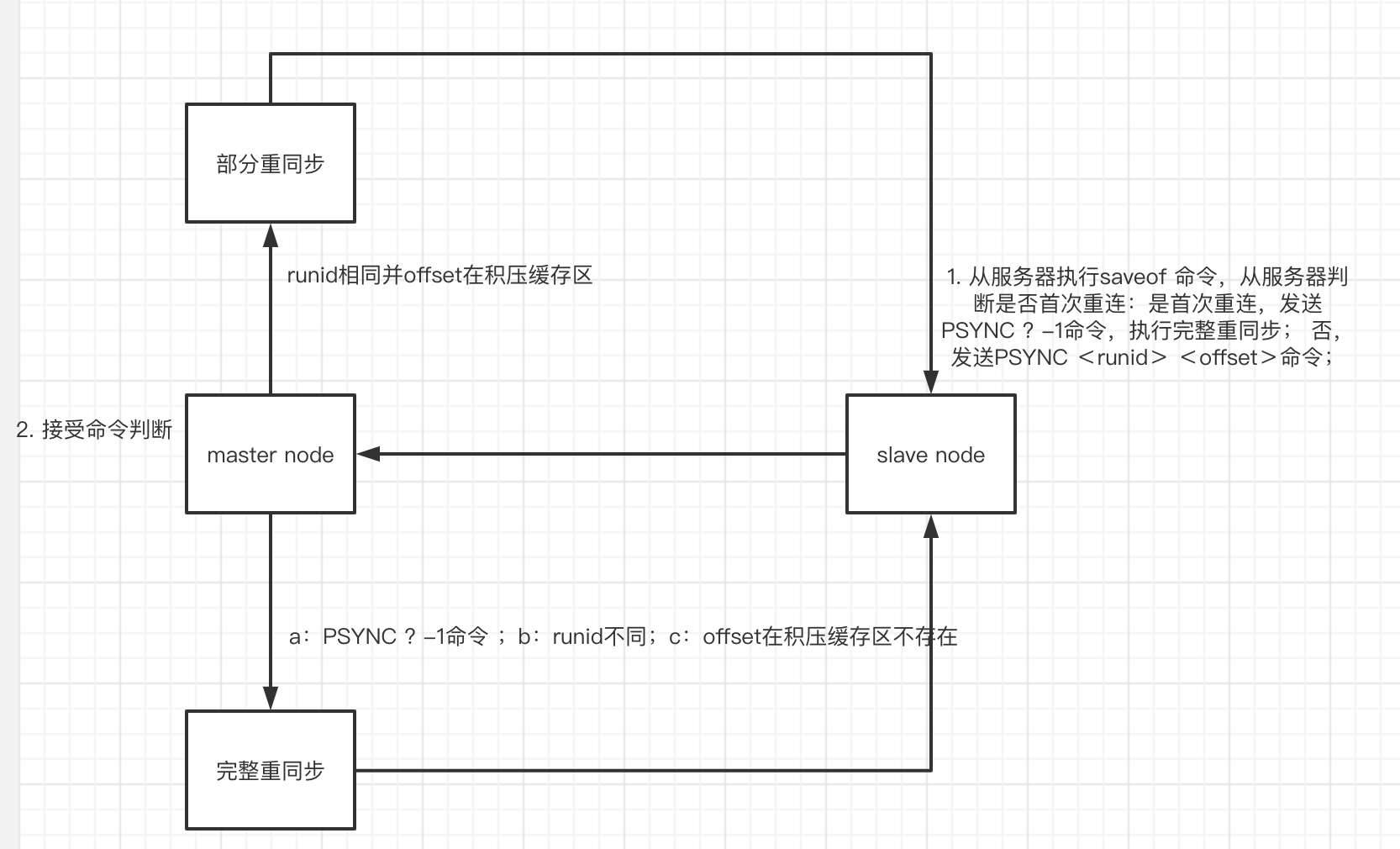
psync
从服务器首次复制,发送psync ?-1命令,表示首次连接,执行完整重同步。 从服务断线重连,发送psync 命令: 主服务收到的runid与自身相同,在积压缓存区查找offset存在,执行部分重同步。 runid不同或者offset积压缓存区不存在,执行完整重同步。
身份验证
主从服务在要在进行同步之前,可以设置身份校验。
从服务
# masterauth <master-password>
masterauth GGuoLiang
主服务
# requirepass foobared
requirepass GGuoLaing
当从服务设置masterauth,进行身份验证。主从服务配置值相同,验证成功。 当从服务没有设置masterauth,不进行身份验证。
min-slaves配置
Redis的min-slaves-to-write和min-slaves-max-lag两个选项可以防止主服务器在不安全的情况下执行写命令。
# min-slaves-to-write 3
# min-slaves-max-lag 10
从服务少于3个,或者三个从服务器的延迟(lag)值都大于或等于10秒时,主服务拒绝写入命令。
复制实现
流程:
从服务发送saveof host:port命令,并保存主服务的ip和端口号; 主从服务器建立socket连接; 从服务发送ping主服务返回pong响应; 主从服务身份验证成功; 从服务发送端口号,主服务保存该属性; 同步操作保证当前数据一致; 命令传播保证后续数据一致。
心跳
在命令传播期间,从服务器会默认以每秒的频率发送心跳检测命令:replconf ack
检测主从服务的网络连接。 辅助实现min-slave配置。 检测命令丢失,比对偏移量,有缺失命令从新发送。
参考:redis设计与实现