引言
本文是对《Convolutional Neural Networks for Sentence Classification》的原理解读,简称TextCNN。
作者提出了一种基于CNN的新的文本分类模型。该模型结构简单,支持静态词向量和可微调词向量。作者做了一系列实验验证了该方法的优势,在各种文本分类模型上取得state-of-the-art的结果。
模型结构
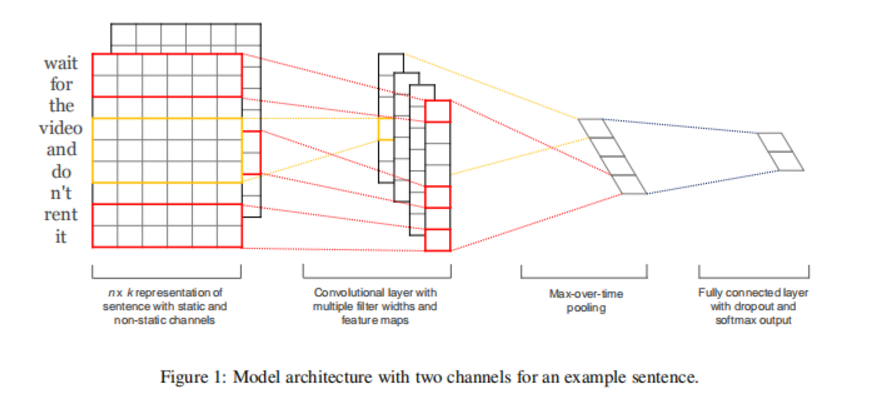
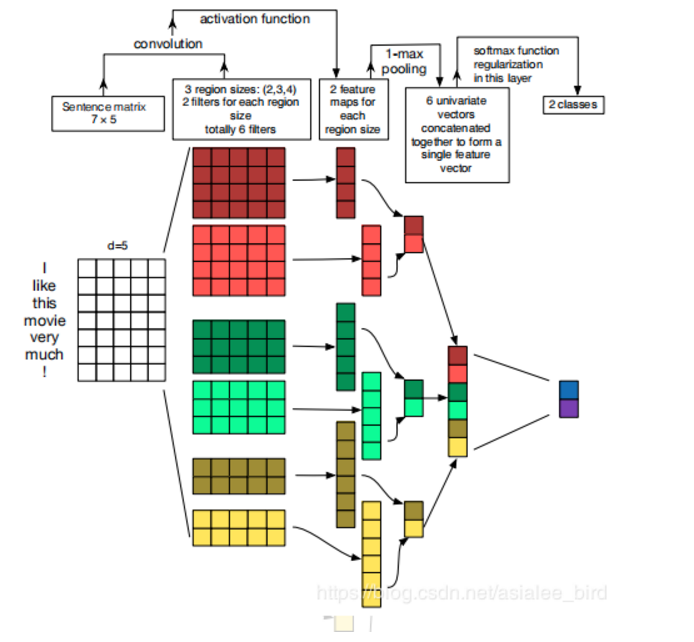
如上图所示。
- 输入长度为n的序列,序列中每个词向量维度为k。模型输入维度为
(n, k)。 - 在词向量阶段,作者也使用了不同的处理方法。尝试了以下三种词向量获取方式:
- 使用预训练好的词向量,在模型训练阶段词向量可进行fine-tuning。
- 使用预训练好的词向量,在模型训练阶段词向量冻结,不进行fine-tuning。
- 使用两个词向量获取通道,一个是冻结的,一个可fine-tuning的。
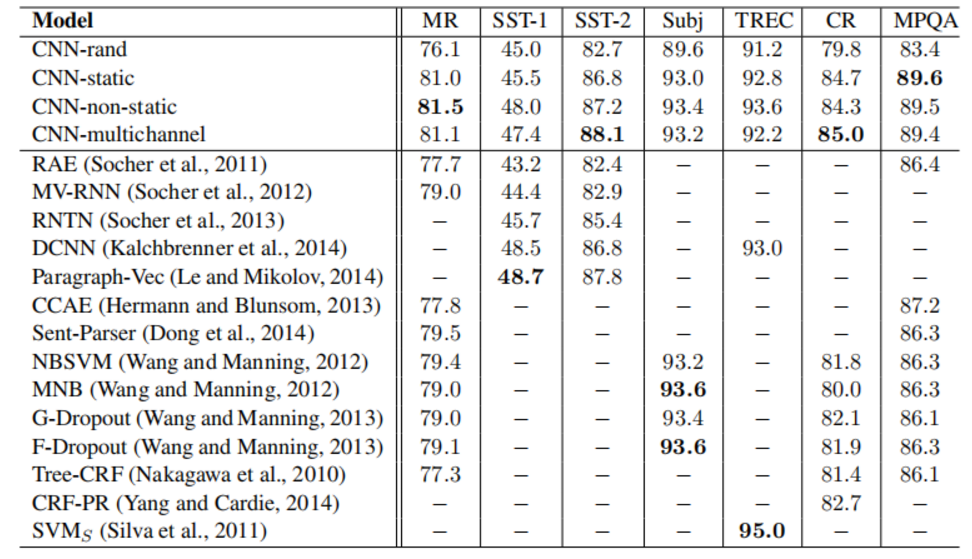
实验结果显示,使用预训练好的词向量,在模型训练阶段词向量进行fine-tuning的方式通常能取得最优结果,个别情况下双通道方式能取得最有结果。
3. 输入经过尺寸为(h, k)的卷积核,这里跟图像卷积不同是,这里卷积核的第二维的大小跟词向量的维度大小相同,就是此处的卷积核在扫描特征的时候只沿着序列的方向进行扫描,生成(n-h+1,)的一维向量。
直观上理解,相当于使用卷积核提取窗口大小为h的n-gram特征。
4. 多个卷积核生成多个(n-h+1,)的n-gram特征。
5. 卷积后面跟着GlobalAvgMaxpooling,这样无论是多长的序列进来,输出都是等长的。
6. 使用了多个不同尺寸的卷积核,相当于提取了不同窗口大小的n-gram特征。
正则
- 在倒数第二层使用了l2正则
- 在隐藏层使用了 Dropout
优缺点
- 通过CNN的方式捕捉n-gram特征,本质上是词袋模型。计算速度快,预性能也不错。
- 可解释行不强