面试笔试知识储备
前言
有道无术术可求 有术无道止于术
大企业更加看重的是求职者的基础知识以及解决问题的能力;
小企业更注重求职者的实用性,求职者当前会什么,能给企业带来什么。
创业型公司研发人员较少,每个研发人员都需要能够独当一面,对于个人成长是很好的锻炼机会,但身兼数职,经常加班,在专业技能上不够规范
大型公司可以集中锻炼某项专业技能,有完善的团队、严格的规章制度等
IT技术性人才需要有的优点:
基本功扎实
强烈的求知欲、有冲劲、愿拼搏
在某个领域有比较深入的研究
对人对事有信心
掌握多项技能
快速学习能力
求精不求全
在面试中被问到不擅长的领域时,讲出自己的理解,并直言自己这方面知识的欠缺,坦白比不懂装懂更真实更有力量
面试需注意的问题:
眼神交流
语速适当:语速不要太快,放慢节奏,舒缓身心
背景了解:企业发展历程和现状,公司理念、制度、规划,谈谈你喜欢的或你认为可以改善的方面
选择Offer:
选择企业的核心研发部门
选择喜欢或擅长的专业领域
笔试面试常见考点:
列举处:如
比较处
性能优化
算法设计和实现
数据结构
链表:
单链表:当结点只包含其后继结点的信息的链表
插入元素:
将值为x的新节点插入到单链表的第i个结点的位置上(ai-1到ai之间)
1. 找到ai-1的存储位置p
2. 生成一个新节点s(数据为x)
3. p.next = s;
4. s.next = a;
删除元素:
将单链表的第i个结点删去(ai)
1. 找到ai-1的存储位置p
2. p.next = ai+1
算法
排序:https://www.cs.usfca.edu/~galles/visualization/ComparisonSort.html
选择排序 Selection Sort:
经过第一轮比较后得到最小记录,将该记录与第一个记录的位置进行交换;
接着对第一个记录以外的其他记录进行第二轮比较,得到的最小记录与第二个记录的位置进行交换;
直到进行比较的记录只有一个时为止。
O(n2)
插入排序 Insertion Sort:
从第二个记录开始,按照记录的大小依次将当前处理的记录插入到其之前的有序序列中
(从当前记录之前一个记录开始遍历,直到当前记录大于遍历的记录,所处位置即为有序排列的位置)
直到最后一个记录插入为止。
O(n2)
冒泡排序 Bubble Sort:
从第一个记录开始依次对相邻的两个记录进行比较(如需要则交换位置)
每一轮过后,总共n个记录中最大的记录会被放在第n个位置上(第一轮为最大记录,第二轮为第二大记录...)
O(n2)
归并排序 Merge Sort:
利用递归和分治技术 (Partition)将数据序列划分成越来越小的半子表
归:递归分离:将数组折半分离最后成为只有单个元素的数组
并:合并:将分开的数组内的元素按顺序合并成为新的数组
第一轮:将每两个相邻的(长度为1)子序列进行归并,得到n/2个长度为2(有可能剩下多余的1个)的有序子序列;
重复进行归并直到得到最终的一个有序序列
时间复杂度为O(nlogn):logn趟*每趟n次比较
快速排序 Quick Sort: http://www.sczyh30.com/posts/Algorithm/algorithm-quicksort/
分而治之的思想
通过一趟排序后,取一个元素(pivot),将原数列分为两部分。前一部分的所有记录小于pivot,后一部分的所有记录大于pivot。
依次对这两部分的所有记录进行快速排序,直到所有记录有序为止。
算法可分为三部分:
(需要先得到基准 pivot)
分解:将序列arr[m, n]划分成两个非空子序列arr[m, k]和arr[k+1, n]
递归求解:递归对子序列调用快排
合并:不需要进行多余操作
详细过程:
得到pivot后,将该pivot移动到序列最后
创建小于等于区间(初始时区间长度为0)
从第一个元素开始遍历,如果当前元素大于pivot,则进入下一元素;
如果当前元素大于/等于pivot,则将当前数和小于等于区间的下一个元素进行交换,并让小于等于区间向右扩张一个位置。
遍历到最后一个元素后(即pivot前一个元素),将pivot和小于等于区间的下一个元素进行交换
结果得到小于等于区间、pivot、大于等于区间(一个完整的划分过程)-- O(n)
Analysis: 当初始序列整体或局部有序时,快排性能下降退化为冒泡排序
Worst case: 每次区间划分的结果均为一边序列为空,另一边区间仅比排序前少一项;满足条件:每次选取的pivot都是该子序列中的最值。此时需要递归(n-1)层,在第k层划分前序列长度为n-k+1, 层内需要进行n-k次比较。总次数为((n-1)+(1))*(n-1)/2,即为O(n2)。
Best case: 每次区间划分的结果均为两个子序列长度相等或者相差1,此时递归logn层,O(nlogn)。
Average case: O(nlogn) 在所有平均时间复杂度为O(nlogn)的排序算法中,快速排序的性能是最好的。
空间复杂度:需要一个栈空间来实现递归。Worst case下递归树的最大深度为n,best case下递归树的最大深度为logn+1。平均复杂度空间为O(logn)。
基准关键字 pivot:pivot的选择是决定快排性能的关键。常见两种方法:
1. 三者取中:首尾和中间位置的记录取中值作为pivot,排序前交换序列第一个记录与pivot记录的位置。
2. 随机:取随机数m(left<=m<=right),用n[m]作为pivot
快速排序和归并排序的关系:
都是基于分而治之的思想--分离、排序、合并
分组策略不同;
合并策略不同;
希尔排序/缩小增量排序 Shell Sort:
非稳定排序,直接插入排序的改进版本
把记录按下标的一定增量进行分组,对每组进行直接插入排序;
(插入排序中,当前元素要跟之前元素进行比较,每次跟之前一个元素进行比较,即步长为1
而希尔排序的步长是逐渐(从大到小)调整的)
i.e. 6 5 3 1 8 7 2 4 设初始步长为3
第一趟: 6 5 3 作为前三个数,步长为3直接越界了,跳过
1跳3步,与6比较,1<6,交换,再跳3步,越界,跳过
-- 1 5 3 6 8 7 2 4
8跳3步,与5比较,8>5,不交换,再跳3步,越界,跳过
7跳3步,与3比较,7>3,不交换,再跳3步,越界,跳过
2跳3步,与6比较,2<6,交换,再跳3步,与1比较,2>1,不交换,再跳三步,越界,跳过
-- 1 5 3 2 8 7 6 4
4跳3步,与8比较,4<8,交换,再跳3步,与5比较,4<5,交换,再跳三步,越界,跳过
-- 1 5 3 2 4 7 6 8
-- 1 4 3 2 5 7 6 8
第一趟步长为3的插入排序结束了,第二趟开始,步长减小(可能是2)
......
