最近确定了自己未来职业规划。。。我要朝着大数据开发工程师努力,看下面的图谱,还差十万八千里(虽然不是所有都要会)!不过我不会气馁!加油!!!

总结如下:
必须技能10条:
01.Java高级(虚拟机、并发)
02.Linux 基本操作
03.Hadoop(此处为侠义概念单指HDFS+MapReduce+Yarn )
04.HBase(JavaAPI操作+Phoenix )
05.Hive(Hql基本操作和原理理解)
06.Kafka
07.Storm
08.Scala需要
09.Python
10.Spark (Core+sparksql+Spark streaming )
高阶技能6条:
11.机器学习算法以及mahout库加MLlib
12.R语言
13.Lambda 架构
14.Kappa架构
15.Kylin
16.Aluxio
二、学习路径
由于本人是从Java开发通过大概3个月的自学转到大数据开发的。所以我主要分享一下自己的学习路劲。
第一阶段:
01.Linux学习(跟鸟哥学就ok了)
02.Java 高级学习(《深入理解Java虚拟机》、《Java高并发实战》)
第二阶段:
03.Hadoop (董西成的书)
04.HBase(《HBase权威指南》)
05.Hive(《Hive开发指南》)
06.Scala(《快学Scala》)
07.Spark (《Spark 快速大数据分析》)
08.Python (跟着廖雪峰的博客学习就ok了)
第三阶段:
对应技能需求,到网上多搜集一些资料就ok了,
我把最重要的事情(要学什么告诉你了),
剩下的就是你去搜集对应的资料学习就ok了
当然如果你觉得自己看书效率太慢,你可以网上搜集一些课程,跟着课程走也OK 。这个完全根据自己情况决定。如果看书效率不高就很网课,相反的话就自己看书。
三,学习资源推荐:
01.Apache 官网
02.Stackoverflow
04.github
03.Cloudra官网
04.Databrick官网
05.过往的记忆(技术博客)
06.CSDN,51CTO
07.至于书籍当当一搜会有很多,其实内容都差不多。
作者:告小辞
链接:https://www.jianshu.com/p/1ce414d7ce88
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
1、Linux
大数据集群主要建立在linux操作系统上,Linux是一套免费使用和自由传播的类Unix操作系统。而这部分的内容是大家在学习大数据中必须要学习的,只有学好Linux才能在工作中更加的得心应手。
2、Hadoop
我觉的大家听过大数据就一定会听过hadoop。Hadoop是一个能够对大量数据进行离线分布式处理的软件框架,运算时利用mapreduce对数据进行处理。在大数据中的用途,以及快速搭建一个hadoop的实验环境,在本过程中不仅将用到前面的Linux知识,而且会对hadoop的架构有深入的理解,并为你以后架构大数据项目打下坚实基础。
3、HDFS系统
HDFS是建立在多台节点上的分布式文件系统,用户可以通过hdfs命令来操作分布式文件系统。学习这部分内容是可以帮助大家详细剖析HDFS,从知晓原理到开发网盘的项目让大家打好学习大数据的基础,大数据之于分布式,分布式学习从学习分布式文件系统(HDFS)开始。
4、Hive
Hive是使用sql进行计算的hadoop框架,工作中常用到的部分,也是面试的重点,此部分大家将从方方面面来学习Hive的应用,任何细节都将给大家涉及到。
5、Storm实时数据处理
本部分学习过后,大家将全面掌握Storm内部机制和原理,通过大量项目实战,让大家拥有完整项目开发思路和架构设计,掌握从数据采集到实时计算到数据存储再到前台展示,所有工作一个人搞定!譬如可以一个人搞定淘宝双11大屏幕项目!不光从项目的开发的层次去实现,并可以从架构的层次站在架构师的角度去完成一个项目。
6、spark
大数据开发中最重要的部分!本部分内容的学习主要是涵盖了Spark生态系统的概述及其编程模型,深入内核的研究,Spark on Yarn,Spark Streaming流式计算原理与实践,Spark SQL,Spark的多语言编程以及SparkR的原理和运行。不仅面向项目开发人员,甚至对于研究Spark的学员,此部分都是非常有学习指引意义的部分。
7、Docker技术
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app)。几乎没有性能开销,可以很容易地在机器和数据中心中运行。重要的是,他们不依赖于任何语言、框架包括系统。
以上知识点为笼统的总结,具体的学习思路可以找我获取!!!
