前言
本章大致分为四部分。
java内存模型的基础,介绍内存模型的相关基本概念;
java内存模型中的顺序一致性,主要介绍重排序和顺序一致性;
同步原语,涉及synchronized,volatile,final三个同步原语的内存含义及重排序等;
java内存模型的设计,涉及与内存模型和顺序一致性内存模型关系。
一、java内存模型基础
1.1 并发编码模型的两个关键问题--线程是并发执行的活动实体
- 线程之间如何通信
- 共享内存 - 通过写-读 内存中的公共状态进行隐式通信,java采用的是共享内存模型,线程之间通信总是隐式进行
- 消息传递 - 线程之间没有公共状态,通过发送消息进行显示通信
- 线程之间如何同步
同步是指程序中用于控制不同线程间操作发生相对顺序的机制(简单理解是线程按照某种顺序进行执行)
- 共享内存,同步是显示的,必须手动指定某个方法或者代码块互斥执行
- 消息传递,同步是隐式的,且消息的发送必须在接受消息之前
java的并发采用的是共享内存模型,Java线程之间的通信总是隐式进行,整个通信过程对程序员完全透明。
1.2 java内存模型的抽象结构
在java中,所有实例域、静态域都存储在堆内存中,堆内存在线程之间共享;而局部变量、方法定义参数,异常处理参数不会再线程之间共享,不会有内存可见性问题,也不会受内存模型的影响。
java内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存。
java线程之间的通信,通过java内存模型控制(JMM,Java Memory Model),JMM决定一个线程对共享变量的写入何时对另一个线程可见。
JMM定义了工作内存和主内存之间抽象关系:共享变量存储在主内存中,线程私有的工作内存(Local Memory)存储了主内存的副本,用作线程读/写。
本地内存(Local Memory)是JMM(java内存模型)的一个抽象概念,并不真实存在。如下图:

如果线程A和线程B之间进行通信,需要经历下面的步骤
1. 线程A将本地内存(Loca Memory)中更新过的共享变量信息刷新到主内存中
2. 线程B从主内存中获取已更新的共享变量
两个步骤如下图:

从整体来看,这两个步骤实质上是线程A在向线程B发送消息,而且这个通信过程必须要经过主内存。JMM通过控制主内存与每个线程的本地内存之间的交互,来为java程序员提供内存可见性保证。
内存间交互:
关于主内存与工作内存之间的具体交互协议,即一个变量如何从主内存拷贝到工作内存,如何从工作内存同步回主内存的细节实现,java内存模型定义了八种操作:(这八个操作都具有原子性)
- lock(锁定):作用于主内存的变量,把一个变量标识为一条线程独占的状态。
- unclock(解锁):作用于主内存的变量,把一个处于锁定的状态释放出来。
- read(读取):作用于主内存的变量,把一个变量的值从主内存传输到线程的工作内存中
- load(载入):作用于工作内存的变量,把read操作从主内存 得到的变量值放入工作内存的变量副本中。
- use(使用):作用于工作内存的变量,把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作。
- assign(赋值):作用于工作内存的变量,把一个从执行引擎接收到的值 赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传递到主内存,以便write操作使用。
- write(写入):作用于主内存的变量,把store操作从工作内存中得到的变量的值放入主内存的变量中。
对于这8中操作,虚拟机也规定了一系列规则,在执行这8中操作的时候必须遵循如下的规则:
- 不允许read和load、store和write操作之一单独出现,也就是不允许从主内存读取了变量的值但是工作内存不接收的情况,或者不允许从工作内存将变量的值回写到主内存但是主内存不接收的情况
- 不允许一个线程丢弃最近的assign操作,也就是不允许线程在自己的工作线程中修改了变量的值却不同步/回写到主内存
- 不允许一个线程回写没有修改的变量到主内存,也就是如果线程工作内存中变量没有发生过任何assign操作,是不允许将该变量的值回写到主内存
