包括卷积神经网络(CNN)在内的各种前馈神经网络模型, 其一次前馈过程的输出只与当前输入有关与历史输入无关.
递归神经网络(Recurrent Neural Network, RNN)充分挖掘了序列数据中的信息, 在时间序列和自然语言处理方面有着重要的应用.
递归神经网络可以展开为普通的前馈神经网络:
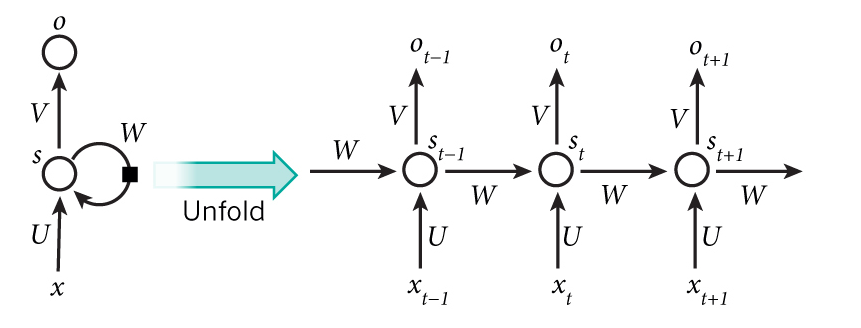
长短期记忆模型(Long-Short Term Memory)是RNN的常用实现. 与一般神经网络的神经元相比, LSTM神经元多了一个遗忘门.
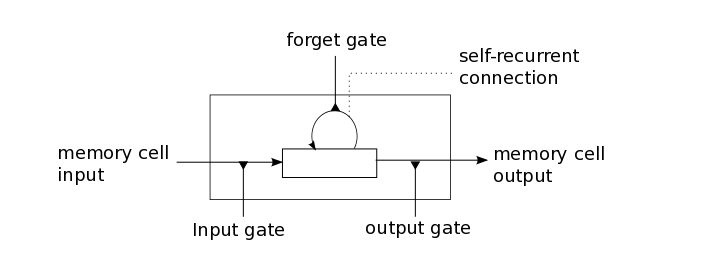
LSTM神经元的输出除了与当前输入有关外, 还与自身记忆有关. RNN的训练算法也是基于传统BP算法增加了时间考量, 称为BPTT(Back-propagation Through Time)算法.
使用tensorflow内置rnn
tensorflow内置了递归神经网络的实现:
from tensorflow.python.ops import rnn, rnn_cell
tensorflow目前正在快速迭代中, 上述路径可能会发生变化.在0.6.0版本中上述路径是有效的.
官方教程中已经加入了循环神经网络的部分, API可能不会发生太大变化.
Tensorflow有多种rnn神经元可供选择:
-
rnn_cell.BasicLSTMCell -
rnn_cell.LSTMCell -
rnn_cell.GRUCell
这里我们选用最简单的BasicLSTMCell, 需要设置神经元个数和forget_bias参数:
self.lstm_cell = rnn_cell.BasicLSTMCell(hidden_n, forget_bias=1.0)
可以直接调用cell对象获得输出和状态:
output, state = cell(inputs, state)
使用dropout避免过拟合问题:
from tensorflow.python.ops.rnn_cell import Dropoutwrapper
cells = DropoutWrapper(lstm_cell, input_keep_prob=0.5, output_keep_prob=0.5)
使用MultiRNNCell来创建多层神经网络:
from tensorflow.python.ops.rnn_cell import MultiRNNCell
cells = MultiRNNCell([lstm_cell_1, lstm_cell_2])
不过rnn.rnn可以替我们完成神经网络的构建工作:
outputs, states = rnn.rnn(self.lstm_cell, self.input_layer, dtype=tf.float32)
再加一个输出层进行输出:
self.prediction = tf.matmul(outputs[-1], self.weights) + self.biases
定义损失函数:
self.loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(self.prediction, self.label_layer))
使用Adam优化器进行训练:
self.trainer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(self.loss)
因为神经网络需要处理序列数据, 所以输入层略复杂:
self.input_layer = [tf.placeholder("float", [step_n, input_n]) for i in range(batch_size)]
tensorflow要求RNNCell的输入为一个列表, 列表中的每一项作为一个批次进行训练.
列表中的每一个元素代表一个序列, 每一行为序列中的一项. 这样每一项为一个形状为(序列长, 输入维数)的矩阵.
标签还是和原来一样为形如(序列长, 输出维度)的矩阵:
self.label_layer = tf.placeholder("float", [step_n, output_n])
执行训练:
self.session.run(initer)
for i in range(limit):
self.session.run(self.trainer, feed_dict={self.input_layer[0]: train_x[0], self.label_layer: train_y})
因为input_layer为列表, 而列表不能作为字典的键.所以我们只能采用{self.input_layer[0]: train_x[0]}这样的方式输入数据.
可以看到lable_layer也是二维的, 并没有输入多个批次的数据. 考虑到这两点, 目前这个实现并不具备多批次处理的能力.
序列的长度通常是不同的, 而目前的实现采用的是定长输入. 这是需要解决的另一个难题.
完整源代码可以在demo.py中查看.