type列 其实很关键。 解释如下:
type列
这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行。
依次从最优到最差分别为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
NULL:mysql能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引。例如:在索引列中选取最小值,可以单独查找索引来完成,不需要在执行时访问表
const, system:mysql能对查询的某部分进行优化并将其转化成一个常量(可以看show warnings 的结果)。用于 primary key 或 unique key 的所有列与常数比较时,所以表最多有一个匹配行,读取1次,速度比较快。
结果是:
EXPLAIN SELECT COUNT(1) FROM actor; 走 PRIMARY 索引: Using index

—— 为什么 possible_keys 为空?
EXPLAIN SELECT COUNT(*) FROM actor; 同上
EXPLAIN SELECT COUNT(*) FROM actor WHERE id > 1; 基本同上,Extra 是 Using where; Using index

EXPLAIN SELECT COUNT(name) FROM actor; 因为 name上面没有索引, 所以是走 全表扫描。

EXPLAIN SELECT COUNT(name) FROM actor_no_key; 同上,因为 name上面没有索引, 所以是走 全表扫描。

EXPLAIN SELECT COUNT(1) FROM actor_no_key; 因为addresss字段存在唯一索引 index_addresss, 所以是 Using index, 不过 key_len 是 138 , 有点长..

EXPLAIN SELECT COUNT(id) FROM actor_no_key; 因为 id 上面没有索引, 所以是走 全表扫描。

EXPLAIN SELECT COUNT(*) FROM actor_no_key; 同EXPLAIN SELECT COUNT(1) FROM actor_no_key;

EXPLAIN SELECT COUNT(name) FROM actor_no_key WHERE id > 0; 因为 id 上面没有索引, 所以是走回表过滤(where 条件就相当于是过滤条件),(过滤 和扫描是什么区别? 可以认为过滤前需要扫描一下)。

注意 filtered 是 33.33 , 为什么其他的都是 100 ? 可能是因为数据只有三行的原因, 然后因为 1/3 = 33.33 % ? 但是新增了几行,发行 还是33.33 ..
EXPLAIN SELECT COUNT(addresss) FROM actor_no_key WHERE id > 1; 同上
EXPLAIN SELECT COUNT(1) FROM actor_no_key; 同EXPLAIN SELECT COUNT(1) FROM actor_no_key;

2
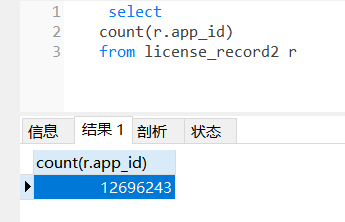
license_record2 表有 12503260 行数据, --
实际是12696243
CREATE TABLE `license_record2` (
`id` bigint(20) NOT NULL COMMENT '主键',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`created_by` varchar(20) COLLATE utf8_unicode_ci NOT NULL COMMENT '创建人',
`updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
`updated_by` varchar(20) COLLATE utf8_unicode_ci NOT NULL COMMENT '更新人',
`app_id` varchar(20) COLLATE utf8_unicode_ci NOT NULL COMMENT 'APP_ID',
`device_id` varchar(255) COLLATE utf8_unicode_ci NOT NULL COMMENT 'DEVICE_ID',
`model_id` varchar(50) COLLATE utf8_unicode_ci NOT NULL COMMENT 'model_id',
`manufacturer_id` varchar(50) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '制造商ID',
`user_id` varchar(60) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT 'user_id',
`brand_name` varchar(100) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '包名-',
`status` varchar(64) COLLATE utf8_unicode_ci NOT NULL COMMENT '状态',
`expire_date` datetime DEFAULT NULL COMMENT '到期时间',
`deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除',
`status_code` tinyint(4) NOT NULL DEFAULT '1' COMMENT '授权状态,0、失败1、成功2、撤回',
`ip_address` varchar(100) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT 'ip地址',
`sign` varchar(2) COLLATE utf8_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `app_id` (`app_id`,`device_id`,`manufacturer_id`,`model_id`,`brand_name`,`status_code`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci ROW_FORMAT=DYNAMIC;
注意索引: `app_id`, `device_id`, `manufacturer_id`, `model_id`, `brand_name`, `status_code`
EXPLAIN SELECT * FROM lic_s_0.`license_record2` WHERE app_id = '20210525104140854' and device_id = '00000000-0691-d628-0000-00004394fc4f' and manufacturer_id = 'vivo' and model_id = 'PA2170' and status_code = 1 ORDER BY updated_at desc limit 1 ;

