头图 | 下载于视觉中国
数据、算法、算力是人工智能发展的三要素。数据决定了Ai模型学习的上限,数据规模越大、质量越高,模型就能够拥有更好的泛化能力。
然而在实际工程中,经常有数据量太少(相对模型而言)、样本不均衡、很难覆盖全部的场景等问题,解决这类问题的一个有效途径是通过数据增强(Data Augmentation),使模型学习获得较好的泛化性能。


数据增强介绍
数据增强(Data Augmentation)是在不实质性的增加数据的情况下,从原始数据加工出更多的表示,提高原数据的数量及质量,以接近于更多数据量产生的价值。其原理是,通过对原始数据融入先验知识,加工出更多数据的表示,有助于模型判别数据中统计噪声,加强本体特征的学习,减少模型过拟合,提升泛化能力。
如经典的机器学习例子--哈士奇误分类为狼:通过可解释性方法,可发现错误分类是由于图像上的雪造成的。通常狗对比狼的图像里面雪地背景比较少,分类器学会使用雪作为一个特征来将图像分类为狼还是狗,而忽略了动物本体的特征。此时,可以通过数据增强的方法,增加变换后的数据(如背景换色、加入噪声等方式)来训练模型,帮助模型学习到本体的特征,提高泛化能力。

需要关注的是,数据增强样本也有可能是引入片面噪声,导致过拟合。此时需要考虑的是调整数据增强方法,或者通过算法(可借鉴Pu-Learning思路)选择增强数据的最佳子集,以提高模型的泛化能力。
常用数据增强方法可分为:基于样本变换的数据增强及基于深度学习的数据增强。

基于样本变换的数据增强
样本变换数据增强即采用预设的数据变换规则进行已有数据的扩增,包含单样本数据增强和多样本数据增强。
2.1 单样本增强
单(图像)样本增强主要有几何操作、颜色变换、随机擦除、添加噪声等方法,可参见imgaug开源库。