- 变量只能在主内存中产生,不允许在工作内存中直接使用一个未被初始化的变量,也就是没有执行load或者assign操作。也就是说在执行use、store之前必须对相同的变量执行了load、assign操作
- 一个变量在同一时刻只能被一个线程对其进行lock操作,也就是说一个线程一旦对一个变量加锁后,在该线程没有释放掉锁之前,其他线程是不能对其加锁的,但是同一个线程对一个变量加锁后,可以继续加锁,同时在释放锁的时候释放锁次数必须和加锁次数相同。
- 对变量执行lock操作,就会清空工作空间该变量的值,执行引擎使用这个变量之前,需要重新load或者assign操作初始化变量的值
- 不允许对没有lock的变量执行unlock操作,如果一个变量没有被lock操作,那也不能对其执行unlock操作,当然一个线程也不能对被其他线程lock的变量执行unlock操作
- 对一个变量执行unlock之前,必须先把变量同步回主内存中,也就是执行store和write操作
1.3 从源码到指令序列的重排序
为了提高性能, 编译器、处理器会对源码编译后的指令进行重排序。主要分为下面3类:
- 编译器 优化的重排序。
编译器在不改变单线程语义的前提下,重新安排语句的执行顺序。
- 指令集 的重排序。
通过指令级并行技术,将多条指令重叠执行。在不存在数据依赖的前提下,处理器可以改变机器指令的执行顺序。
- 内存系统 的重排序。
由于处理器使用缓存、读/写缓冲区, 使得加载和存储操作看上去可能是乱序的。

1 属于编译器重排序,2 和 3属于处理器重排序。
重排序可能导致多线程出现可见性问题,针对上面两大类重排序(编译器、处理器),具体的处理方式如下:
- 编译器重排序,针对特定类型的JMM编译器会禁止重排序功能。
- 处理器重排序,java编译器在生成指令序列时,会插入特定类型的内存屏障(Memory Barriers)指令,通过内存屏障指令来禁止特定处理器重排序。
1.4 并发编程模型分类
在向内存写入数据前,处理器会在缓冲区临时保存需要写入的数据,避免处理器停顿下来等待向内存写入数据而造成的延迟;合并写缓冲区对同一内存地址的多次写,减少多内存总线的占用。
每个处理器上的写缓冲区,仅对它所在的处理器可见,并且处理器对内存的读/写操作顺序不一定与内存实际的读/写顺序一致。
如下图所示:处理器操作内存执行结果

假设处理器A和B按程序的顺序并行执行内存访问,最终可能得到 x=y=0 的结果。原因如下图的处理器和内存的交互
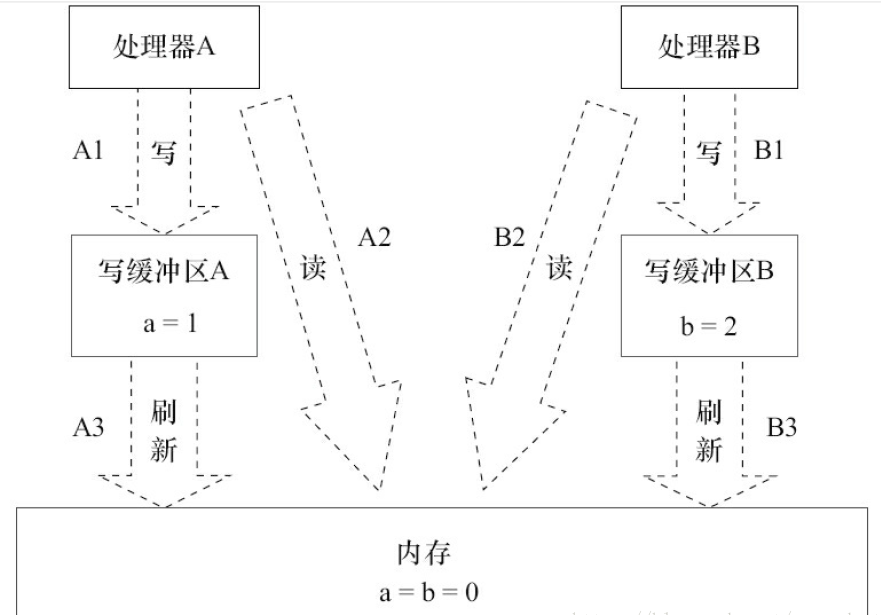
说一下x=y=0情况产生的原因
1. 处理器A和B,几乎同时将变更的数据写入自己的缓冲区(A1,B1),这个时候a=1, b=2;
2. 从内存中读取数据(A2,B2),注意这时候a=b=0,执行赋值操作x=b, y=a, 最后x=y=0;
3. 将缓冲区中的数据保存到内存中(A3,B3),将a=1,b=2,x=0, y=0的信息缓存到内存中。
通过上面的操作流程,可以发现内存中保存的x, y值是0;
常见处理器允许的重排序类型列表:

注:表格中的 ‘N’表示处理器不允许两个操作重排序,‘Y’表示处理器允许两个操作重排序。
从上图可以看出以下信息:
- 常见的处理器都允许Store - Load操作
- 常见的处理器都不允许对数据存在依赖的操作进行重排序
- 使用了写缓存的机器,拥有相对较强的处理器内存模型
为了保证内存可见性,java编译器再生产指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。
JMM把内存屏障指令分为4类,如下图的内存屏障类型表
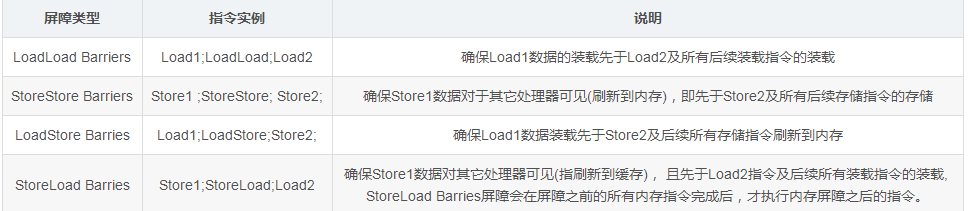
StoreLoad Barriers 是一个“全能型”的屏障,它同时具有其他3个屏障的效果。
1.5 happens-before简介
如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在happens-before关系
与程序员密切相关happens-before的规则如下:
程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作。
监视器锁规则:对一个锁的解锁,happens-before 于随后对这个锁的加锁。
volatile变量规则:对一个volatile域的写,happens-before 于任意后续对这个volatile域的读。
