浅谈一下流式处理平台(Flink)
大数据框架听过很多,比如 Hadoop,HDFS...不过自己的项目都没有上过
为什么突然提到 Flink,因为最近一个项目需要用到,所以学习最好的方式就是项目驱动
以前总觉得自己要学会了某样东西再去做,等学会了,也许又用不上,久而久之,又忘了
下面我结合项目,浅谈一下 Flink
01、Flink 入门
百度一下:Flink 是什么?
上面的介绍我们每个字都看得懂,但连在一起就看不懂了。
不管怎么样,至少我们知道了:Flink 是一个分布式的计算处理引擎。
- 分布式:它的存储或计算交由多台服务器完成,最后汇总起来达到最终的效果。
- 实时:处理速度是毫秒或者秒级的。
- 计算:可以简单理解为是对数据进行处理。
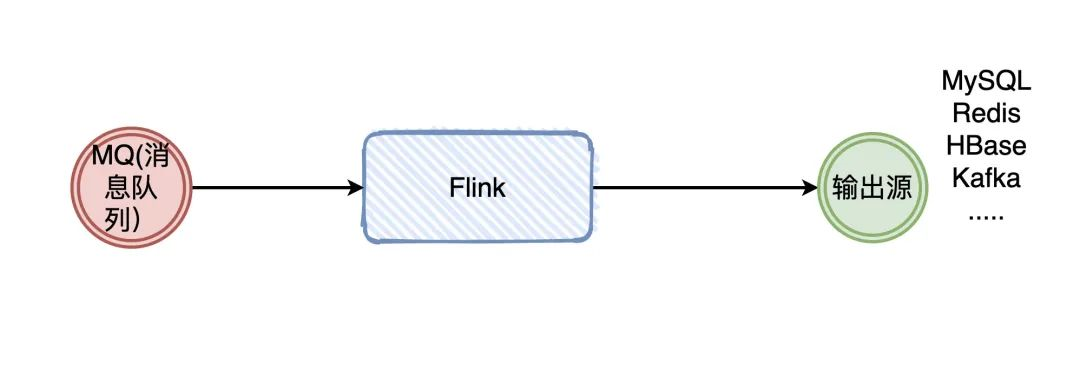
什么是有边界和无边界?
Apache Flink 是一个框架和分布式处理引擎,用于在*无边界和有边界*数据流上进行有状态的计算。
官网其实也有介绍,但对初学者来说不太好理解,我来幼儿园化一下。
大家应该都用过消息队列吧,Producer 生产数据,发给 Broker,Consumer 消费,完事。
在消费的时候,我们需要知道 Producer 发了多少条消息吗?什么时候发的吗?不需要吧。反正你来一条,我就处理一条,没毛病吧。
这种没有做任何处理的消息,默认就是无边界的。
那有边界就很好理解了嘛:无边界的基础上加上条件,那就是有边界的。
加什么条件呢?比如我要加个时间:我要从3月22号到3月23号的数据,那就是有边界的。
什么时候用有边界,什么时候用无边界?那也很好理解,
我做数据清洗:来一条,我处理一条,这种无边界就好了。
我要做数据统计:每小时的pv(page view)是多少,那我就设置1小时的边界,攒够1小时我再来处理。
在Flink上,设置“边界”这种操作叫做开窗口(window),窗口可以简单分为两种类型:
-
时间窗口(
TimeWindow):按照时间窗口对数据进行聚合,比如上面说的1小时一次。 -
计数窗口(CountWindow):按照指定的条数来做聚合,比如攒够10条数据处理一次。
听着就很人性化(妈妈再也不用担心我需要聚合了)
不仅如此,在Flink使用窗口聚合的时候,还考虑到了数据的准确性问题。
比如:我在 11:06分 产生了5条数据,在11:07产生了4条数据,我现在是按时间窗口每分钟来做聚合的。
理论上来讲:Flink应该在 11:06分聚合了5条数据,在11:07聚合了4条数据。
但是,可能由于网络的延迟性原因,导致11:06分有3条数据在11:07才接收到,如果不做处理,就造成了 06分处理3条,07分处理7条。
这个结果对于需要准确性的场景来说,就太不合理了。所以Flink可以给我们指定时间语义,不指定默认是数据到Flink的时候(Process Time)来进行处理。我们可以指定聚合时间为事件发生的时间(Event Time)来进行处理。
事件发生时间就是:日志真正记录的时间。
2020-11-22 00:00:02.552 INFO [http-nio-7001-exec-28] c.m.t.rye.admin.web.aop.LogAspect
虽然指定了聚合时间为事件发生的时间(Event Time),但还是没解决数据乱序的问题(06分产生了5条数据,实际上06分只收到了3条,而剩下的两条在07分才收到,那此时怎么办呢?在06分时该不该聚合,07分收到的两条06分数据怎么办?)