可以看到const,const,const,const, 竟然有四个 const! Extra 是Using index condition; Using filesort, 为什么是Using index condition; 而不是 Using index ? 因为SELECT * 并不能走覆盖索引。 为什么Using filesort ? 因为有 order by。。
虽然 limit 1 , 但是还是进行了排序。 why , 因为 limit 语句必须在 order by 后面执行, 所以 ,
继续
EXPLAIN SELECT app_id FROM `license_record2` WHERE app_id = '20210525104140854' and device_id = '00000000-0691-d628-0000-00004394fc4f' and manufacturer_id = 'vivo' and model_id = 'PA2170' and brand_name = 'huawei' and status_code = 1 ;
EXPLAIN SELECT app_id FROM `license_record2` WHERE app_id = '20210525104140854' and device_id = '00000000-0691-d628-0000-00004394fc4f' and manufacturer_id = 'vivo' and model_id = 'PA2170' ;
EXPLAIN SELECT app_id FROM `license_record2` WHERE app_id = '20210525104140854' and device_id = '00000000-0691-d628-0000-00004394fc4f' and manufacturer_id = 'vivo' ;
EXPLAIN SELECT app_id FROM `license_record2` WHERE app_id = '20210525104140854' and device_id = '00000000-0691-d628-0000-00004394fc4f' ;
EXPLAIN SELECT app_id FROM `license_record2` WHERE app_id = '20210525104140854' ;
EXPLAIN SELECT app_id FROM `license_record2` WHERE app_id = '20210525104140854' and device_id = '00000000-0691-d628-0000-00004394fc4f' and manufacturer_id = 'vivo' and model_id = 'PA2170' and status_code = 1 ;
EXPLAIN SELECT app_id FROM `license_record2` where device_id = '00000000-016a-76e5-0000-000052c2195a' and status_code = 2 limit 1 ;
EXPLAIN SELECT app_id FROM `license_record2` where device_id = '00000000-016a-76e5-0000-000052c2195a' and status_code = 2 limit 1 ;
EXPLAIN SELECT app_id FROM `license_record2` where status_code = 2 limit 1
发现
EXPLAIN SELECT app_id FROM `license_record2` WHERE app_id = '20210525104140854' and device_id = '00000000-0691-d628-0000-00004394fc4f' and manufacturer_id = 'vivo' and model_id = 'PA2170' and brand_name = 'huawei' and status_code = 1 ;
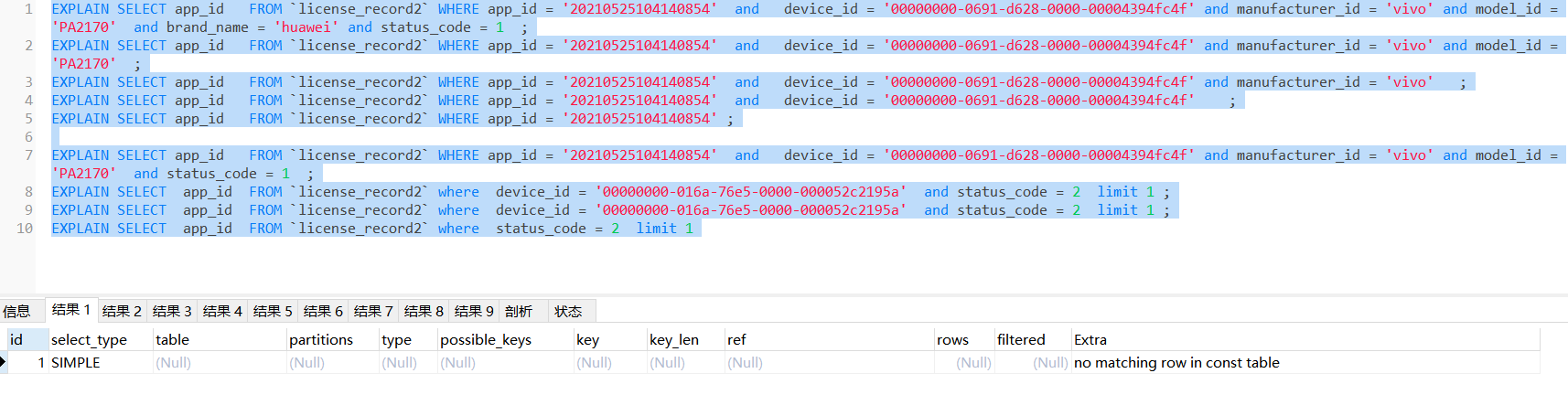
竟然提示没有匹配的row 即行
EXPLAIN SELECT app_id FROM `license_record2` WHERE app_id = '20210525104140854' and device_id = '00000000-0691-d628-0000-00004394fc4f' and manufacturer_id = 'vivo' and model_id = 'PA2170' ;