传递性:如果A happens-before B,且B happens-before C,则A happens-before C。
注意:两个操作之间具有happens-before关系,并不意味前操作必须在后操作之前执行!happens-before仅要求前操作执行的结果对后操作可见,且前操作按顺序排在后操作之前。
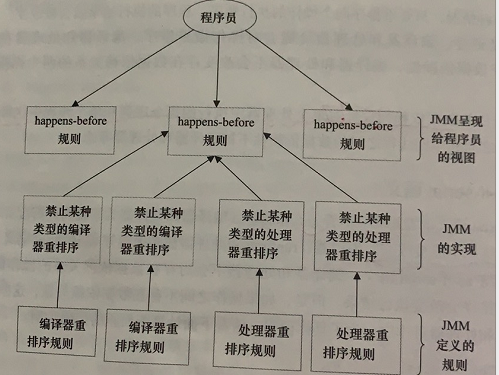
happens-before与JMM的关系如图:
二、重排序
重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排列的一种手段。
2.1 数据依赖性
两个操作访问同一个变量,且其中一个操作为写操作,那么这两个操作之间存在数据依赖性,具体分为下面3种
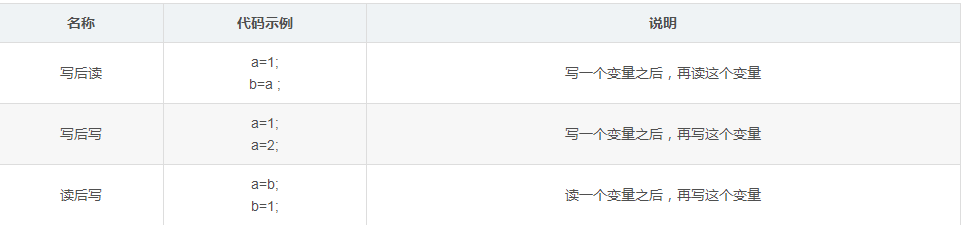
编译器和处理器可能会对操作做重排序,而上面的3种情况,如果发生重排序,执行结果可能会发生变化。
注:这里所说的数据依赖性仅针对单个处理器执行的指令序列和单个线程中执行操作,而不同的处理器之间和不同线程之间数据依赖性不被编译器和处理器考虑。
2.2 as-if-serial语义
意思:不管编译器和处理器怎么排序,单线程程序执行的结果不会改变。
编译器和处理器不会对存在数据依赖性的数据进行重排序,因为如果存在数据依赖性,重排序之后可能会改变执行结果。
但是如果操作之间不存在数据依赖性,操作可以被编译器和处理器重排序。
比如:
double pi = 3.14 ;
double r = 1.0 ;
double area = pi * r * r ;
area依赖 pi 和 r, 那么area必须在 pi 和 r 之后操作, 但是pi 和 r 之间没有数据依赖的关系,所以重排序之后是先获取 pi 的值还是先获取 r 的值都没有影响,从宏观的角度来看代码是顺序执行的。

as-if-serial 语义使单线程程序员无需担心重排序会干扰它们,无需担心内存可见性问题。
但是在多线程程序中却不一定,对存在控制依赖的操作重排序,可能会改变程序的执行结果。
三、顺序一致性
顺序一致性内存模型是一个理论参考模型,在设计的时候,处理器和编译语言的内存模型都会以顺序一致性内存模型作为参照。
3.1 数据竞争与顺序一致性
java内存模型规范对数据竞争的定义:在一个线程中写一个变量,在另一个线程读同一个变量,而且写和读操作没有通过同步来排序。
JMM对正确同步的多线程的内存一致性做了如下保证:
如果程序正确同步的时,程序的执行将具有顺序一致性(Sequencetially Consistent)——即程序的执行结果与程序在顺序一致性内存模型中执行结果相同.
3.2 顺序一致性内存模型
顺序一致性内存模型的两大特性:
- 一个线程中的所有操作必须按照程序的顺序来执行
- 不管程序是否同步,所有的线程都只能看到一个单一的操作执行顺序,且在顺序内存模型中,每个操作都必须是原子性的,且操作结果对所有线程可见。
如下的顺序一致性内存模型的视图
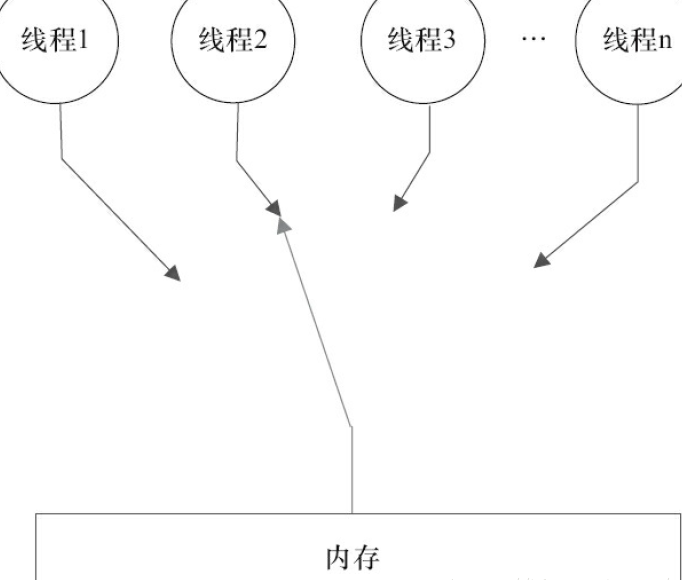
- 顺序一致性模型有一个单一的全局内存,这个内存通过左右摇摆的开关连接到任意一个线程
- 每个线程必须按照程序的顺序来执行内存的读/写
- 任意时刻只有一个线程可以连接到内存,当多线程并发执行的时候,开关装置将多线程的内存读/写操作串行化
注意:JMM对未同步程序保证。未同步的程序在JMM中不但整体的执行顺序无序,而且所有线程看到的执行顺序也可能不一致。比如:某个线程将信息保存到本地缓存中(Local Memory),没有及时将信息刷新到内存中, 对于其它线程这个信息是没有变化的,只有将信息刷新到内存中时,其它线程才可以看见信息的变更。
3.3 同步程序的顺序一致性效果
实例代码:
class SynchronizedExample{
int a = 0 ;
boolean flag = false ;
public synchronized void writer(){
a = 1 ;
boolean = true ;
}
public synchronized void reader() {
if(flag) {
int i = a;
//.....
