今天分享 Java 对象序列化的不同方法,并对不同序列化方式的性能进行基准测试。
关于持久队列来讲,必须将 Java 堆内存的对象转换成文件中的二进制数据,对象序列化的性能将显著影响整体的性能表现。相当多的高性能框架都会在序列化和反序列化上下功夫优化性能。本文使用了开源框架 Chronicle Queue 提供的能力进行序列化和反序列化对比测试。
数据传输对象
在本文中,我用一个对象类FunData,作为 Data Transfer Object(以下简称 DTO)的数据传输对象 ,其中包含具有较多字段的信息。相同的原则适用于任何其他业务领域的其他 DTO。
abstract class FunData extends SelfDescribingMarshallable {
long securityId;
long time;
double bidQty0, bidQty1, bidQty2, bidQty3;
double askQty0, askQty1, askQty2, askQty3;
double bidPrice0, bidPrice1, bidPrice2, bidPrice3;
double askPrice0, askPrice1, askPrice2, askPrice3;
}
默认序列化
Java 的 Serializable 标记接口提供了一种将 Java 对象序列化为二进制格式的默认方法,通常通过ObjectOutputStream 和ObjectInputStream 类。默认方式(即writeObject()和readObject()显式声明)需要反映对象字段并逐个读取/写入它们,这可能是一项比较消耗性能的操作。
Chronicle Queue 可以处理 Serializable 对象,但也提供了一种类似但更快、更节省空间的方法来通过抽象类序列化数据SelfDescribingMarshallable。与 Serializable 对象类似,这依赖于反射,但在CPU 性能和垃圾方面的开销要少得多。
默认序列化通常包括以下步骤:
- 使用反射识别非瞬态场
- 使用反射读取/写入已识别的字段值
- 将字段值写入/读取为目标格式(例如二进制格式)
字段的关系可以被缓存,这样可以进一步提高性能。
这是使用默认序列化的类的示例:
public final class DefaultFunData extends FunData {}
可以看出,该类没有在其基类上添加任何内容,因此它将使用SelfDescribingMarshallable进行序列化和反序列化。
显式序列化
实现的类 Serializable 可以选择实现两个 private 方法,从而调用这些方法,而不是使用默认的序列化。
这提供了对序列化过程的完全控制,并允许使用自定义代码而不是通过反射来读取字段,这将提高性能。这种方法的一个缺点是,如果在类中添加了一个字段,那么必须在上面的两个private方法中添加相应的逻辑,否则新的字段将不参与序列化。
SelfDescribingMarshallable 以类似的方式工作,但谢天谢地,它不依赖于这两个私有方法方法和从外部调用私有方法。一个SelfDescribingMarshallable 类提供了两种根本不同的序列化概念:一种通过中介Chronicle Wire开源(可以是二进制、文本、YAML、JSON 等)提供灵活性,另一种隐式二进制提供高性能(后面再分享)。
这是一个使用显式序列化的类的示例,其中显式声明了实现接口的公共方法:
public final class ExplicitFunData extends FunData {
@Override
public void readMarshallable(BytesIn bytes) {
securityId = bytes.readLong();
time = bytes.readLong();
bidQty0 = bytes.readDouble();
bidQty1 = bytes.readDouble();
bidQty2 = bytes.readDouble();
bidQty3 = bytes.readDouble();
askQty0 = bytes.readDouble();
askQty1 = bytes.readDouble();
askQty2 = bytes.readDouble();
askQty3 = bytes.readDouble();
bidPrice0 = bytes.readDouble();
bidPrice1 = bytes.readDouble();
bidPrice2 = bytes.readDouble();
bidPrice3 = bytes.readDouble();
askPrice0 = bytes.readDouble();
askPrice1 = bytes.readDouble();
askPrice2 = bytes.readDouble();
askPrice3 = bytes.readDouble();
}
