前言
为Unity面试而准备一些问题,如果有什么说的不对的,欢迎指正
语言机制类
1、GC机制
在C/C++中程序员要自己负责系统的内存管理,而C#采用Garbage Collection自动回收内存,
当Java虚拟机(VM)或.NETCLR发觉内存资源紧张的时候,就会自动地去清理无用对象(没有被引用到的对象)所占用的内存空间,
查找没有被引用的对象有一系列的算法,
Lua语言的GC机制采用是Mark and Sweep算法。
2、协程线程进程
进程一个具有独立功能的程序在一个数据集合上的一次动态执行过程(程序是静态的代码,进程是动态执行的过程)
线程:进程是分配资源的基本单位,而线程则是系统调度的基本单位。
一个进程内部的线程可以共享该进程的所分配到的资源。线程的创建与撤消,线程之间的切换所占用的资源比进程要少很多。
总的来说就是为了更进一步提高系统的并发性,提高CPU的利用率。
协程:是一种比线程更加轻量级的存在,协程调度不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行),你可以随时把它挂起。
一个线程里可以有多个协程。协程的切换几乎没有操作系统的内核开销,不会像线程切换那样消耗资源(线程切换要改Context)。
协程的一大好处就是可以避免数据访问冲突的问题因为它的粒度相对多线程的大很多,所以往往很少出现冲突现象。协程写入死循环会将线程卡死。

(配图有些问题,yield return null是让协程在下一个yield null执行,如果在update前启动了协程,那么在update后的yield的null是会执行的)
3、装箱与拆箱
值类型变量封装object类型变量或者对应的object将这个值类型从栈区copy到堆区产生一个引用类型叫做装箱;
把这个堆上的obj转成值类型,从堆上往栈上搬东西叫做拆箱,装箱和拆箱会损失一定性能。
按理说C#被设计成一种完全面向对象的语言。因此,包括数字、字符、日期、布尔值等等在内的一切,都是对象。似乎只需要一种方式来对待这些对象就可以了。
但是C#必须为性能而妥协,我们知道,对于CPU来说,处理一个完整的对象,需要很多的指令,
对于内存来说,又需要很多的内存。如果连整数都是对象,那么性能自然很低。
C#于是使用了一种机制,使得这些基本类型在一般的编程中被当作非对象的简单类型处理,
在另一些场合(比如需要多个脚本引用同一个对象)又允许它们被视作是一个对象。(摘自评论)
4、值类型和引用类型的区别
- 值类型的数据存储在内存的栈中,引用类型的数据存储在内存的堆中
- 值类型存取速度快,引用类型存取速度慢
- 类型表示实际数据放在栈中;引用类型表示指向存储在内存堆中的数据的指针或引用,在栈中存放实际数据的地址,堆上存放实际数据
- 栈的内存分配是自动释放;而堆在.NET中会有GC来释放
- 值类型继承自System.ValueType,引用类型继承自System.Object
5、lua如何实现面向对象?lua的元表?
由于暂时没怎么学lua,TODOOOOOOOOOO
6、闭包
闭包是指有权访问另一个函数作用域中的变量的函数
闭包这个词本身指的是一种函数。而创建这种特殊函数的一种常见方式是在一个函数中创建另一个函数。
闭包中引用的变量实际上就是把原来声明在主体中的变量转移到用匿名密封类或者结构体里,
最终在主体中访问的变量就是生成的匿名类中对象。来自博客
C#里可以在函数里放一个委托或者匿名函数引用局部变量。
7、反射
程序一般都是操作数据,但有时程序也操作程序和程序类型本身的信息,这种信息称为元数据,意义为数据的数据。
反射指程序可以访问、检测和修改它本身状态或行为的一种能力。
程序集包含模块,而模块包含类型,类型又包含成员。反射则提供了封装程序集、模块和类型的对象。
您可以使用反射动态地创建类型的实例,将类型绑定到现有对象,或从现有对象中获取类型。然后,可以调用类型的方法或访问其字段和属性。它允许程序创建和控制任何类的对象,无需知道目标类,没有类型依赖,而且还能访问对象的各个成员。
Unity中的GetComponent的方法都是使用了反射机制,获取当前GameObject下动态运行的组件,然后对其进行操作。大部分情况我们使用的是被封装好的反射。
Unity常用组件类
1、Canvas的三种渲染模式
Screen Space - Overlay:UI元素直接覆盖在任何摄像机的上方。
Screen Space - Camera:需要指定一个摄像机,UI组件可以控制和摄像机的距离,可以和场景里的物体做一些遮挡之类的交互。
World Space :画布相对于世界空间,和场景物体一样有遮挡关系,可以旋转,3d UI制作,没有屏幕自适应。
2、Mono生命周期
分阶段作展示,这里就不配图了,主要是生命周期太长了
初始化:Awake -> OnEnable ->Start ->
{kind=link}
当脚本实例被载入时,
Awake()将会被调用,你可以在这里进行初始化操作。 GameObject如果为一开始setActive为false则一开始不会执行。