}
}
}
顺序一致性模型中,所有操作完全按程序的顺序串行执行。
虽然线程A在临界区内做了重排序,但由于监视器互斥执行的特性,线程B无法“观察”到线程A在临界区的重排序。
上面的代码在JMM和顺序一致性模型中的执行对比流程如下:
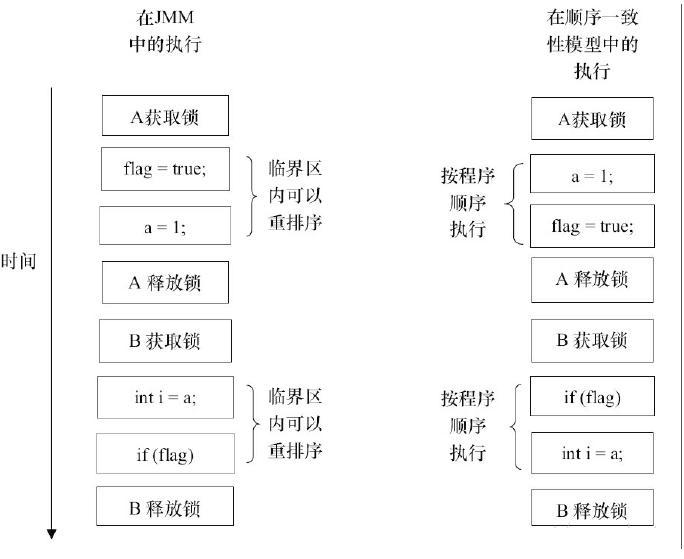
从上面流程对比,有下面的总结:
- JMM在具体实现上的基本方针不变:在不改变程序执行结果的前提下,尽可能的为处理器和编译器提供方便。
- 顺序一致性模型中,所有操作完全按照程序顺序串行执行
- JMM中,临界区内的代码可以重排序,并且其它线程无法看到这个重排序,这样既可以保证总体与顺序一致性模型具有相同的视图,也可以为处理器和编译器提供方便,以提高效率。
3.4 未同步程序的执行特性
JMM最小安全性:对于未同步或者未正确同步的多线程程序,程序读取的值要么是之前某个线程写入的值,要么是默认值(0,null,false),不会无中生有(Out Of Thin Air)。
为了实现最小安全性:JMM在堆上分配对象时,首先会对内存空间清零,然后才会在上面分配对象。
未同步程序在JMM模型和顺序一致性模型中的差异:
- 顺序一致性保证单线程内的操作会按照程序的顺序执行,JMM不能保证单线程内的操作会按照程序的顺序执行。
- 顺序一致性保证所有的单线程只能看到一致的操作结果,JMM不能保证所有线程能看到一致的执行顺序。
- JMM不保证对64位的long型和double型变量的写操作具有原子性,而顺序一致性保证所有的内存读/写操作都具有原子性。
计算机中,数据通过总线在处理器和内存之间传递。每次处理器和内存之间的数据传递都是通过一系列步骤来完成,这一系列步骤称之为总线事务(Bus Transaction)。
总线事务包括读事务(Read Transaction)和写事务(Write Transaction)。 读事务从内存传送数据到处理器,写事务从处理器传送数据到内存,每个事务会读/写内存中一个或多个物理上连续的字。
总线的这些工作机制可以把所有处理器对内存的访问以串行化的方式来执行。在任意时间点,最多只能有一个处理器可以访问内存。这个特性确保单个总事务之中的内存读/写操作具有原子性
对上述第三点JMM模型long型和double型变量的写操作不能保证原子性的一点说明(针对32位处理器):
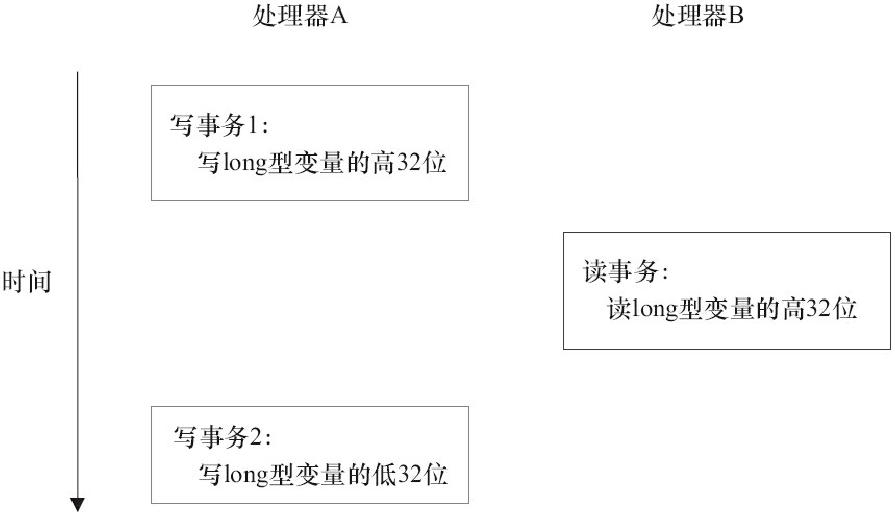
在32位的处理器上,64位的操作会被分为两个操作, 而这两个操作可能会被两个总线事务执行,参见上图如果在执行两个写事务期间, 可能另一个处理器读取了long型或double型变量的高32位的无效值,从而没有保证原子性(不可拆分的一个或一些列操作)的特性。
四、volatile的内存语义
4.1. volatile的特性
可以理解对volatile变量的单个读/写,看成是使用同一个锁对这些单个读/写做了同步。
示例代码 1:
class VolatileFeatureExample{ volatile long v1 = 0L; //使用volatile声明64位的long型变量 public void set(long l){ this.v1 = l ; //单个volatile变量的写 } public void getAndIncrement() { v1++; //复合(多个volatile变量的读写) } public long get(){ return this.v1 ; //单个volatile变量的读 } }
示例代码 2:
class VolatileFeatureExample{ long v1 = 0L; //64位的long型普通变量 public synchronized void set(long l){ this.v1 = l ; //对单个的普通变量的写使用同一个锁同步 } public void getAndIncrement() {//普通方法的调用 lont temp = get(); //调用已同步的读方法 temp += 1L ; //普通写操作 set(temp); //调用已同步的写方法 } public synchronized long get(){ return this.v1 ; //对单个的普通变量的读使用同一个锁 } }
