不得不说shell语法是丑陋的,操作是简单高效的,最后一次学习总结shell
字符串删除与替换等常见操作
## 字符串长度
a=1234
echo "${#a}"
expr length "${a}"
## 字符串 索引
expr index ${a} 23 # 拆分 2 3 一个个查找找到第一个匹配的就返回
## 字符串 匹配 有问题?
expr match ${a} 123 # 从头开始匹配 可以联想 match search findall
## substring
echo ${a:2:3} #--> 3,4
echo ${a: -3} # --> 反向,特别注意冒号后有空格
或者写成
echo ${a:(-3)}
echo ${a:(-3):2} # ${} 下标是从 0 开始, expr 却是从1开始,已经无力吐槽!!!丑陋的shell!!!
expr substr ${a} 2 3 -->234
b="I love you! Do you love me?""${b#*ove}" # 正向非贪婪 删除 到ove截止 --》 you! Do you love me?
echo "${b##*ove}" # 正向贪婪 删除 到ove截止 --》 me?
echo "${b%ove*}" # 反向也就是从右到左非贪婪到ove --》 I love you! Do you l
echo "${b%%ove*}" # 反向也就是从右到左贪婪到ove --》 I
##--替换--##
echo "${PATH/bin/BIN}" # 正向非贪婪替换小写bin -》 大写 BIN
echo "${PATH//bin/BIN}" # 正向贪婪替换小写bin -》 大写 BIN
l
字符串变量测试 很麻烦不做掌握要求
字符串作业
#!/bin/sh
:<<EOF
需求描述:
变量 string="Bigdata process framework is Hadoop,Hadoop is an open source project."
执行脚本后, 打印输出 string字符串变量,并给出用户以下选项:
(1) 打印string长度
(2) 删除字符串中所有的Hadoop
(3) 替换第一个Hadoop为Mapreduce
(4) 替换全部Hadoop为Mapreduce
用户输入数字 1|2|3|4 执行对应项的功能, 输入 q|Q 退出交互模式
EOF
string="Bigdata process framework is Hadoop,Hadoop is an open source project."
while :
do
read -p "请选择要执行的选项:
(1) 打印string长度
(2) 删除字符串中所有的Hadoop
(3) 替换第一个Hadoop为Mapreduce
(4) 替换全部Hadoop为Mapreduce
" choice
echo "choice: ${choice}"
case "${choice}" in
[qQ]) exit;;
1) echo "string长度: ${#string}";;
2) echo "删除字符串中所有的Hadoop: ${string##*Hadoop}";;
3) echo "替换第一个Hadoop为Mapreduce: ${string/Hadoop/Mapreduce}";;
4) echo "替换全部Hadoop为Mapreduce: ${string//Hadoop/Mapreduce}";;
*) echo "请输入 1 or 2 or 3 or 4"
esac
done
# 启停 脚本
#!/bin/bash
AI_HOME=/opt/jintel/modeler/pycohortquery
STARTAI=${AI_HOME}/start_ai_service.sh
STOPAI=${AI_HOME}/stop_ai_service.sh
case $1 in
start|Start)
echo "start ai service"
$STARTAI
;;
stop|Stop) echo "stop ai service"
$STOPAI
;;
*) echo "not support operation..."