直到步长为1的经典插入排序完成。
随着增量逐渐减少,每组包含的关键词越来越多,直到增量为1时,整个序列被分成一组。
步长选择越优的,排序的复杂度越小;反之越复杂(越趋近于O(n2)) -- 与步长的选择直接挂钩
增量的选取:一般初次取序列的一半为增量,以后每次减半,直到为1
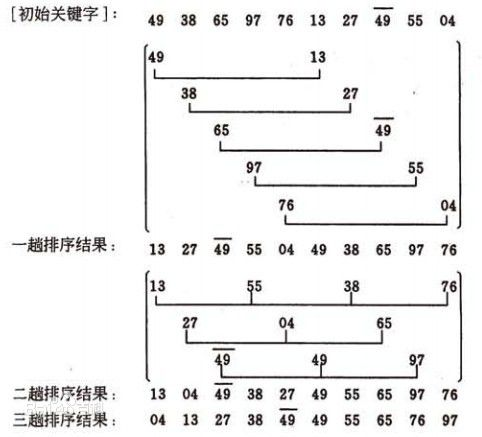
O(nlogn)
堆排序:
1. 将所有元素建立成一个大顶堆;2. 将堆顶(即为最大值)与堆的最后一个元素进行交换,并将最大值脱离堆结构,作为数组的有序部分
2. 将剩下的n-1个元素重新调整为一个大顶堆;2. 将堆顶与对的最后一个元素进行交换,得到的最值脱离堆作为数组有序部分
3. 直至堆的大小为1
能有效排序记录较多的数组
最坏情况下的时间复杂度仍为O(nlogn)
Java
数据库
操作系统
网络
设计模式
代码重用,保证代码可靠性,实现代码工程化
单例模式/单件模式/Singleton:
保证在整个应用程序的生命周期中,任何一个时刻,单例类的实例都只存在一个(或不存在)。
确保该类只有一个实例,并自行实例化,并向系统提供这个实例

uniqueInstance为单例实例对象,getInstance()用于获取实例化对象
构造函数必须为private,且必须提供一个全局访问点
public class Test { private Test() {} private static Test uniqueInstance = new Test(); public static Test getInstance() { return uniqueInstance; } }
工厂模式
用于实例化有大量公共接口的类,可以动态决定将哪一个类实例化,不必事先知道需要实例化哪一个类。
需要某种对象时,只需要向工厂提出请求即可。
简单工厂 Simple Factory
工厂方法 Factory Method
抽象工厂 Abstract Factory
适配器模式
观察者模式
面经:
0906完美世界牛人提前批完美X计划,这辈子第一次面试,面试官人很好很和蔼,上来让我自我介绍,之后说我游戏的项目很多,能不能做一些介绍。问了1. Unity的behavior的生命周期,表示不大清楚;2. 会不会C++,我说不会,面试官说国内学校把c++作为很重要的一门课,建议我可以学一些c++,3. c#熟悉不熟悉,回答不熟悉,因为unity的课程接触的c#;4. 其他语言如python等等的有没有做过什么项目,回答python是入学第一门学习的课程,项目的话做的是有关data processing的网站项目,然后问了我知道Python是怎么运行的吗,回答不清楚;面试官说可能国外和国内教授的课程内容不一样吧,你们偏向于实践,我大概了解你的情况了,跟别的同学相比你的项目经验非常丰富,但是我现在还不能给你面试结果,还需要比较一下其他应聘的同学,之后HR小姐姐会跟你联系。最后我问了问如果想要在游戏方面发展有什么建议吗: 需要学习的方向:GC c++ 基础概念 特性 模型 渲染流程 熟悉机制;游戏方面:北京广州公司手游unity ;网易偏向python。全程29分钟,我这辈子的第一次面试。