比较示例代码 1 和 示例代码 2 , 使用volatile修饰的变量进行单个读/写操作,与一个普通变量的读/写操作都使用同一个锁同步的执行结果相同。
volatile具有下列特性:
- 可见性. 对一个变量的读取,总能看见任意线程对这个volatile变量的写入。
- 有序性. 不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
4.2. volatile写-读建立的happens-before关系
相对于上一节提到的volatile自身特性,volatle对线程内存可见性显得更为重要。从JDK5开始,volatile变量的读/写已经实现了线程之间的通信。
从内存语义角度来看。① volatile写和锁的释放具有相同的语义, ② volatile读和锁的获取具有相同的语义。
示例代码:
class VolatileExample { int a = 0; volatile boolean flag = false; public void writer() { a = 1; // 1 flag = true; // 2 } public void reader() { if (flag) { // 3 int i = a; // 4 …… } } }
示例代码的执行可以参照下面的图示:
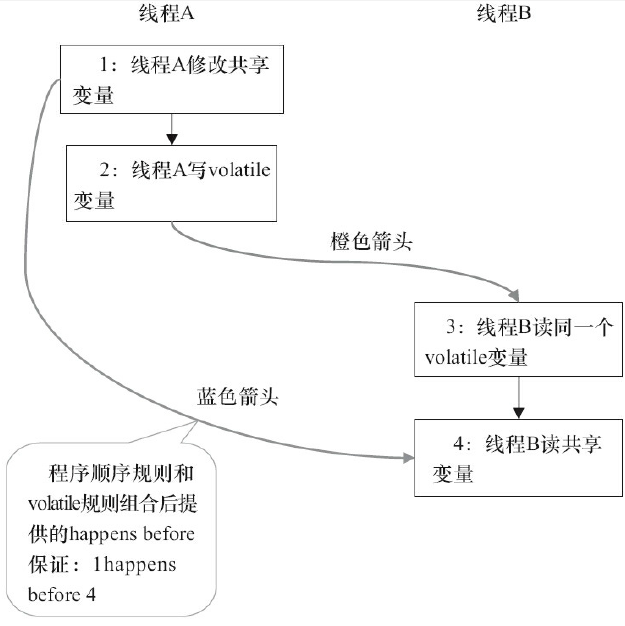
从执行图中,有下面的执行顺序
- 1 happen before 2 , 3 happen before 4
- volatile规则, 2 happen before 3
- happen before规则具有传递性,1 happen before 4
如果线程A写一个volatile变量后,线程B读同一个volatile变量,那么线程A在写volatile变量前对所有可见的共享变量的修改,在线程B读volatile变量后,修改的所有共享变量将对B可见。
4.3. volatile写-读的内存语义
- volatile写的内存语义
当写一个volatile变量时,JMM会把该线程对应的本地内存(Local Memory)中的共享变量更新到主内存中。
- volatile读的内存语义
当读volatile变量时,JMM会把当前线程的本地内存(Local Memory)置为无效,将会从主内存重新读取共享变量。
volatile写和volatile读的内存语义的总结:
- 线程A写一个volatile变量,实质上是线程A向接下来要读这个volatile变量的其它线程发出共享变量有做修改的消息
- 线程B读一个volatile变量,实质上是线程B接收了之前某个线程发出的对共享变量有做修改的消息。
- 线程A写一个volatile变量,随后线程B读这个volatile变量,这个过程实质上线程A通过主内存向线程B发送消息。
4.4. volatile内存语义的实现
为了实现volatile的内存语义,JMM会限制编译器重排序和处理器重排序的类型,编译器指定的规则表如下:

由上表格可知:
1. 当第一个操作为普通读/写,第二个操作为volatile写,则编译器不能重排序这两个操作。 (对第一行、第三列)
2. 当第一个操作为volatile读,第二个操作为volatile写,则编译器不能重排序这两个操作。 (第二行、第二列)
3. 当第一个操作为volatile读,不管第二个什么操作,都不允许编译器重排序这两个操作。
4. 当第二个操作为volatile写,不管第一个什么操作,都不允许编译器重排序这两个操作。
基于JMM保守策略的内存屏障插入策略
- 在每个volatile写操作的前面插入一个StoreStore屏障
- 在每个volatile写操作的后面插入一个StoreLoad屏障
- 在每个volatile读操作的前面插入一个LoadLoad屏障
- 在每个volatile读操作的后面插入一个LoadStore屏障
因为编译器常常无法准确判断在一个volatile写的后面是否需要插入StoreLoad屏障(比如: volatile写的后面直接return返回),为了能正确的实现volatile的内存语义,JMM采取了保守的策略:在每个volatile写的后面或者volatile读的前面,插入一个StoreLoad屏障。JMM实现上首先确保正确性,让后再去追求执行效率。