esac
命令替换
`command` --> date
$(command) --> ${date}
$(()) <==> $[] # 做数字运算
echo "this is $(date +%Y) year"
this is 2019 year
echo "this is $(($(date +%Y) + 1)) year"
this is 2020 year
echo "this is $[$(date +%Y) + 1] year"
this is 2020 year
num=1
((num++)) --> num=$[num+1] --> num=$(($num+1))
((num--))
在今年已经过了 echo $[$(date +%j) / 7] 天 /7 == 过了的星期数
31
echo $[(365-$(date +%j)) / 7] ==》 今年还剩下星期数
#!/bin/sh
index=1
for user in `cat /etc/passwd|cut -d ":" -f 1`; do
echo "${index} -> ${user}"
index=$((${index}+1))
#index=$[index+1]
done
# 判断 , 拉起守护进程
if [ $(ps -ef|grep nginx|grep -v grep|wc -l) -eq 0 ]; then
echo "0"
systemctl start nginx # 守护进程代码
fi
有类型变量
declare -r var="hello world!" # 只读
declare -i num_3=20 # 声明为整型
declare -f # 把系统提供的所有可用函数以及内容显示
declare -F # 把系统提供的所有可用函数仅仅显示 函数名
declare-a array
## 数组的常见操作 ${#array[@]} --> 数组长度 ${#array[1]} --> 第二个元素的字符长度
一般可以认为数组操作与字符串操作类似
declare -x ==》 export
bash 数学运算

#!/bin/sh
:<<EOF
输入一个正整数 num 然后计算 1+2+3+...+num 的值, 必须对 num是否为正整数做判断不符合应当允许再次输入
EOF
func_tips(){
echo "输入一个正整数 num 然后计算 1+2+3+...+num 的值, 必须对 num是否为正整数做判断不符合应当允许再次输入"
}
func_sum(){
num=$1
sum=0
while [ $num -gt 0 ];
do
echo "num now is $num"
sum=`expr $sum + $num`
((num--))
done
echo "sum is ${sum}"
#printf("sum is %d",sum)
}
func_tips
while true;
do
read -p "请输入一个正整数: " num
expr $num + 1 &> /dev/null
if [ $? -ne 0 ]; then
continue
fi
flag=`expr $num > 0`
if [ ${flag} -eq 1 ]; then
func_sum $num
break
exit 0
fi
done
今天编写shell脚本。想要程序在运行到一个地方的时候进行判断,结果为真退出程序。运行时直接退出了SecureCRT终端。纠结了一整个上午也没有找到解决方案。
中午在同事的示范下发现并不是脚本的问题。而是执行方式的问题。
Linux执行文件有如下几种方式:
(1)./xxx.sh意思是执行当前目录的a.sh文件,与输入完整路径执行脚本效果是一样的。需要a.sh有可执行权限。
(2)sh xxx.sh意思是用shell解释器来执行a.sh脚本,不要求文件有可执行权限。
(3). xxx.sh和source效果相同,作用都是使刚修改过的配置文件立即生效。
shell中使用source conf.sh,是直接运行conf.sh的命令,不创建子shell,source不是直接执行一个文件,而是从一个文本文件里面读命令行,然后执行这些命令。我执行的时候使用了 . XX.sh,这样相当于直接系统读取exit,然后退出,正确的运行方式是 ./XX.sh 或者sh XX.sh
sh是则创建子shell,子shell里面的变量父shell无法使用,对环境变量的修改也不影响父shell。父shell中的局部变量,子shell也无法使用,只有父shell的环境变量,子shell能够使用.
bc bash 内建 计算器 可以计算浮点类型
echo "scale=4;24/3" | bc # 保留四位有效数字的 除法
自定义守护进程
#!/bin/bash
this_pid=$$
while true;
do
ps -ef|grep ml_pluginxxx.jar|grep -v grep|grep -v ${this_pid} &>/dev/null
if [ $? -eq 1 ]; then
sudo nohup xxx.jar>/dev/null 2>&1 &
fi
done
shell版 简单四则运算
#!/bin/bash
func_tips(){
echo "请按照如下格式输入要计算的式子 10 + 20 "
}
function func_calculate {
echo $2
case "$2" in
+|-|/) echo "$1 $2 $3 = `expr $1 $2 $3`";;
\*) echo "$1 * $3 = `expr $1 * $3`";;
*) echo "no support operators...";;
esac
}
main_process(){
func_tips
func_calculate $1 $2 $3
}