Flink又给我们设置了水位线(waterMarks)
Flink的意思就是:存在网络延迟等情况导致数据接受不是有序,这种情况我能理解,那你设置一个延迟时间吧,等延迟时间到了,我再做统一聚合。
比如我设置延迟时间为1分钟,等到07分的时候,我再对 06分的窗口做聚合处理。
什么叫有状态?
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。
无状态我们可以理解为:每次的执行都不会依赖以前的执行结果,每次的执行都是独立的。
有状态就很好理解了:每次的执行都依赖上一次的执行结果。
举个栗子:我们现在要统计文章的阅读pv(page view),现在只要有一个点击了文章,在kakfa中就会有一条消息。现在我要在流式处理平台上进行统计,那此时是有状态还是无状态的?
比如说:我用Redis对结果进行存储,来一条数据,我就先查一下Redis目前的值是多少,然后在当前值的基础上累加一下就完事了。
假设用Flink做,Flink本身就提供了这种功能给我们使用,我们可以依赖Flink的“存储”,将每次的处理结果交给Flink处理。
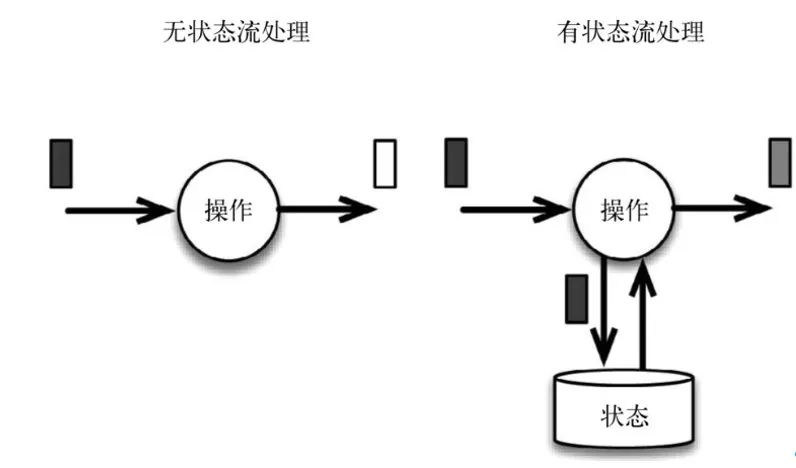
可以简单的认为:Flink本身就给我们提供了“存储”的功能,我们的每次执行是可以依赖Flink的“存储”的,所以它是有状态的。
那Flink是把这些有状态的数据存储在哪的呢?