当对象变为激活状态时(active = true),就会调用这个方法。一般来说,添加委托或事件可以放在OnEnable(),取消委托或事件可以放在OnDisable()。
AwakeStart一次,OnEnable设置enabled可多次执行
物理计算:FixedUpdate -> OnTrigger/Collision->
游戏逻辑:InputEvent -> Update-> yield(唤醒挂起的协程,前面fixedUpdate也有yield) ->
动画运算:OnAnimatorMove/IK(取决于Animator的 UpdateMode怎么选而有区别,如果是Normal则处于Update后,如果是Physics的话则处于FixedUpdate之后)
-> LateUpdate->
渲染:Scence Rendering -> Gizmos ->GUI ->
应用处理:OnApplicationPause -> OnApplicationQuit ->
OnApplicationQuit:在退出游戏之前,将在所有的游戏对象上调用该方法。如果是在编辑器中,那么就是当用户点下停止按钮时调用。
退出:OnDisable -> OnDestory
等Update 执行完毕后 在去执行LateUpdate,LateUpdate常用于摄像机跟随等滞后操作,Update里适合写逻辑
3、堆Heap栈Stack
堆中存储的信息在被调用完毕不会立即被清理掉。
【申请速度】
堆的申请速度较慢,容易产生内存碎片,但是用起来比较方便。
而栈的申请速度较快,但却不受程序员的控制。
【申请大小】
栈申请的容量较小1-2M,堆申请大小虽受限于系统中有效的虚拟内存,但较大
【存储内容】
栈负责保存我们代码执行或调用的路径,而堆则负责保存对象或者说数据的路径。
栈是自行维护的,也就是说内存自动维护栈,当栈顶的内容不再被使用,该内容将会被跑出。相反,堆需要考虑垃圾回收。栈会保存函数的调用入口
如何决定放哪?
这里有一条黄金规则:
1.引用类型总是放在堆中。
2.值类型和指针总是放在他们被声明的地方。
4、存储的几种方式
PlayerPref本地持久化
小的短的数据,面板的属性设置可以使用
每个变量一个key GetInt SetInt等方法,值可以在注册表里查看
BinaryFormatter
二进制存储,序列化、反序列化(强制类型转换),字节流存储,文件不具有可读性
对于字节数组,使用FileStream写入
save class要有serializable的特性
头文件 system.IO
二进制文件大小端问题文件存储不兼容?
JSON
JavaScript Object Notation
一种数据交换的格式,便于人的阅读和编写
常用于客户端和服务器传输和整个场景的存储信息
轻量的交换语言,格式压缩,占用带宽小,解析速度快
具有自我描述性,key-value键值对,作为文本格式即是一个string类型的
{ }表示对象,[ ]表示数组
创建对象存储,序列化save对象为string,反序列化string变为save对象
JsonUtility是unity自带的解析工具FromJson和ToJson,FromJson 模板需要指定类型
也可以使用其他的比如LitJson,Unity自带的解析速度很快,但是有一定的局限性
向文件中写入一些string时使用StreamWriter/Reader类,他对不同编码有不同处理格式
常用Application.dataPath或Application.persistDataPath + “ ame.json”,persistDataPath工程是隐藏的
C#中的List对象会变成Json的[ ]
需要自动换行的软件帮助
XML
设计用来结构化存储和传输数据
eXtensible Markup Language:可标记扩展语言
有时大量的数据需要经过转换才能被读取,部分不兼容的数据可能在这个过程中丢失
xml以纯文本格式,本质就是交换字符串,数据可以供各种数据使用
Tag是自定义的
可以使用XmlDocument类来保存、加载(System.Xml)
保存:
CreatElement创建节点并给出tag名字
AppendChild添加子节点
xmlElement.inerText可以获取xmlElement节点的内部信息
所有的节点都要按照实例化节点和添加的方式来使用
最后把root添加进XmlDocument里去,用save把它保存到一个text文件里
加载:
getElementsByTagName,可以获得一个XmlNodeList,只有一个元素则获取一个
同样使用InerText加载到游戏数据中
存储是一种树状结构
相比JSON代码量多很多,且里面有大量的冗余标签(表示结构)
解析xml也要花费较多的时间
多数时候我们不需要冗余信息,但是一旦需要的时候没有就是不行。
根据项目的需求选择适合的
数据结构类
1、Dictionary的插入时间复杂度?