main_process $1 $2 $3
函数的 返回有两种 return 0 , >0 的状态值, 或者 echo 返回一个 list用于返回数据在别处使用
定义自己的 函数库 . /root/lib/myshlib/basefunc.lib 引入
友好的高亮显示
#!/bin/sh
#定义颜色变量
RED='E[1;31m' # 红
GREEN='E[1;32m' # 绿
YELOW='E[1;33m' # 黄
BLUE='E[1;34m' # 蓝
PINK='E[1;35m' # 粉红
RES='E[0m' # 清除颜色
#用echo -e来调用
echo -e "${RED} this is red color ${RES}"
echo -e "${GREEN} this is green color ${RES}"
echo -e "${YELOW} this is red yelow ${RES}"
echo -e "${BLUE} this is blue color ${RES}"
echo -e "${PINK} this is pink color ${RES}"
find 命令 , 记住 常用参数即可
find / -maxdepth|-mindepth 2 -iname *log.txt -type -f -mtime +5 -print0 -ok '' # 随便写的 需要再次补充
文本处理 无外乎 增删改查
文本处理三剑客 grep + sed + awk ==> 这些如果细究可以写一本书了,我们这里只能是浅尝。。。用到特别复杂的情况时去翻看字典就好
grep 这一块 最复杂的情况还是在 正则表达式的书写

grep -inrwcE "nltk|NLTK" ./FirstNLP/
-v 不显示匹配航信息
-i 忽略大小写
-n 显示匹配到的行号
-r 递归查找文本内容
-w 整词匹配
-c 只显示匹配行的总数
-E extended regex
-F Not extended regex 费扩展正则 ,仅按照字面意思匹配
-X 整行匹配
-l 只列出匹配到的文件名
-s 不显示错误信息
sed stream editor <== vim ,可对 字符串做 替换删除 append 等操作

sed.txt :
I love python
I love PYTHON
I love python
sed -n -e '/PYTHON/p' -e '/python/p' sed.txt
# 从文件里使用匹配模式及命令
sed -n -f edit.sed sed.txt
# enable 扩展表达式 -r
sed -n -r -e '/python|PYTHON/p' sed.txt
# 替换
sed -n -e 's/love/like/g;p' sed.txt
# 复杂一些的 匹配
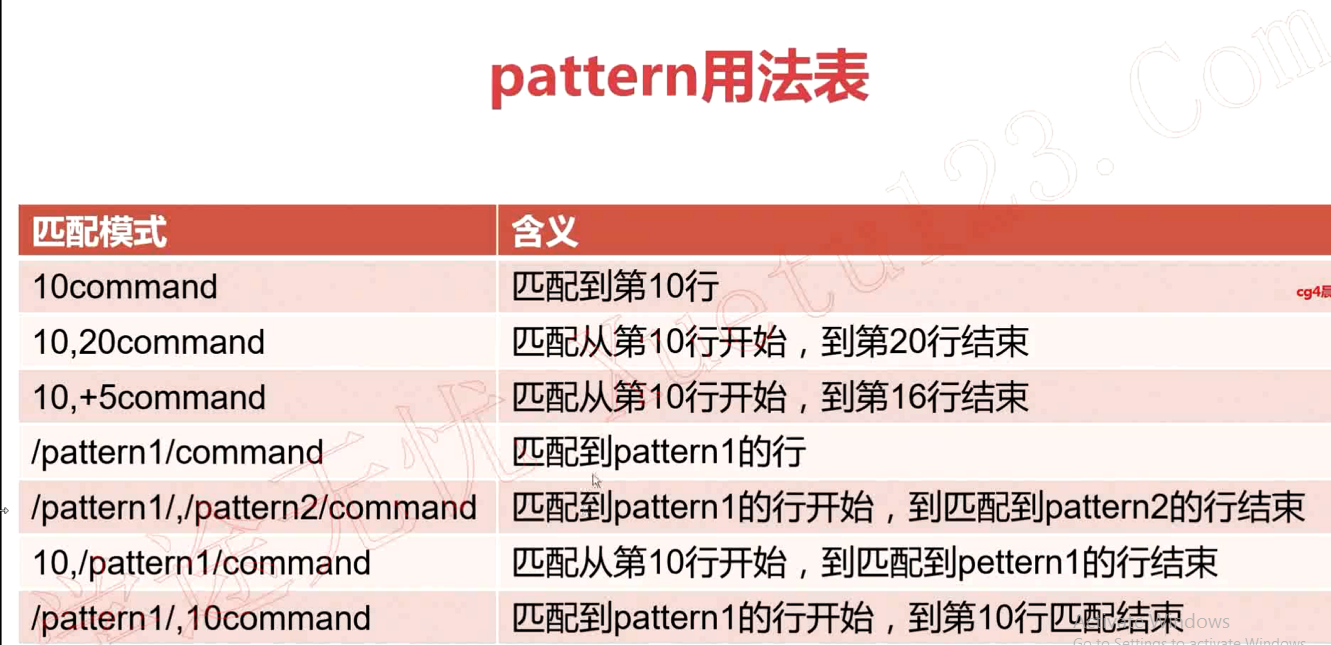
# 打印某一行 ,打印某个区间内的行
sed -n '1p' /etc/passwd
sed -n '1,5p' /etc/passwd
sed -n '5,+6p' /etc/passwd
sed -n '/^ambari/,/^gnome/p' /etc/passwd , 打印 从匹配 pattern1 的行 到 匹配 pattern2 的行
# 查找 没有登录权限的账户
sed -n '//sbin/nologin/p' /etc/passwd
# 从 第一行开始直到匹配 到 gnome 模式的行 打印
sed -n '1,/gnome/p' /etc/passwd
# 从匹配到 ambari 的行开始 到 26 行 进行打印
sed -n '/ambari/,26p' /etc/passwd
# 匹配两个 匹配模式之间的行
sed -n '/^root/,/^ambari/p' passwd
sed -n '8,//sbin/nologin/p' passwd
sed -n '//bin/bash/,5p' passwd
# 在此之前 我们可以 借助 grep -n 'ambari' /etc/passwd 查看 行号再做决定

# 更加复杂的操作 如 s// i a r w d
cp /etc/passwd ~/test/
sed -i '//sbin/nologin/d' passwd # 删除 符合匹配模式的 行
sed -i '//bin/bash/a This is user which can login to system' passwd # 在符合匹配模式的行后追加
sed -i '//sbin/nologin/i who cannot login to system' passwd # 在符合匹配模式的行前插入
append.txt:
append text
sed -i '//sbin/nologin/r append.txt' passwd # 从文件里 读取要被 append 的文本
sed -i '//bin/bash/w /tmp/user_login_2.txt' passwd # 将符合匹配模式的行 写入某个文件
sed -i 's/games/play games/2ig' passwd # 忽略大小写查找替换从第 2 个开始的所有 games 为 play games
sed -n '//sbin/nologin/=' passwd
# 分组捕获做替换 & 1 ==> 不同的是 1 需要前面 加 括号 但是更加灵活 可以 括起来一部分
I like HadAAp.
I like HadBBp.
I like HadCCp.
I like HadDDp.
I like HadEEps.
I like hadAAp.
I like hadBBp.
I like hadCCp.
I like hadDDp.
sed -i 's/Had..p/&s/g' hadooptest.txt