五、锁的内存语义
总所周知,锁可以让临界区互斥执行。
5.1 锁的释放和获取建立的happens-before更新
锁是java并发编程中最重要的同步机制。锁除了让临界区互斥执行,还可以让释放锁的线程A向获取同一个锁的线程B发送消息。
示例代码 :
class MonitorExample {
int a = 0;
public synchronized void writer() { // 1
a++; // 2
} // 3
public synchronized void reader() { // 4
int i = a; // 5
……
} // 6
}
假设线程A执行writer()方法, 随后线程B执行reader()方法,根据happens-before规则,有下面规则
①. 1 happens-before 2, 2 happens-before 3 ; 4 happens-before 5, 5 happens-before 6
②. 3 happens-before 4
③. 根据happens-before的传递性, 2 happens-before 5
具体的表现形式可以参考下面的图:
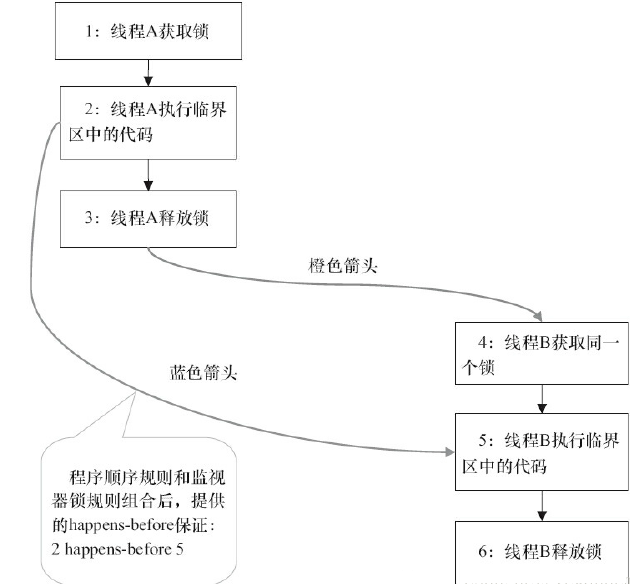
5.2 锁的释放和获取的内存语义
当线程A释放锁时,会把该线程本地内存(Local Memory)中的共享变量刷新到主内存中,当线程B获取锁时,JMM会把该线程对应的本地内存(Local Memory)信息置为无效, 然后从主内存中重新获取对应的共享变量信息。
从锁的内存语义的说明,可以看出锁的释放与volatile读具有相同的内存语义; 下面对锁的释放和锁获取的内存语义进行的总结:
- 线程A释放锁,实际是线程A对接下来需要获取锁的线程B,发送共享变量发生了改变的信息。
- 线程B获取锁, 实际是线程B收到了某个线程发送的共享变量已经改变的信息。
- 线程A释放锁,随后线程B获取锁,这个过程实际上是线程A通过主内存向线程B发送的共享变量信息已经变更。
六、final域的内存语义
与前面的锁和volatile相比,对final域的读和写更像是普通的变量访问。
6.1 final域的重排序规则
对于final域,编译器和处理器要遵守两个重排序规则。
1)在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
2)初次读一个包含final域的对象的引用,随后初次读这个final域,这两个操作之间不能重排序。
6.2 写入final域的重排序规则
写入final域的重排序规则是:禁止把final域的写入重排序到构造函数之外。这个实现包含两个方面。
1)JMM禁止编译器把final域的写入重排序到构造函数之外。
2)编辑器会在final域的写之后,构造函数return之前,插入一个StoreStore屏障。这个屏障禁止处理器把final域的写重排序到构造函数之外。
写final域的重排序规则可以确保:在任意线程引用对象之前可见,对象的final域已经被正确初始化过了,而普通域不具有这个保障。
6.3 读取final域的重排序规则
读取final域的重排序规则是,在一个线程中,初次读取对象引用与初次读取该对象包含的final域,JMM禁止处理器重排序这两个操作(注意,这个规则仅仅针对处理器)。编译器会在读final域操作的前面插入一个LoadLoad屏障。
初次读对象引用与初次读该对象包含的final域,这两个操作之间存在间接依赖关系。由于编译器和大多数处理器会遵守间接依赖关系,因此都不会重排序这两个操作。
6.4 final域为引用类型
对于引用类型,写final域的重排序规则对编译器和处理器增加了如下约束:在构造函数内对一个final引用的对象的成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
七、happens-before
happens-before是JMM最核心的概念。
7.1 JMM的设计
JMM设计需要关注的点,
1. 程序员对内存模型的使用。程序员希望基于一个强内存模型来编写代码, 这样的内存模型易于理解,易于编程.