主要有三个地方:
- 内存
- 文件系统(HDFS)
- 本地数据库

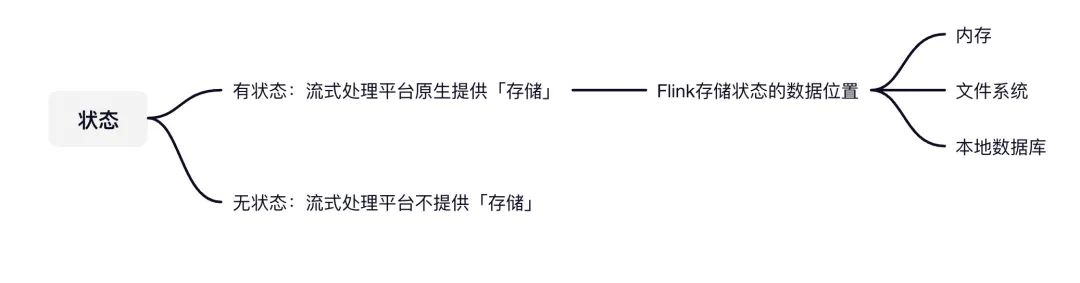
如果Flink挂了,可能内存的数据没了,磁盘可能存储了部分的数据,那再重启的时候,就不怕数据丢失吗?
看到这里,你可能会在别的地方看过Flink的另外一个比较出名的特性:精确一次性(exactly once)
什么是精确一次性(exactly once)?
众所周知,流的语义性有三种:
- 精确一次性(exactly once):有且只有一条,不多不少
- 至少一次(at least once):至少有一条,只多不少
- 最多一次(at most once):最多有一条,可能没有
Flink的精确一次性指的是:状态(这个状态指上面提到的有状态)只持久化一次到最终介质中(本地数据库/HDFS...)
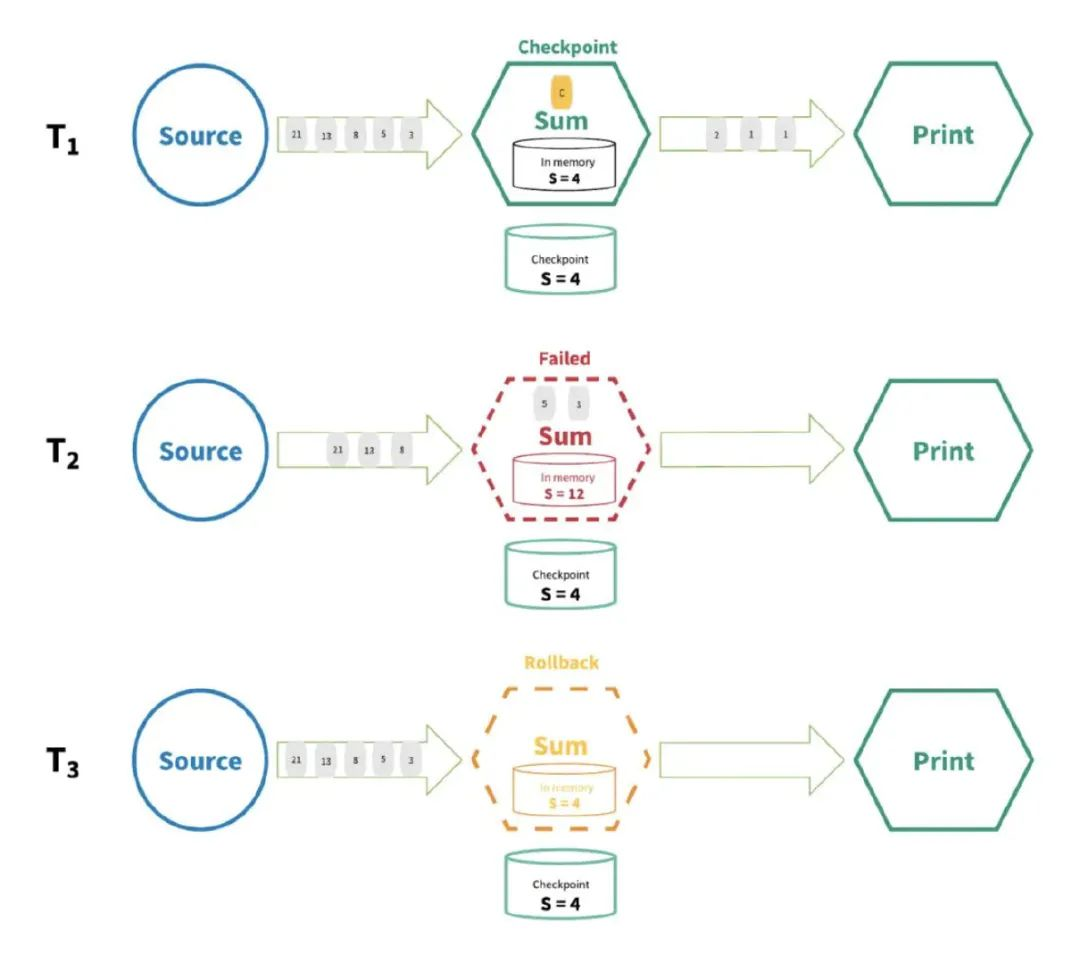
以上图为例:假设我的 source 有以下数字21,13,8,5,3,2,1,1,然后在Flink中做一个累加操作。
现在已经处理完2,1,1了,所以累加的 sum = 4,现在Flink把状态 sum 已经存储到最终介质中去了