sed -i 's/had(..)p/123(1)456/g' hadooptest.txt
sed -i -r 's/123(..)456/hadoop/g' hadooptest.txt # 技巧 , 模式不确定情况下 可以 -n p 这样 先 打印一下下
my.cnf
sed -r -n '/^[.*?]/w tempmysql.cnf' my.cnf
sed -n -r '/^[.*?]/p' my.cnf |sed 's/[(.*)]/1/g'
my.cnf
[mysqld]
user = mysql
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
pid-file = /usr/local/mysql/mysql.pid
socket=/usr/local/mysql/mysql.sock
[server]
ab
cd
ef
[socket]
jho
lhi
[unknown]
fasdf
vdvadf
#!/bin/bash
func_list_segments(){
echo "`sed -n -r '/^[.*?]/p' my.cnf |sed 's/[(.*)]/1/g'`"
}
func_get_itemcounts(){
index=0
items=`sed -n '/['$1']/,/[.*]/p' my.cnf `
for item in ${items};
do
index=$[index+1]
done
echo "$1: $index"
}
func_get_itemcounts mysqld
number=0
for segment in `func_list_segments`;
do
number=`expr ${number} + 1`
echo "$number: `func_get_itemcounts ${segment}`"
#echo "配置项 : ${segment}"
done
# 删除 注释 以及 空行
sed -i -e '/^#/d' -e '/^$/d' my.cnf
sed -i -e '/^[:blank:]*#/d' -e '/^$/d' my.cnf
sed -i -e '/^[:blank:]*#/d;/^$/d' my.cnf
# 非以 # 开头的 行 前面 加 * 号
sed -i 's/^[^#]/*&/g' my.cnf
awk 报表生成 神器

awk 'BEGIN{FS=":"}$3<=100 && $3>=50{print $0}' /etc/passwd
awk -F ":" '{if($3>=50 && $3<=100){print $0}}' /etc/passwd
保存为 statisticuser.awk 然后 用 awk -f 命令执行
BEGIN{
FS=":"
}
{
if($3<=50){
printf("%-20s%-20s%-5d
", "UID <= 50", $1, $3)
}
}
awk -f statisticuser.awk /etc/passwd
scores.txt
Allen 80 90 96 98
Mike 93 98 92 91
Zhang 78 76 87 92
Jerry 86 89 68 92
Han 85 95 75 90
Li 78 88 98 100
# 打印出 平均分 大于 90 的 人的信息
BEGIN{
printf("%-20s%-10s%-10s%-10s%-10s%-10s
", "Name", "Chinese", "English","Math","GM","AVG_SCORE")
}
{
total_score=0
for(i=1;i<=NF;i++){
total_score=total_score+$i
}
avg_score=total_score/(NF-1)
if(avg_score>90){
printf("%-20s%-10s%-10s%-10s%-10s%-10s
", $1,$2,$3,$4,$5,avg_score)
}
}
END{
}
awk 中的 字符串函数
length(str) 计算长度
1、 以 : 为分隔符, 返回 /etc/passwd 中每行中每个字段的 长度
#为分隔符, 返回 /etc/passwd 中每行中每个字段的 长度
BEGIN{FS=":"}
{
for(i=1;i<=NF;i++){
if(i!=NF){
printf("%-5d:", length($i))
}else{
printf("%-5d
", length(i))
}
}
}
awk -f len4eachcol.awk /etc/passwd
index(str1, str2) 返回在 str1 中查询到的 str2 的位置
awk '{printf("index is: %d ", index($0,"ea"))}' <<EOF
> "I have a dream"
> EOF
awk 'BEGIN{str="I have a dream";printf("index is: %-5d
",index(str,"ea"))}'
tolower(str) 小写转换
awk 'BEGIN{str="Hadoop is a bigdata Framework";printf("%-20s
", tolower(str))}'
toupper(str) 大写转换
awk 'BEGIN{str="Hadoop is a bigdata Framework";printf("%-20s
", toupper(str))}'
split(str,arr,fs) 分隔 字符串 , 并保存到数组中
awk 'BEGIN{str="Hadoop is a bigdata Framework"; split(str,ary," "); for(a in ary){printf("%-10s