直接走了 index索引,ref 为4个const
EXPLAIN SELECT app_id FROM `license_record2` WHERE app_id = '20210525104140854' and device_id = '00000000-0691-d628-0000-00004394fc4f' and manufacturer_id = 'vivo' ;

直接走了 index索引,ref 为3
EXPLAIN SELECT app_id FROM `license_record2` WHERE app_id = '20210525104140854' and device_id = '00000000-0691-d628-0000-00004394fc4f' ;

直接走了 index索引,ref 为2
可以看到 key 都是一样的, type 都是ref,key_len 快速的变小,同时 ref 从4 到3 到现在的2,
EXPLAIN SELECT app_id FROM `license_record2` WHERE app_id = '20210525104140854' ;

同样的直接走了 index索引,不过为啥这次扫描的rows 这么多? 大概因为 相同app_id 为 20210525104140854 的有 12540行
EXPLAIN SELECT app_id FROM `license_record2` WHERE app_id = '20210525104140854' and device_id = '00000000-0691-d628-0000-00004394fc4f' and manufacturer_id = 'vivo' and model_id = 'PA2170' and status_code = 1 ;

走了 index索引,ref 为4个const, 同时 使用了Using where; —— why ? 因为查询字段虽然有status_code ,但没有 brand_name , 断开了也不行, 无法走覆盖索引, 只能回表过滤查询, 即Using where
EXPLAIN SELECT app_id FROM `license_record2` where device_id = '00000000-016a-76e5-0000-000052c2195a' and status_code = 2 limit 1 ;

虽然 复合索引包括了device_id 、 status_code , key 也似乎用上了app_id, 但是 ref 为null,type为index,key_len 很长,扫描的rows 有12503240, 使用了回表过滤: Using where;
同时感觉所用了索引, Using index —— 但,不知道实际执行的时候会不会使用索引,感觉应该不会。
注意到 possible_keys ref 都是空, 说明什么?
EXPLAIN SELECT app_id FROM `license_record2` where device_id = '00000000-016a-76e5-0000-000052c2195a' and status_code = 2 limit 1 ;
同上, 重复了
EXPLAIN SELECT app_id FROM `license_record2` where status_code = 2 limit 1
同上, 少了device_id 字段并没有什么影响。
EXPLAIN select count(r.app_id) from license_record2 r where r.deleted != 1

去掉 where条件:

where 条件导致不走索引!
少了1, 有一行被删除!
参考:
https://cloud.tencent.com/developer/article/1093229
https://blog.51cto.com/ajisun/5222707