当然除了这些知识点外还包括:redis、zookeeper、scala等等的,总之学习不可能一口吃个胖子。需要不断的积累总结,找到合适的学习资料和方法
大数据学习路线
java(Java se,javaweb)
Linux(shell,高并发架构,lucene,solr)
Hadoop(Hadoop,HDFS,Mapreduce,yarn,hive,hbase,sqoop,zookeeper,flume)
机器学习(R,mahout)
Storm(Storm,kafka,redis)
Spark(scala,spark,spark core,spark sql,spark streaming,spark mllib,spark graphx)
Python(python,spark python)
云计算平台(docker,kvm,openstack)
名词解释
一、Linux
lucene: 全文检索引擎的架构
solr: 基于lucene的全文搜索服务器,实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面。
二、Hadoop
HDFS: 分布式存储系统,包含NameNode,DataNode。NameNode:元数据,DataNode。DataNode:存数数据。
yarn: 可以理解为MapReduce的协调机制,本质就是Hadoop的处理分析机制,分为ResourceManager NodeManager。
MapReduce: 软件框架,编写程序。
Hive: 数据仓库 可以用SQL查询,可以运行Map/Reduce程序。用来计算趋势或者网站日志,不应用于实时查询,需要很长时间返回结果。
HBase: 数据库。非常适合用来做大数据的实时查询。Facebook用Hbase存储消息数据并进行消息实时的分析
ZooKeeper: 针对大型分布式的可靠性协调系统。Hadoop的分布式同步等靠Zookeeper实现,例如多个NameNode,active standby切换。
Sqoop: 数据库相互转移,关系型数据库和HDFS相互转移
Mahout: 可扩展的机器学习和数据挖掘库。用来做推荐挖掘,聚集,分类,频繁项集挖掘。
Chukwa: 开源收集系统,监视大型分布式系统,建立在HDFS和Map/Reduce框架之上。显示、监视、分析结果。
Ambari: 用于配置、管理和监视Hadoop集群,基于Web,界面友好。
二、Cloudera
Cloudera Manager: 管理 监控 诊断 集成
Cloudera CDH:(Cloudera's Distribution,including Apache Hadoop) Cloudera对Hadoop做了相应的改变,发行版本称为CDH。
Cloudera Flume: 日志收集系统,支持在日志系统中定制各类数据发送方,用来收集数据。
Cloudera Impala: 对存储在Apache Hadoop的HDFS,HBase的数据提供直接查询互动的SQL。
Cloudera hue: web管理器,包括hue ui,hui server,hui db。hue提供所有CDH组件的shell界面的接口,可以在hue编写mr。
三、机器学习/R
R: 用于统计分析、绘图的语言和操作环境,目前有Hadoop-R
mahout: 提供可扩展的机器学习领域经典算法的实现,包括聚类、分类、推荐过滤、频繁子项挖掘等,且可通过Hadoop扩展到云中。
四、storm
Storm: 分布式,容错的实时流式计算系统,可以用作实时分析,在线机器学习,信息流处理,连续性计算,分布式RPC,实时处理消息并更新数据库。
Kafka: 高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据(浏览,搜索等)。相对Hadoop的日志数据和离线分析,可以实现实时处理。目前通过Hadoop的并行加载机制来统一线上和离线的消息处理
Redis: 由c语言编写,支持网络、可基于内存亦可持久化的日志型、key-value型数据库。
五、Spark
Scala: 一种类似java的完全面向对象的编程语言。
jblas: 一个快速的线性代数库(JAVA)。基于BLAS与LAPACK,矩阵计算实际的行业标准,并使用先进的基础设施等所有的计算程序的ATLAS艺术的实现,使其非常快。