2. 编译器和处理器对内存模型的实现。编译器和处理器希望基于一个弱内存模型,这样束缚越少,能尽可能的优化来提高性能
为了解决上面两个相互矛盾的问题, JMM对是否禁止重排序采用了下面的规则
1. 如果重排序结果不改变代码执行结果,编译器和处理器对这种重排序不做要求。
2. 如果重排序结果改变了代码执行结果, 编译器和处理器必须禁止这种重排序。
7.2 happens-before 的定义
happens-before的来源可以阅读这篇文章《Time,Clocks and the Ordering of Events in a Distributed System》 , 而对happens-before的定义如下:
1)如果一个操作happens-before另一个操作 , 那么第一个操作的执行结果对第二个的操作可见,且第一个操作的执行顺序必须在第二个操作之前。
2)如果两个操作之间存在happens-before关系,并不意味着具体实现必须按照这种关系来执行。如果重排序之后的执行结果(单线程程序和正确同步的多线程程序)与按照happens-before关系执行结果一致, 那么这种重排序并不非法。
happens-before和as-if-serial之间的关系
- as-if-serial 保证单线程内程序的执行结果不被改变, happens-before保证正确同步的多线程程序的执行结果不被改变。
- 从宏观角度来看: as-if-serial保证单线程程序是按照程序的顺序来执行的,happens-before保证多线程程序是按照happens-before指定的顺序来执行的。
as-if-serial 和 happens-before这么做的目的是,在不改变程序执行结果的前提下,尽可能的提高程序的并行度。
7.3 happens-before 规则
happens-before规则如下:
1) 程序顺序规则: 一个程序中的每个操作,happens-before于该线程中的任意后续操作。
2) 监视器锁规则:对一个锁的解锁, happens-before于随后对这个锁的加锁。
3) volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读
4) 传递性: 如果A happens-before B, B happens-before C , 那么A happens - before C。
5) start规则:如果程序A执行操作ThreadB.start() ,那么线程A的ThradB.start()操作 happens-before于线程B中的任意操作。
6) join(): 如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作 happens-before 于线程A从ThreadB.join()操作成功返回。
八、双重检查锁定与延迟初始化
8.1 双重检查锁定的由来
对一些开销比较大的初始化工作,并且只有在需要的时候才初始化,这时可能需要采用延迟初始化。下面是相关代码示例,
//代码示例1 public class UnsafeLazyInitialization{ private static Instance instance ; public static Instance getInstace() { if(instance == null) { // 1. 线程A执行到此处 instance = new Instance() ; // 2. 线程B执行到此处 } return instance ; } } //代码实例2 public class SafeLazyInitialization{ private static Instance instance ; public synchronized static Instance getInstace() { if(instance == null) { instance = new Instance() ; } return instance ; } } //代码示例3 public class DoubleCheckLocking{ private static Instance instance ; public static Instance getInstance(){ if(instance == null) { synchronized(DoubleCheckLocking.class) { if(instance == null) { instance = new Instance(); } } } return instance ; } }