",ary[a])}}'
match(str,regEx) 返回正则表达式匹配到的子串的位置
awk 'BEGIN{str="abc 1233 efag";printf("%-5d
" , match(str,/[0-9]/))}'
substr(str,m,n) 截取子串, 从 m 个字符开始 截取 n 位。 若 n 不指定 则 默认 截取到最后?
awk 'BEGIN{str="abc12345efg";printf("从第四位开始截取五位: %-10s
" , substr(str,4,5))}'
sub(RegEx,RepStr,str) 替换查找到的第一个子串
awk 'BEGIN{str="abc123efg456hij789lmn";sub(/[0-9]+/,"\d",str); printf("%-10s
",str)}'
gsub(RegEx,RepStr,str) 替换查找到的所有子串
awk 'BEGIN{str="abc123efg456hij789lmn";gsub(/[0-9]+/,"\d",str); printf("%-10s
",str)}'
# awk 自身参数
-v 传入外部 参数
num1=20
var="hello world"
awk -v num2="$num1" -v var_1="$var" 'BEGIN{ print num2, var_1}'
-V 查看 版本号
-f 从文件里 执行 awk
-F ":" 《==》 FS=":"
awk 实战
生成数据的脚本:insert.sh
#!/bin/bash
function create_random {
min=$1
max=$(($2-$min+1))
num=$(date +%s%N)
echo $(($num%$max+$min))
}
INDEX=1
while true
do
for user in Mike Allen Jerry Tracy Hanmeimei Lilei
do
COUNT=$RANDOM
NUM1=`create_random 1 $COUNT`
NUM2=`expr $COUNT - $NUM1`
echo "`date "+%Y-%m-%d %H:%M:%S"`" $INDEX Batches: $user insert $COUNT data into table 'test1', insert $NUM1 records successfully, failed insert $NUM2 records >> /root/script/data.txt
INDEX=`expr $INDEX + 1`
done
done
(1)、统计每个人员插入了多少条数据进数据库
awk 'BEGIN{printf "%-10s %-10s
","name","total"}{stat[$5]+=$7}END{for(i in stat){printf "%-10s %-10s
",i,stat[i]}}' data.txt
# awk 里的数组 好比 Python 中的 字典
awk '{ary[$5]+=$7;}END{for (a in ary){printf("%-10s insert %-20d data rows
",a,ary[a])}}' data.txt
(2)、统计每个人员插入成功和失败了多少条数据进数据库
awk 'BEGIN{printf "%-10s %-10s %-10s %-10s
","User","Total","Succeed","Failed"}{sum[$5]+=$7;suc_sum[$5]+=$13;fail_sum[$5]+=$18}END{for(i in sum){printf "%-10s %-10s %-10s %-10s
",i,sum[i],suc_sum[i],fail_sum[i]}}' data.txt
awk 'BEGIN{printf("%-20s %-20s %-20s
","name","insert rows","failed rows")}{insert[$5]=$7;failed[$5]=$18}END{for(a in insert){printf("%20s %-20s %-20s
",a,insert[a], failed[a])}}' data.txt
(3)、在(2)的基础上统计全部插入记录数
awk 'BEGIN{printf "%-10s %-10s %-10s %-10s
","User","Total","Succeed","Failed"}{sum[$5]+=$7;suc_sum[$5]+=$13;fail_sum[$5]+=$18}END{for(i in sum){all_sum+=sum[i];all_suc_sum+=suc_sum[i];all_fail_sum+=fail_sum[i];printf "%-10s %-10s %-10s %-10s
",i,sum[i],suc_sum[i],fail_sum[i]};printf "%-10s %-10s %-10s %-10s
","",all_sum,all_suc_sum,all_fail_sum}' data.txt
(4)、查找丢失数据,也就是成功+失败的记录数不等于总共插入的记录数
awk '{if($7!=$13+$18){print $0}}' data.txt
awk '{ary[$5]+=$7;}END{for (a in ary){printf("%-10s insert %-20d data rows
",a,ary[a])}}' data.txt
操作 Mysql 数据库
yum list all|grep mariadb
yum install mariadb mariadb-server mariadb-libs -y