Spark: Spark是在Scala语言中实现的类似于Hadoop MapReduce的通用并行框架,除了Hadoop MapReduce所具有的优点,但不同于MapReduce的是job中间输出结果可以保存在内存中,从而不需要读写HDFS,因此Spark能更好的适用于数据挖掘与机器学习等需要迭代的MapReduce算法。可以和Hadoop文件系统并行运作,用过Mesos的第三方集群框架可以支持此行为。
Spark SQL: 作为Apache Spark大数据框架的一部分,可用于结构化数据处理并可以执行类似SQL的Spark数据查询
Spark Streaming: 一种构建在Spark上的实时计算框架,扩展了Spark处理大数据流式数据的能力。
Spark MLlib: MLlib是Spark是常用的机器学习算法的实现库,目前(2014.05)支持二元分类,回归,聚类以及协同过滤。同时也包括一个底层的梯度下降优化基础算法。MLlib以来jblas线性代数库,jblas本身以来远程的Fortran程序。
Spark GraphX: GraphX是Spark中用于图和图并行计算的API,可以在Spark之上提供一站式数据解决方案,可以方便且高效地完成图计算的一整套流水作业。
Fortran: 最早出现的计算机高级程序设计语言,广泛应用于科学和工程计算领域。
BLAS: 基础线性代数子程序库,拥有大量已经编写好的关于线性代数运算的程序。
LAPACK: 著名的公开软件,包含了求解科学与工程计算中最常见的数值线性代数问题,如求解线性方程组、线性最小二乘问题、特征值问题和奇异值问题等。
ATLAS: BLAS线性算法库的优化版本。
Spark Python: Spark是由scala语言编写的,但是为了推广和兼容,提供了java和python接口。
六、Python
Python: 一种面向对象的、解释型计算机程序设计语言。
七、云计算平台
Docker: 开源的应用容器引擎
kvm: (Keyboard Video Mouse)
openstack: 开源的云计算管理平台项目
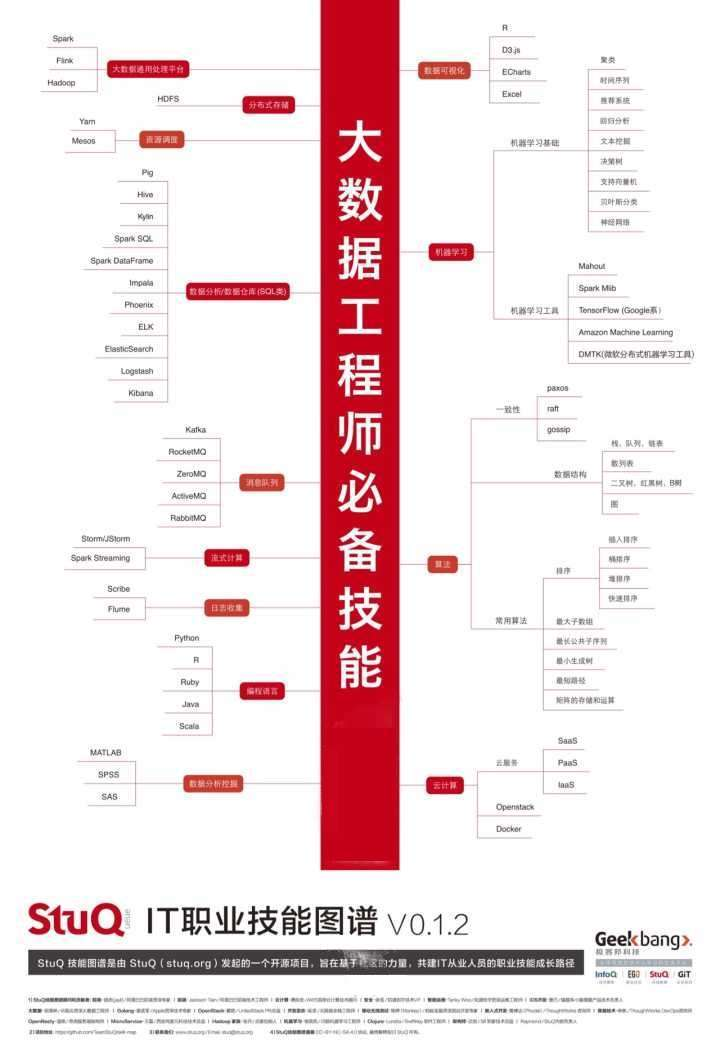
一、大数据通用处理平台
1. Spark
2. Flink
3. Hadoop
二、分布式存储
HDFS
三、资源调度
1、Yarn
2、Mesos
四、机器学习工具
Mahout
1. Spark Mlib
2. TensorFlow (Google 系)
3. Amazon Machine Learning
4. DMTK (微软分布式机器学习工具)
五、数据分析/数据仓库(SQL类)
1. Pig
2. Hive
3. kylin
4. Spark SQL,
5. Spark DataFrame
6. Impala
7. Phoenix
8. ELK
8.1 ElasticSearch
8.2Logstash
8.3Kibana
六、消息队列
1. Kafka(纯日志类,大吞吐量)
2. RocketMQ
3. ZeroMQ
4. ActiveMQ
5. RabbitMQ
七、流式计算
1. Storm/JStorm
2. Spark Streaming
3. Flink
八、日志收集
Scribe
Flume
久、编程语言
1. Java
2. Python
3. R
4. Ruby
5. Scala
十、数据分析挖掘
MATLAB
SPSS
SAS
十一、数据可视化
1. R
2. D3.js
3. ECharts
4. Excle
5. Python
十二、机器学习
机器学习基础
1. 聚类
2. 时间序列
3. 推荐系统
4. 回归分析
5. 文本挖掘
6. 决策树
7. 支持向量机
8. 贝叶斯分类
9. 神经网络
机器学习工具
1. Mahout
2. Spark Mlib
3. TensorFlow (Google 系)
4. Amazon Machine Learning
5. DMTK (微软分布式机器学习工具)
十三、算法
一致性
1. paxos
2. raft
3. gossip
数据结构
1. 栈,队列,链表
2. 散列表
3. 二叉树,红黑树,B树
4. 图
常用算法
1.排序
插入排序
桶排序
堆排序
2.快速排序
3,最大子数组
4.最长公共子序列
5.最小生成树
最短路径
6.矩阵的存储和运算
十四、云计算
云服务
1. SaaS
2. PaaS
3. IaaS
4. Openstack
5. Docker