一、dom4j解析器(使用时需要导入dom4j-1.6.1.jar包)
1、XML解析器有两类,分别是DOM和SAX。DOM一次性将整个XML文档读入内存中,形成一个倒状的树形结构;SAX分多次将整个XML文档读到内存。
2、Java里解析XML文件的方式如下图所示:
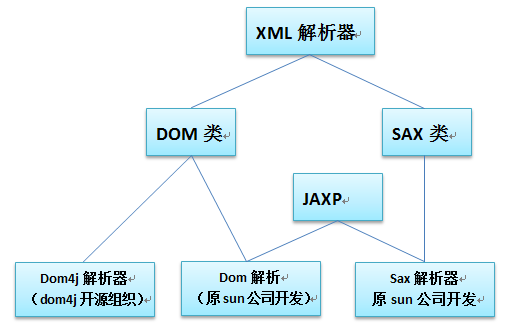
3、dom4j的使用代码如下:
package com.gnnuit.dom4j; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStream; import java.io.UnsupportedEncodingException; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.OutputFormat; import org.dom4j.io.SAXReader; import org.dom4j.io.XMLWriter; import org.junit.Test; /** * 使用Dom4j操作文件的CUD * * @author YLY * */ public class Demo2 { @Test public void create() throws Exception { Document document = getDocument(); Element rootElement = document.getRootElement(); // 取得第一辆汽车 Element firstElement = (Element) rootElement.elements().get(0); // 添加新元素“单价”,并设置文本为30 firstElement.addElement("单价").setText("30"); // 将内存中的XML写到硬盘中 write2xml(document); } @Test public void update() throws Exception { Document document = getDocument(); Element rootElement = document.getRootElement(); // 获得第一辆汽车 Element firstElement = (Element) rootElement.elements().get(0); // 将第一辆汽车的单价修改为50万 firstElement.element("单价").setText("50万"); write2xml(document); } @Test public void delete() throws Exception { Document document = getDocument(); Element rootElement = document.getRootElement(); // 获得第一辆汽车 Element firstElement = (Element) rootElement.elements().get(0); // 删除第一辆汽车的“单价”元素 Element firstCarPriceElement = firstElement.element("单价"); // 删除第一种方法 // firstElement.remove(firstCarPriceElement); // 删除第二种方法 firstCarPriceElement.getParent().remove(firstCarPriceElement); write2xml(document); } /** * 将内存中的XML写到硬盘 * * @param document * @throws FileNotFoundException * @throws UnsupportedEncodingException * @throws IOException */ private void write2xml(Document document) throws FileNotFoundException, UnsupportedEncodingException, IOException { OutputStream out = new FileOutputStream(new File( "src/com/gnnuit/dom4j/car.xml")); OutputFormat format = OutputFormat.createPrettyPrint(); XMLWriter writer = new XMLWriter(out, format); writer.write(document); writer.close(); } /** * 获取Document对象 * * @return * @throws DocumentException */ private Document getDocument() throws DocumentException { SAXReader saxReader = new SAXReader(); Document document = saxReader.read(new File( "src/com/gnnuit/dom4j/car.xml")); return document; } }
4、基于dom4j的xpath技术。能够在xml文件中快速定位需要的元素。使用XPath时除了需要dom4j-1.6.1.jar包外,还需要导入jaxen-1.1-beta-6.jar包。
5、SAX解析器:
1)sun公司提供的一个基于事件的xml解析器。
2)SAXParser是SAX解析器的核心类,在使用过程中,需要一个SAX处理器,该处理器必须扩展DefaultHandler。
3)SAX解析器在解析XML文件时,会根据XML文件此时的状态,即开始标签,结束标签,调用SAX处理器对应的方法。
4)SAX解析器在解析XML文件时,自动导航,无需像dom4j一样,人为导航。
5)SAX解析器会将空白字符当作一个有效字符对待。
6、SAX解析器实例:
package com.gnnuit.sax; import java.io.File; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes; import org.xml.sax.helpers.DefaultHandler; public class Demo1 { public static void main(String[] args) throws Exception { // 创建SAX解析器工厂 SAXParserFactory factory = SAXParserFactory.newInstance(); // 创建SAX解析器 SAXParser parse = factory.newSAXParser(); // 加载xml文件 parse.parse(new File("src/com/gnnuit/sax/car.xml"), new MyHandler()); } } // 自定义SAX处理器 class MyHandler extends DefaultHandler { public void startDocument() { System.out.println("文档开始"); } public void endDocument() { System.out.println("文档结束"); } public void startElement(String uri, String localName, String qName, Attributes attributes) { System.out.println("<" + qName + ">"); } public void endElement(String uri, String localName, String qName) { System.out.println("</" + qName + ">"); } public void characters(char[] ch, int start, int length) { String content = new String(ch, start, length).trim(); if (content.length() > 0) { System.out.println(content); } } }
7、简单工厂设计模式
1)目的就是统一管理访问层的所有Dao,让Service在Dao的处理上相对独立。
2)引用DaoFactory来管理所有的具体Dao,并采用单例模式限制DaoFactory的个数。
3)简单工厂设计模式如图所示:

8、dom解析XML文件示例:
package com.gnnuit.dom; import java.io.File; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.NodeList; public class Demo1 { public static void main(String[] args) throws Exception { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder .parse(new File("src/com/gnnuit/dom/car.xml")); Element rootElement = document.getDocumentElement(); System.out.println(rootElement.getNodeName()); NodeList nodelist = rootElement.getElementsByTagName("汽车"); System.out.println("共有" + nodelist.getLength() + "辆汽车"); for (int i = 0; i < nodelist.getLength(); i++) { System.out.println("--------------------------------------"); Element carElement = (Element) nodelist.item(i); Element brandElement = (Element) carElement.getElementsByTagName( "车牌").item(0); System.out.println("车牌:" + brandElement.getTextContent()); String time = brandElement.getAttributes().getNamedItem("出产时间") .getTextContent(); System.out.println("出产时间:" + time); Element place = (Element) carElement.getElementsByTagName("产地") .item(0); System.out.println("产地:" + place.getTextContent()); Element price = (Element) carElement.getElementsByTagName("单价") .item(0); System.out.println("单价:" + price.getTextContent()); System.out.println("--------------------------------------"); } } }