@Override
public void writeMarshallable(BytesOut bytes) {
bytes.writeLong(securityId);
bytes.writeLong(time);
bytes.writeDouble(bidQty0);
bytes.writeDouble(bidQty1);
bytes.writeDouble(bidQty2);
bytes.writeDouble(bidQty3);
bytes.writeDouble(askQty0);
bytes.writeDouble(askQty1);
bytes.writeDouble(askQty2);
bytes.writeDouble(askQty3);
bytes.writeDouble(bidPrice0);
bytes.writeDouble(bidPrice1);
bytes.writeDouble(bidPrice2);
bytes.writeDouble(bidPrice3);
bytes.writeDouble(askPrice0);
bytes.writeDouble(askPrice1);
bytes.writeDouble(askPrice2);
bytes.writeDouble(askPrice3);
}
}
可以得出结论,该方案依赖于显式和直接地读取或写入每个字段,无需诉诸较慢的反射执行。必须注意确保一致性顺序,避免出现问题。一旦类的字段有更新,必需修改这两个方法中所涉到的内容
拷贝不变(trivially copyable)
可以看出,FunData 上面的类只包含原始字段。换句话说,没有像 String,List 或类似的引用字段。这意味着当 JVM 在内存中布局字段时,字段值可以彼此相邻放置。Java 标准中未指定字段的布局方式,该标准允许单独的 JVM 实现优化。
许多方案会按字段大小降序对原始类字段进行排序,并依次排列它们。这样做的好处是可以在甚至原始类型边界上执行读取和写入操作。将此方案 ExplicitFunData 应用于示例将导致long time首先布局字段,并且假设我们的初始字段空间是 64 位对齐的,则允许在偶数 64 位边界上访问该字段。接下来,int securityId可能会布局,允许在偶数 32 位边界上访问它和所有其他 32 位字段。
想象一下,如果最初布局了初始 byte 字段,则必须在不均匀的字段边界上访问后续更大的字段。这会增加一些操作的性能开销,并且确实会阻止执行一小组操作(例如,ARM 体系结构上未对齐的 CAS 操作)。
事实证明,可以直接访问对象的字段内存区域,Unsafe 并使用 mem copy 在一次扫描中直接将字段复制到内存或内存映射文件。这有效地绕过了单独的字段访问,并在上面的示例中用单个批量操作替换了许多单独的字段访问。
要想实现以上的功能是一件非常麻烦的事情,我们可以在 Chronicle Queue、开源 Chronicle Bytes和其他开箱即用的类似产品中很容易获得。
下面是一个使用可复制序列化的类的示例:
import static net.openhft.chronicle.bytes.BytesUtil.*;
public final class TriviallyCopyableFunData extends FunData {
static final int START = triviallyCopyableStart(TriviallyCopyableFunData.class);
static final int LENGTH = triviallyCopyableLength(TriviallyCopyableFunData.class);
@Override
public void readMarshallable(BytesIn bytes) {
bytes.unsafeReadObject(this, START, LENGTH);
}
@Override
public void writeMarshallable(BytesOut bytes) {
bytes.unsafeWriteObject(this, START, LENGTH);
}
}
这种模式非常适合重用 DTO 的场景。从根本上说,它依赖于在幕后调用 Unsafe 以提高性能。
基准测试
这里使用 JMH,使用此类对上述各种序列化替代方案的序列化性能进行了评估:
@State(Scope.Benchmark)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(NANOSECONDS)
@Fork(value = 1, warmups = 1)
@Warmup(iterations = 5, time = 200, timeUnit = MILLISECONDS)
@Measurement(iterations = 5, time = 500, timeUnit = MILLISECONDS)
public class BenchmarkRunner {