针对上面的三段代码进行分析双重检查锁定的由来,
1. 针对代码示例1如果线程A代码1的同时,线程B执行代码2,线程A可能看到instance的引用对象还没有初始化。
2. 针对代码示例2,synchronized将导致性能开销(现在已经有了很大的性能优化),如果频繁调用会导致程序执行性能下降,如果getInstance()不会被多个线程频繁调用,那么这个延迟初始化可以接受。
3. 针对代码示例3,在synchronized修饰前提下,如果第一次检查instance不为null, 那么就不需要执行下面加锁的初始化操作, 可以大幅降低synchronized带来的性能开销(synchronized修饰后能够进入加锁内部进行初始化操作的次数会非常少),这就是双重锁的由来。
8.2 双重锁问题的根源
针对代码示例3,代码读到instance 不为 null时, instance引用的对象很可能还没有初始化。
针对前面的代码示例3,instance = new Instance(); 可以分解为下面的操作步骤,
memory = allicate(); //1. 分配对象的内存空间
ctorInstance(memory); //2. 初始化对象
instance = memory; //3. 设置instance指向刚分配的内存地址
在编译器和处理器操作期间,可能对上面步骤进行重排序,将第2,3步骤顺序重排,即还没有初始化对象,instance已经指向分配对象的内存地址,参考下面多线程执行时序图表
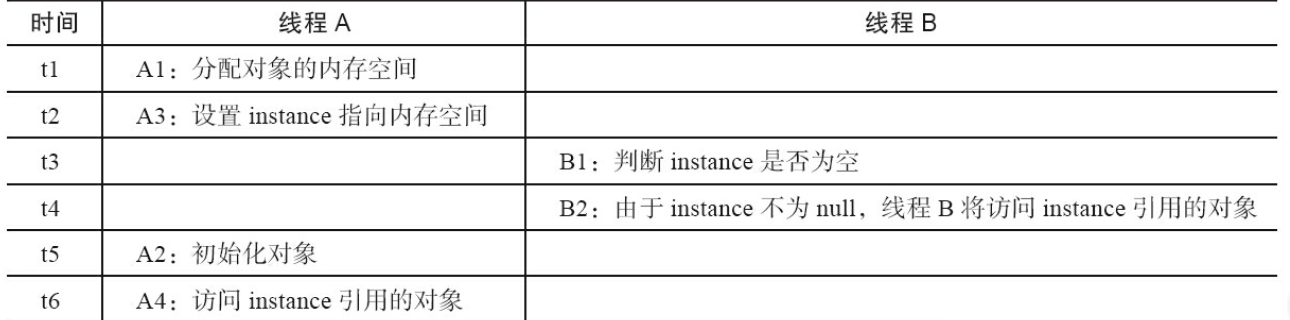
针对线程A, A2和A3虽然重排序了,但是只要保证A2 一定排在A4的前面,线程A的结果就不会改变 ; 对于线程B,在B1处判断instance不为空,如果访问instance引用对象,线程B将访问一个未初始化的对象。
解决线程安全延迟初始化问题的方式
- 不允许2 、3重排序
- 允许2、3重排序,但是不允许其它线程“看到”这个重排序
8.3 基于volatile的解决方案
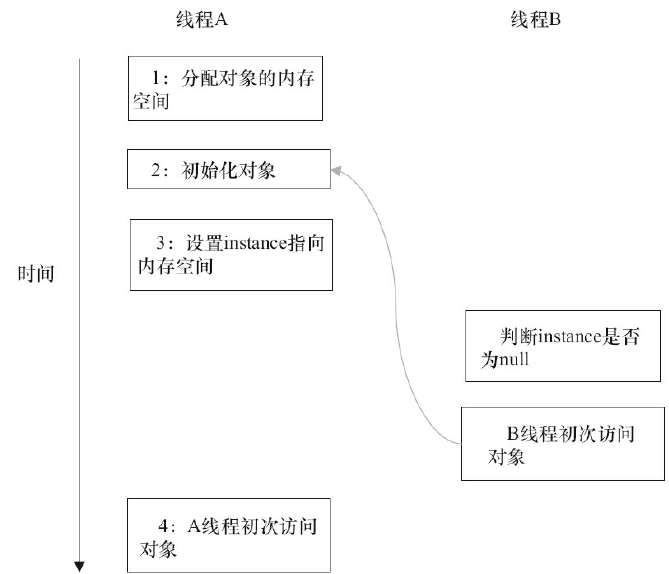
使用volatile修饰延迟初始化可能重排序的变量,比如针对上面的代码示例3
public class DoubleCheckLocking{ private volatile static Instance instance ; public static Instance getInstance(){ if(instance == null) { synchronized(DoubleCheckLocking.class) { if(instance == null) { instance = new Instance(); } } } return instance ; } }
使用volatile修饰之后,步骤2、3之间的重排序在多线程环境中将会被禁止,可以参见下面的时序图
8.4 基于类初始化的解决方案
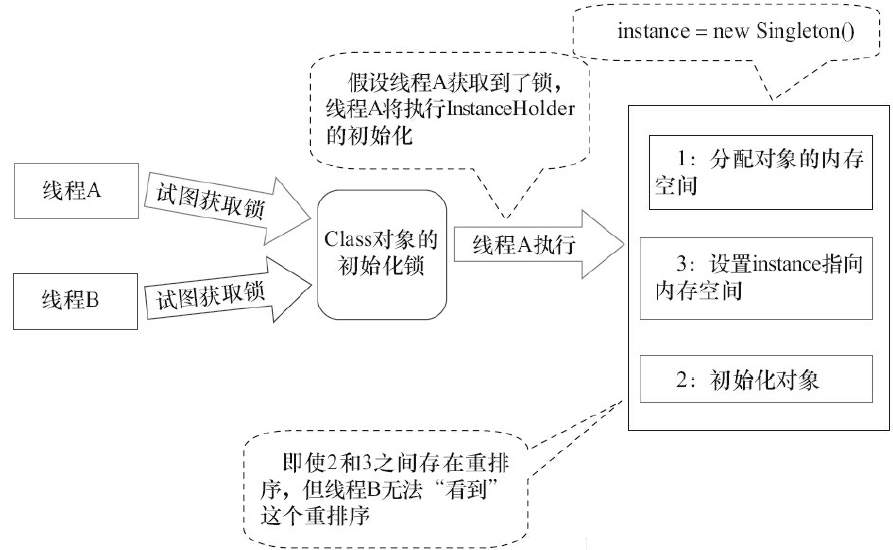
JVM在Class被加载后,且被线程使用前, 会执行类的初始化,在执行类的初始化期间JVM会获取初始化锁,这个锁可以同步多个线程对同一个类的初始化。
//代码示例1 public class InstanceFactory{ private static class InstanceHolder{ public static Instance instance = new Instance() ; } public static Instance getInstance(){ return InstanceHolder.instance ; //这里将导致InstanceHolder类被初始化 } }
对示例初始化的流程可以参照下面截图:
对类或者接口T被立即初始化的情况总结:
- T是一个类,而且这个类的实例被初始化
- T是一个类,而且这个类的静态方法被调用
- T中声明的一个静态字段被赋值
- T中声明的一个静态字段被使用,而且这个字段不是一个常量字段
- T是一个顶级类(Top Level Class) ,而且一个断言语句嵌套在T内部被执行
参考:《java并发编程的艺术》