程序
程序:编写完的代码称为程序。
进程
进程:又称重量级进程,正在执行中的程序称为进程。进程的执行会占用内存等资源。多个进程同时执行时,每个进程的执行都需要由操作系统按一定的算法(RR调度、优先数调度算法等)分配内存空间。
并行与并发
并行:在多核系统中,每个cpu执行一个进程,可以理解为cpu的数大于进程数,所有进程同时进行。
并发:在操作系统中同时执行多个进程,可以理解为cpu的数小于进程数,有些进程会没有机会执行。
并发与并行的区别:并行指两个或多个程序在同一时刻执行;并发指两个或多个程序在同一时间间隔内发生,可以理解为在表面上看是同时进行,但在同一时刻只有少于程序的总数的程序在执行,计算机利用自己的调度算法让这些程序分时的交叉执行,由于交换的时间非常短暂,宏观上就像是在同时进行一样。
多进程
在python中,每一个运行的程序都有一个主进程,可以利用模块中封装的方法来创建子进程。
1、利用os模块中的fork()来创建子进程
import os, time pid = os.fork() print("外面的pid",pid) if pid == 0: print("子进程中的程序") print("子进程的pid=", os.getpid()) print("父进程的pid=", os.getppid()) elif pid > 0: print("父进程中的程序") print("子进程的pid=", os.getpid()) print("父进程的pid=", os.getppid()) else : print("创建失败")
解释:
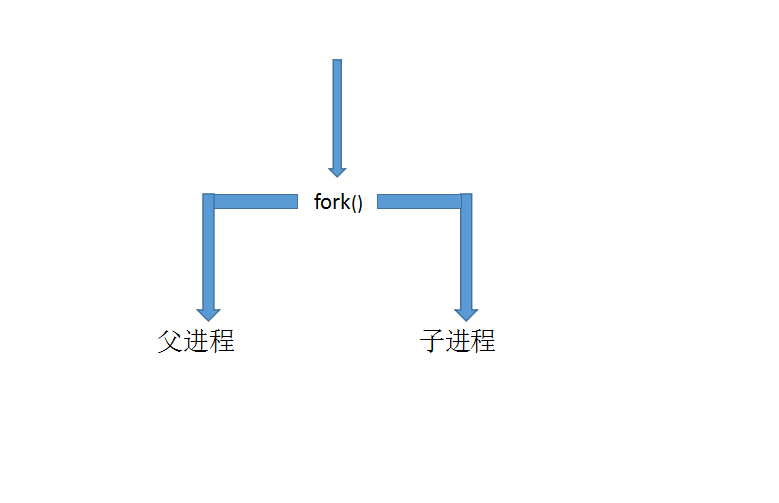
os.fork():os模块中用来创建子进程的方法,当程序执行到os.fork()时,操作系统会将当前的进程复制一份,原来的进程称为父进程,新创建的进程称为子进程,两个进程会各自互不干扰的执行下面的程序,父进程与子进程的执行顺序与系统调度有关。父进程与子进程都会在os.fork()中得到一个返回值,子进程的返回值为0,父进程的返回值为子进程的进程号,这个值永远大于零,具体数值由操作系统分配,如果返回值为负数则表明创建子进程失败。
os.getpid():获取进程的进程号。
os.getppid():获取父进程的进程号。
注意:这个os.fork()方法只有在unix系统中才会有,在window下没有。
2、利用multiprocessing模块Process类创建进程
在multiprocessing模块中提供一个Process()类来创建进程,直接上代码:
from multiprocessing import Process import time def test(a): for i in range(a): print("子进程...") time.sleep(1) p = Process(target=test,args=(5,)) p.start() p.join(2) while True: print("父进程...") time.sleep(1)
解释:
这里的p相当于Process类的一个实例对象,每实例化一个对象就是创建一个子进程。
target = test :子进程所执行的任务,就是test这个函数
args = (5,) :给进程函数传参,这里需要用元祖的方式进行传参
p.start() :执行子进程,只用调用start()方法,子进才会执行
p.join(n) :让主进程等待n秒钟
在进程结束后,主进程会等待子进程先结束,如果主进程先结束,那么所有的子进程都会结束。
Process常用的方法:
start():启动进程
is_alive() :判断进程是否还在执行,返回True 或 False
join(n) : 主进程等待子进程,n为等待的时间(秒)
run() :在调用start方法时会自动调用run()方法,可以创建Process类的子类来重写run()方法的方式创建进程
terminate():使进程立即终止
3、利用Process类的子类来创建进程
from multiprocessing import Process import time class NewProcess(Process): def __init__(self,num): self.num = num super().__init__() def run(self): print("开始重写run了") i = 0 while True: time.sleep(1) i += 1 print("子进程",i) if i == self.num: break p = NewProcess(6) p.start() p.join(2) while True: if p.is_alive(): print("父进程") time.sleep(1) elif not p.is_alive(): print("子进程结束了") break
这个方法核心就是创建一个Process类的子类,利用重写run()方法来实现任务的添加。
4、利用multiprocessing模块进程池Pool创建进程
Process类适合用于创建所需进程数量不多的情况,如果需要创建大量的进程,则需要利用进程池来创建进程。
from multiprocessing import Pool import time import os def work(i): time.sleep(1) print(i,"当前程序的pid=",os.getpid()) def work1(i): time.sleep(1) print(i,"当前程序的pid=",os.getpid()) def work2(i): time.sleep(1) print(i,"当前程序的pid=",os.getpid()) # 创建进程池 pool = Pool(2) # 使进程开始执行 pool.apply_async(work,(1,)) pool.apply_async(work1,(2,)) pool.apply_async(work2,(3,)) pool.apply(work1,(4,)) pool.apply(work2,(5,)) pool.apply(work1,(6,)) pool.apply(work2,(7,)) # 关闭进程池 pool.close() # 让主进程等待子进程 pool.join()
解释:
pool = Pool(2)为创建一个进程池,进程池中同时开两个进程,如果任务多于进程数时,进程会逐个执行任务,当一个进程完成任务后,接着执行待完成的任务,直到所有任务全部完成。
pool.apply_async(func,args) :非堵塞式,异步执行。func调用的为任务,args:为func传参,参数以元祖的方式传递。
pool.apply(func,args) :堵塞式执行。进程会等待上一个进程结束才会进行。传参同上。
pool.close() :关闭进程池,停止向进程池中添加任务
pool.join() :使主进程等待。必须在close()或者terninate()后面使用。