systemctl status mariadb # 查看 mariadb 服务状态
systemctl start mariadb
mysql 直接可以进入 mysql 交互界面
create database school default character set utf8;
预准备 sql 脚本 与 测试数据
CREATE TABLE `student`(
`s_id` VARCHAR(20),
`s_name` VARCHAR(20) NOT NULL DEFAULT '',
`s_birth` VARCHAR(20) NOT NULL DEFAULT '',
`s_sex` VARCHAR(10) NOT NULL DEFAULT '',
PRIMARY KEY(`s_id`)
);
CREATE TABLE `course`(
`c_id` VARCHAR(20),
`c_name` VARCHAR(20) NOT NULL DEFAULT '',
`t_id` VARCHAR(20) NOT NULL,
PRIMARY KEY(`c_id`)
);
CREATE TABLE `teacher`(
`t_id` VARCHAR(20),
`t_name` VARCHAR(20) NOT NULL DEFAULT '',
PRIMARY KEY(`t_id`)
);
CREATE TABLE `score`(
`s_id` VARCHAR(20),
`c_id` VARCHAR(20),
`s_score` INT(3),
PRIMARY KEY(`s_id`, `c_id`)
);
INSERT INTO student values('1001', 'zhaolei', '1990-1001-1001', 'male');
INSERT INTO student values('1002', 'lihang', '1990-12-21', 'male');
INSERT INTO student values('1003', 'yanwen', '1990-1005-20', 'male');
INSERT INTO student values('1004', 'hongfei', '1990-1008-1006', 'male');
INSERT INTO student values('1005', 'ligang', '1991-12-1001', 'female');
INSERT INTO student values('1006', 'zhousheng', '1992-1003-1001', 'female');
INSERT INTO student values('1007', 'wangjun', '1990-1007-1001', 'female');
INSERT INTO student values('1008', 'zhoufei', '1990-1001-20', 'female');
-- 课程表测试数据
INSERT INTO course values('1001','chinese','1002');
INSERT INTO course values('1002','math','1001');
INSERT INTO course values('1003','english','1003');
--教师表测试数据
insert into teacher values('1001','Frank Li');
insert into teacher values('1002','Tom Hansome');
insert into teacher values('1003','Jim Green');
--成绩表测试数据
INSERT INTO score values('1001', '1001', 80);
INSERT INTO score values('1001', '1002', 90);
INSERT INTO score values('1001', '1003', 99);
INSERT INTO score values('1002', '1001', 70);
INSERT INTO score values('1002', '1002', 60);
INSERT INTO score values('1002', '1003', 80);
INSERT INTO score values('1003', '1001', 80);
INSERT INTO score values('1003', '1002', 70);
INSERT INTO score values('1003', '1003', 70);
INSERT INTO score values('1004', '1001', 50);
INSERT INTO score values('1004', '1002', 30);
INSERT INTO score values('1004', '1003', 20);
INSERT INTO score values('1005', '1001', 76);
INSERT INTO score values('1005', '1002', 87);
INSERT INTO score values('1006', '1001', 31);
INSERT INTO score values('1006', '1002', 34);
INSERT INTO score values('1007', '1001', 89);
INSERT INTO score values('1007', '1002', 98);
mysql school <school.sql
grant all on school.* to dbuser@'localhost' identified by '123456';