Dictionary内部实现为一个哈希表,通过设置好的哈希映射,达到常数级的时间复杂度。
2、平衡二叉树的插入时间复杂度?
查询是Log n的,查到应该插在哪即可用常数级去插入,合起来时间复杂度Log n。
3、手写快排
快速排序思想:
关键步骤:1、选主元;2、两个指针从两头扫描确定大于主元和小于主元的集合;3、对两个区间递归
快速排序对小规模的数据不如使用插入排序,数据大概在1000左右时两个性能差不多
void InsertionSort(vector<int>& A, int left, int right)
{ /* 插入排序 */
int P, i;
int Tmp;
for (P = left + 1; P <= right; P++) {
Tmp = A[P]; /* 取出未排序序列中的第一个元素*/
for (i = P; i > left && A[i - 1] > Tmp; i--)
A[i] = A[i - 1]; /*依次与已排序序列中元素比较并右移*/
A[i] = Tmp; /* 放进合适的位置 */
}
}
int Median3(vector<int>& A, int Left, int Right)
{
//采用头中尾取中位数的方式确定主元,
//确定好主元之后再把主元移动到左端或右端保持一个连续的集合来给quickSort使用
int Center = (Left + Right) / 2;
if (A[Left] > A[Center])
swap(A[Left], A[Center]);
if (A[Left] > A[Right])
swap(A[Left], A[Right]);
if (A[Center] > A[Right])
swap(A[Center], A[Right]);
/* 此时A[Left] <= A[Center] <= A[Right] */
swap(A[Center], A[Right - 1]); /* 将基准Pivot藏到右边*/
/* 只需要考虑A[Left+1] … A[Right-2] */
return A[Right - 1]; /* 返回基准Pivot */
}
void Qsort(vector<int>& A, int Left, int Right)
{ /* 核心递归函数 */
int Pivot, Cutoff, Low, High;
Cutoff = 1000;
if (Cutoff <= Right - Left) { /* 如果序列元素充分多,进入快排 */
Pivot = Median3(A, Left, Right); /* 选基准 */
Low = Left; High = Right - 1;
while (1) { /*将序列中比基准小的移到基准左边,大的移到右边*/
while (A[++Low] < Pivot);
while (A[--High] > Pivot);
if (Low < High) swap(A[Low], A[High]);
else break;
}
swap(A[Low], A[Right - 1]); /* 将基准换到正确的位置 */
Qsort(A, Left, Low - 1); /* 递归解决左边 */
Qsort(A, Low + 1, Right); /* 递归解决右边 */
}