然后开始处理5,3,得到的 sum = 12,但是 Flink还没来得及把 12存储到最终介质中 就挂了。
Flink重启后会重新把系统恢复到 sum = 4 的状态,所以5,3得继续计算一遍。
所以 Flink的精确一次性指的就是:状态只持久化一次到最终介质中(本地数据库/HDFS...)
至于Flink是在多长时间存储一次,是我们自己手动配置的。

根据上面的代码,我们可以发现,设置存储的时间在Flink中叫做 CheckPoint。
所谓的 CheckPoint就是 Flink会在指定的时间段上保存状态的信息,如果Flink挂了,可以直接将上一次保存的状态信息捞出来,继续执行计算,最终实现(exactly once)。
那CheckPoint是怎么实现的呢?
想想我们使用 kafka 在业务上的至少一次是怎么实现的:我们从 kafka 上面拉取数据,处理完业务后,手动提交 offset(告诉kafka 我已经处理完了)
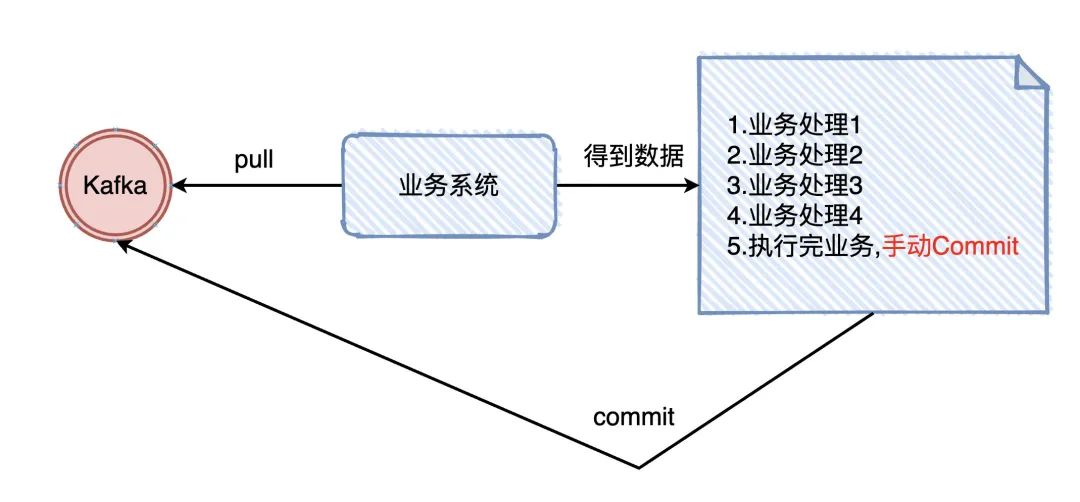
我们是做完了业务后才将offset进行 commit 的, checkpoint其实也是一样的(等拉下来的数据全部处理完,才进行真正的 checkpoint)
那Flink是怎么知道拉下来的数据已经走完了呢?