mysql -u dbuser -p -h localhost -D school
mysql -udbuser -p123456 -h localhost -D school -e "select * from student;"
students.txt:
1001 zhaolei 1990-1001-1001 male
1002 lihang 1990-12-21 male
1003 yanwen 1990-1005-20 male
1004 hongfei 1990-1008-1006 male
1005 ligang 1991-12-1001 female
1006 zhousheng 1992-1003-1001 female
1007 wangjun 1990-1007-1001 female
1008 zhoufei 1990-1001-20 female
从 linux 本地文件 (最好是 tab 分割) 导入数据到 mysql 表
create table student1 like student;
#!/bin/bash
user=dbuser
password=123456
host=localhost
db=school
tab_name=student
cat students.txt |while read sid sname sbirth sgender
do
conn_mysql=`mysql -u"$user" -p"$password" -h $host -D $db -e "INSERT INTO student1 values('$sid','$sname','$sbirth','$sgender')"`
done
到处数据库中的数据 mysqldump
mysqldump -udbuser -p123456 -hlocalhost school >school_dump.sql
mysqldump -udbuser -p123456 -hlocalhost school student >student_dump.sql
### dump 导出 并 ftp 传输备份
#!/bin/bash
user=dbuser
password=123456
host=localhost
db=school
tab_name=score
out_file="$db"_"$tab_name"_name.sql
ftp_server=192.168.184.3
ftp_user=ftpuser
ftp_password=ftppsw
dst_dir=/data/backup/
if [ -n $tab_name ];then
echo "$out_file"
mysqldump -u"$user" -p"$password" -h"$host" "$db" "$tab_name" > "$out_file"
ftp -in << EOF
open "$ftp_server"
user "$ftp_user" "$ftp_password"
cd "$dst_dir"
put "$out_file"
bye
EOF
fi
并配合 crontab 定时任务 即可 完成相对复杂的运维工作



添加开机自启动
step 0 create a shell script
#!/bin/bash
cd /opt/jintel/modeler/ && sudo nohup java -jar ml-plugin-0.0.1-SNAPSHOT.jar >/dev/null 2>&1 &
step 1 copy shell script and add execute permission
sudo cp start_modeler.sh /etc/rc.d/init.d/
cd /etc/rc.d/init.d/
sudo chmod +x start_modeler.sh
step 2 add chkconfig info
vim or gedit start_modeler.sh add chkconfig and description as below
add chkconfig info
#!/bin/bash
# chkconfig: 2345 10 90
# description: aiwebservice
cd /opt/jintel/modeler/ && sudo nohup java -jar ml-plugin-0.0.1-SNAPSHOT.jar >/dev/null 2>&1 &
step 3 config auto start on server restart
sudo chkconfig --add start_modeler.sh
sudo chkconfig start_modeler.sh on
关闭端口命令 开启 端口命令
sudo iptables -I INPUT -p tcp --dport [port] -j ACCEPT
iptables -A OUTPUT -p tcp --dport 端口号-j DROP
如 sudo iptables -I INPUT -p tcp --dport 8080 -j ACCEPT 开放8080端口
查看端口号状态 netstat -nat | grep 8080
service iptables save 保存设置
查看所有开启端口
查询 netstat -anp 所有开放端口信息
curl -X POST -H "Content-type: application/json" http://xxx:8999/MachineLearning/Result -d '{ "model_id":1874}' -w 'time_connect %{time_connect}
time_starttransfer %{time_starttransfer}
time_total %{time_total}
'