else InsertionSort(A, Left, Right); /* 元素太少,用简单排序 */
}
void QuickSort(vector<int>& A, int N)
{ /* 统一接口 */
Qsort(A, 0, N - 1);
}
4、散列算法&&哈希冲突
散列算法:所谓查找就是已知对象找位置。如何快速搜索到需要的关键词?如果关键词是字符串不方便比较怎么办(strcmp)?散列查找就是为了解决上面的问题,它主要做两件事:计算位置、解决冲突;
通过构造散列函数来计算关键词的存储位置,如果构造的函数计算多个关键词的存储位置相同则要解决冲突。
他的时间复杂度是O(1),查找时间和问题规模无关,评价散列函数的性能主要看成功平均查找次数和不成功平均查找次数,表中的元素不应当过多,装填因子超过0.85或其他表的查找就会由于冲突而性能下降。
装填因子公式:m为表的大小,n为元素个数
alpha = n / m
常见的计算位置的方法:
-
对数字:
-
直接定址:一个线性的安排
H(key) = a *key+b -
除留余数:TableSize为表的大小,一般取素数
H(key) = key % TableSize -
数字分析:比如身份证号,取随机性大的几位作为地址
-
折叠法:56793542转变为 542 + 793+056=1391 取三位391
-
平方取中法:顾名思义,把这个数平方然后取中间几位,每一位对运算结果都有影响
-
-
对字母:
-
会想办法把它映射成一个整数
-
前几个字母ASCII相加求余:冲突比较严重,eat和tea等
-
移位法:让每一位字母都起作用,每一位字母看成一个26进制的一个数字,然后按照进制转换的方式变成一个10进制的值再和TableSize求余(用32是因为2五次方可以用位运算)

-
常见的解决冲突的办法:
-
分离链接法:表是一个链表头节点的结构数组,冲突的关键词放该位置的链表上,链长了查找效率会下降
-
线性探测:设置一个线性的增量序列:1,2,3,4,5...,在当前位置冲突了,就有
H_1(key) = (H(key)+i) mod TableSize- 这样的缺点是会有冲突聚集现象
-
平方探测:增量序列有变化 di = +-i^2,左看看右看看,一般结合TableSize为 = 4k+3保证平方探测法不会出现死循环而探测不全空间
- 上面两种探测都属于开放定址法:要注意Hash表删除数据时并不能真的删除,而是要打上标记,以防止其他因为这个结点而产生冲突的数据查找不到
-
双哈希:冲突了就换个哈希算法再算一次
-
Resize表的大小:随着元素变多则考虑把所有元素重构一遍
设计模式类
1、MVC
Model模型对象
View 展示界面
Controller 控制器
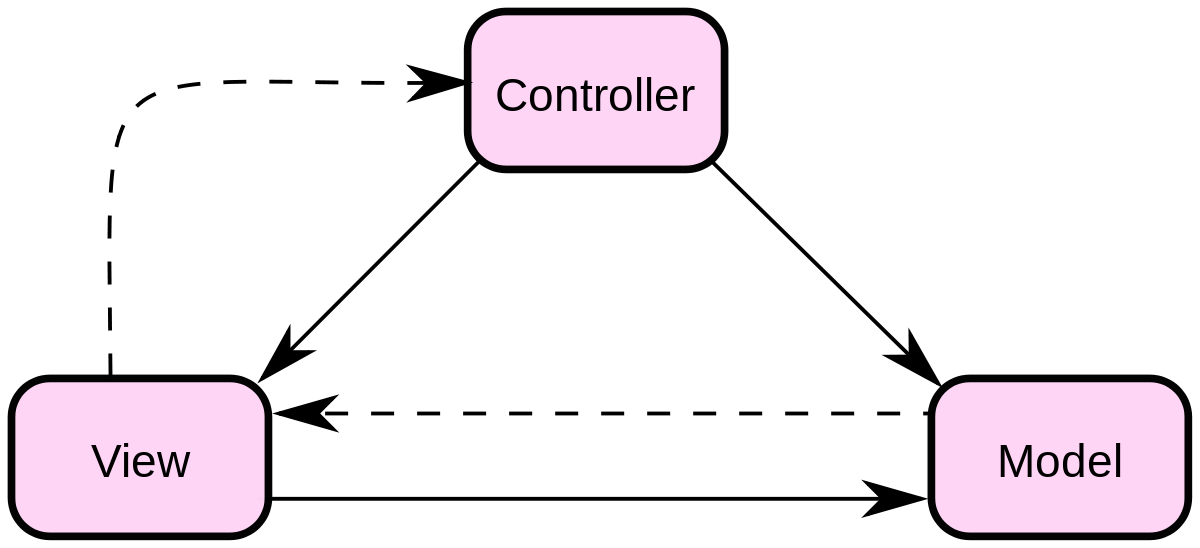
用户使用Controller里面的方法控制Controller关联的一个Model,然后更新View视图,Controller相当于一个访问对象的中介器。
个人感觉unity、一般的3d建模、绘图软件的结构都是MVC的,这种模式用于应用程序的分层开发。
2、工厂模式
管理对象创建,用来解耦编译阶段的new关键字而用工厂方法去完成对象的创建,调用者通过制定一个对象工厂来确定创建什么对象,是一种从编译耦合到运行耦合的转移

红色为稳定部分,一个是产品基类一个是工厂基类