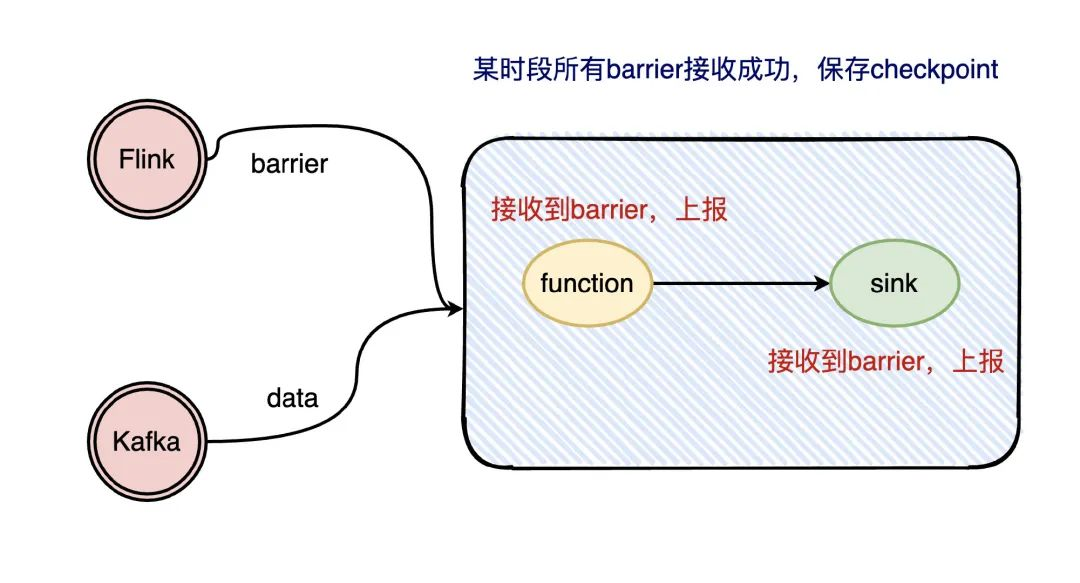
Flink在流处理过程中插入了 barrier,每个环节处理到 barrier 都会上报给 sink,等所有的 barrier 都上报了,说明这次的 checkpoint已经走完了
02、什么是流式处理平台
举个例子,比如商家要在平台上投放广告,我们要给商家看到广告带来的效果,最核心的就是 「曝光量」「点击量」「订单量」
下面来聊一下这个「发展历程」,看完这个过程或许可以更好的了解为什么需要流式处理平台
1、PHP阶段:在最初时,业务以及系统结构都比较简单,直接把「曝光量」「点击量」「订单量」存入数据库,再一把梭通过定时任务进行全量聚合,得到最终的效果数据。
在这个阶段里,由于数据量不大,通过定时任务全量来做聚合数据也不算不可以,那时候商家都能接受业务的延迟性,大概5min出数据。
2、Java阶段:随着业务发展,数据量日益提升,站内中间件服务平台也发展起来了。通过中间件团队提供的消费 binlog框架,从架构上改变聚合模式。这个阶段可以更快的给商家展示效果数据,大概1min出数据。
3、流式处理平台阶段:流式处理平台是对「计算」或者说是处理数据时的抽象,在这抽象基础上,它更能充分利用系统的资源(一个大的任务拆分成多个小任务,分发到不同的机器上执行),大概秒级出数据。
02、项目哪些地方用到了 Flink
我所做的项目是一个消息发送系统,Flink 用于对「消息发送者」「模板消息」等维度作聚合处理,得到的数据再给到接口去展示或者排查问题使用,能大大提高排查方和业务方的使用效率
最后,给大家安利一个公众号:Java3y,备注【项目】,进群一起跟着 3y 做项目,项目就是当前的消息发送系统,公众号上还有很多面试资料,快冲啊。