private final FunData defaultFunData = new DefaultFunData();
private final FunData explicitFunData = new ExplicitFunData();
private final FunData triviallyCopyableFunData = new TriviallyCopyableFunData();
private final Bytes<Void> toBytes = Bytes.allocateElasticDirect();
private final Bytes<Void> fromBytesDefault = Bytes.allocateElasticDirect();
private final Bytes<Void> fromBytesExplicit = Bytes.allocateElasticDirect();
private final Bytes<Void> fromBytesTriviallyCopyable = Bytes.allocateElasticDirect();
public BenchmarkRunner() {
defaultFunData.writeMarshallable(fromBytesDefault);
explicitFunData.writeMarshallable(fromBytesExplicit);
triviallyCopyableFunData.writeMarshallable(fromBytesTriviallyCopyable);
}
public static void main(String[] args) throws Exception {
org.openjdk.jmh.Main.main(args);
}
@Benchmark
public void defaultWrite() {
toBytes.writePosition(0);
defaultFunData.writeMarshallable(toBytes);
}
@Benchmark
public void defaultRead() {
fromBytesDefault.readPosition(0);
defaultFunData.readMarshallable(fromBytesDefault);
}
@Benchmark
public void explicitWrite() {
toBytes.writePosition(0);
explicitFunData.writeMarshallable(toBytes);
}
@Benchmark
public void explicitRead() {
fromBytesExplicit.readPosition(0);
explicitFunData.readMarshallable(fromBytesExplicit);
}
@Benchmark
public void trivialWrite() {
toBytes.writePosition(0);
triviallyCopyableFunData.writeMarshallable(toBytes);
}
@Benchmark
public void trivialRead() {
fromBytesTriviallyCopyable.readPosition(0);
triviallyCopyableFunData.readMarshallable(fromBytesTriviallyCopyable);
}
}
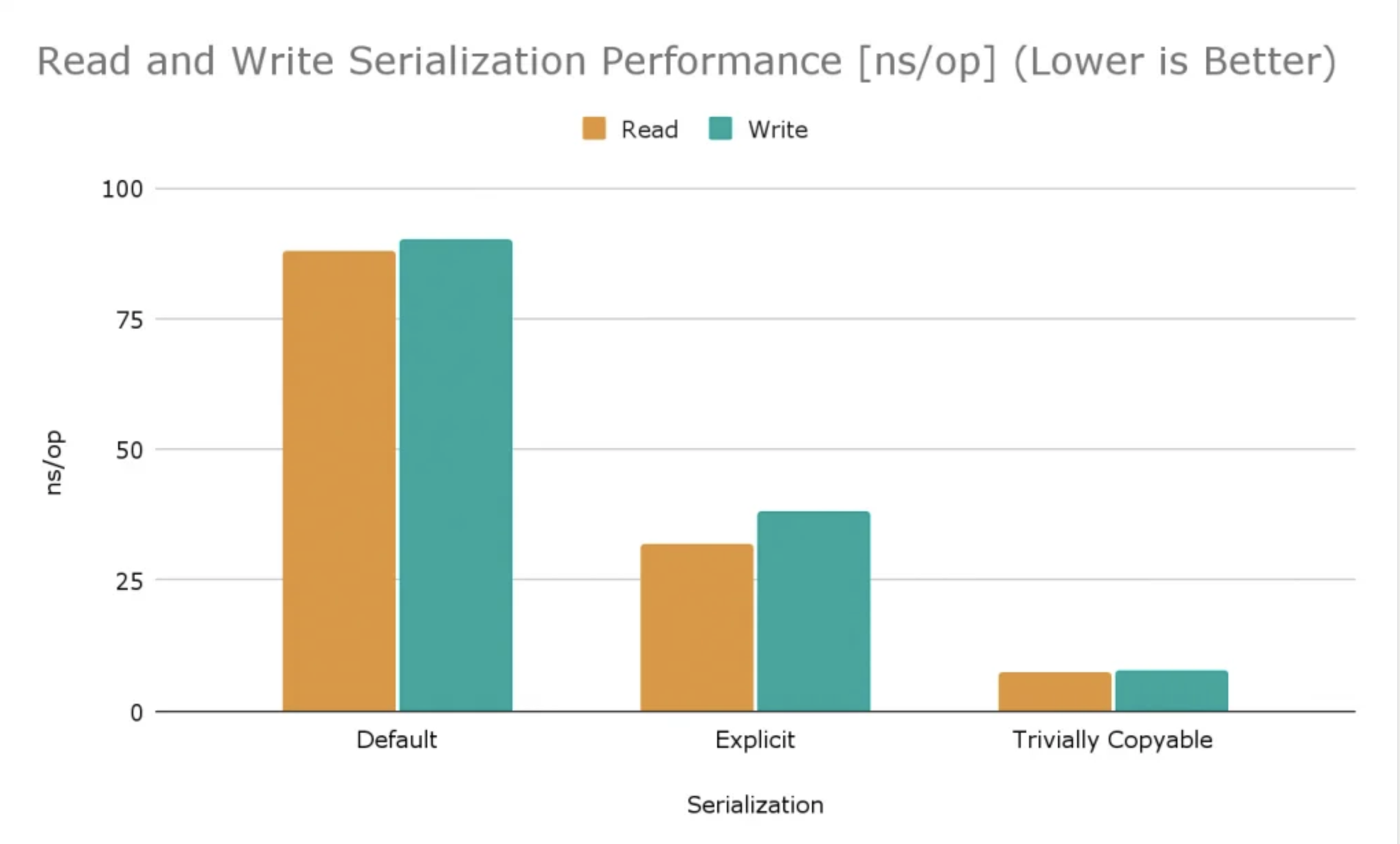
这在 JDK 1.8.0_312、2.3 GHz 8 核 Intel Core i9 CPU 的 MacBook Pro(16 英寸,2019 年)上产生了以下测试结果:
Benchmark Mode Cnt Score Error Units
BenchmarkRunner.defaultRead avgt 5 88.772 ± 1.766 ns/op
BenchmarkRunner.defaultWrite avgt 5 90.679 ± 2.923 ns/op
BenchmarkRunner.explicitRead avgt 5 32.419 ± 2.673 ns/op
BenchmarkRunner.explicitWrite avgt 5 38.048 ± 0.778 ns/op
BenchmarkRunner.trivialRead avgt 5 7.437 ± 0.339 ns/op
BenchmarkRunner.trivialWrite avgt 5 7.911 ± 0.431 ns/op
使用各种 FunData 变体,显式序列化比默认序列化快2倍以上。拷贝不变(trivially copyable)序列化比显式序列化快四倍,比默认序列化快十倍以上,如下图所示(越低越好):