2.2 多样本数据增强方法
多样本增强是通过先验知识组合及转换多个样本,主要有Smote、SamplePairing、Mixup等方法在特征空间内构造已知样本的邻域值。
-
Smote
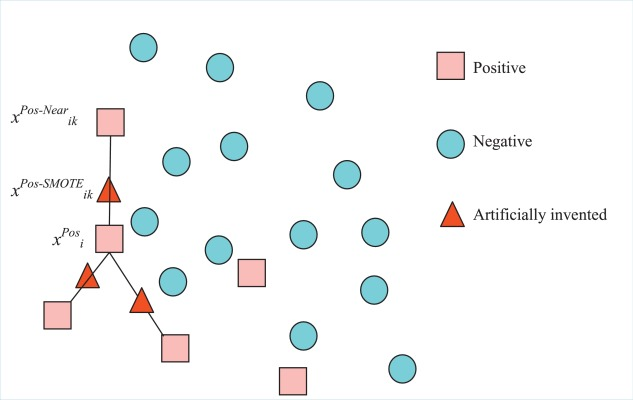
Smote(Synthetic Minority Over-sampling Technique)方法较常用于样本均衡学习,核心思想是从训练集随机同类的两近邻样本合成一个新的样本,其方法可以分为三步:
1、 对于各样本X_i,计算与同类样本的欧式距离,确定其同类的K个(如图3个)近邻样本;
2、从该样本k近邻中随机选择一个样本如近邻X_ik,生成新的样本:
Xsmote_ik = Xi + rand(0,1) ∗ ∣X_i − X_ik∣
3、重复2步骤迭代N次,可以合成N个新的样本。
-
# SMOTE
-
from imblearn.over_sampling import SMOTE
-
-
print("Before OverSampling, counts of label {}".format(y_train.value_counts()))
-
smote = SMOTE()
-
x_train_res, y_train_res = smote.fit_resample(x_train, y_train)
-
print("After OverSampling, counts of label {}".format(y_train_res.value_counts()))
-
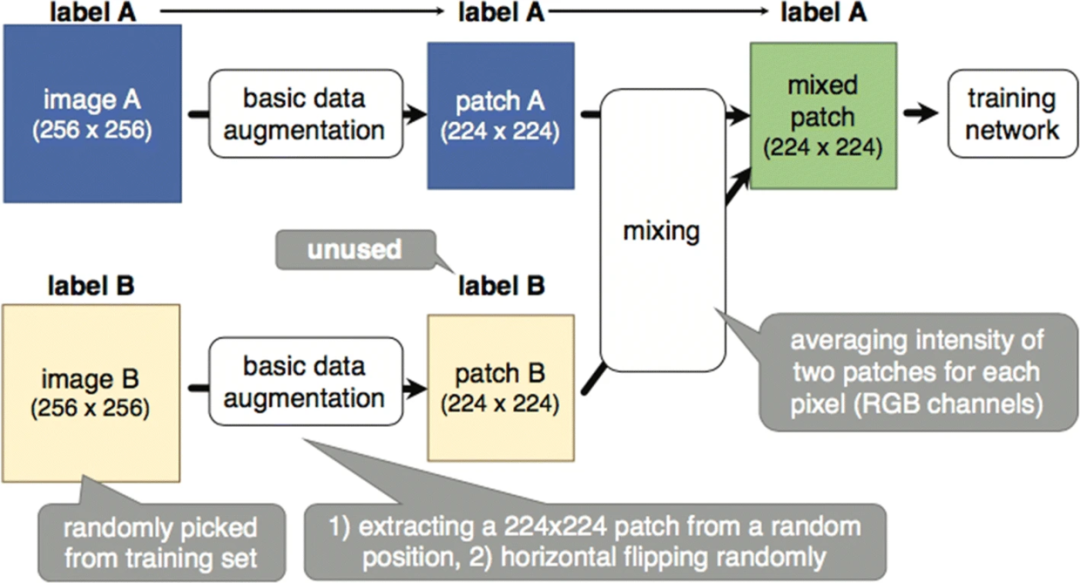
SamplePairing
SamplePairing算法的核心思想是从训练集随机抽取的两幅图像叠加合成一个新的样本(像素取平均值),使用第一幅图像的label作为合成图像的正确label。
-
Mixup
Mixup算法的核心思想是按一定的比例随机混合两个训练样本及其标签,这种混合方式不仅能够增加样本的多样性,且能够使决策边界更加平滑,增强了难例样本的识别,模型的鲁棒性得到提升。其方法可以分为两步:
1、从原始训练数据中随机选取的两个样本(xi, yi) and (xj, yj)。其中y(原始label)用one-hot 编码。
2、对两个样本按比例组合,形成新的样本和带权重的标签
-
x˜ = λxi + (1 − λ)xj
-
y˜ = λyi + (1 − λ)yj
最终的loss为各标签上分别计算cross-entropy loss,加权求和。其中 λ ∈ [0, 1], λ是mixup的超参数,控制两个样本插值的强度。

-
-
-
# Mixup
-
def mixup_batch(x, y, step, batch_size, alpha=0.2):
-
"""
-
get batch data
-
:param x: training data
-
:param y: one-hot label
-
:param step: step
-
:param batch_size: batch size
-
:param alpha: hyper-parameter α, default as 0.2
-
:return: x y
-
"""
-
candidates_data, candidates_label = x, y
-
offset = (step * batch_size) % (candidates_data.shape[0] - batch_size)
-
-
# get batch data
-
train_features_batch = candidates_data[offset:(offset + batch_size)]
-
train_labels_batch = candidates_label[offset:(offset + batch_size)]
-
-
if alpha == 0:
-
return train_features_batch, train_labels_batch
-
-
if alpha > 0:
-
weight = np.random.beta(alpha, alpha, batch_size)
-
x_weight = weight.reshape(batch_size, 1)
-
y_weight = weight.reshape(batch_size, 1)
-
index = np.random.permutation(batch_size)
-
x1, x2 = train_features_batch, train_features_batch[index]
-
x = x1 * x_weight + x2 * (1 - x_weight)
-
y1, y2 = train_labels_batch, train_labels_batch[index]
-
y = y1 * y_weight + y2 * (1 - y_weight)
-
return x, y
-
-
-
-
-
基于深度学习的数据增强
-
-
-
3.1 特征空间的数据增强
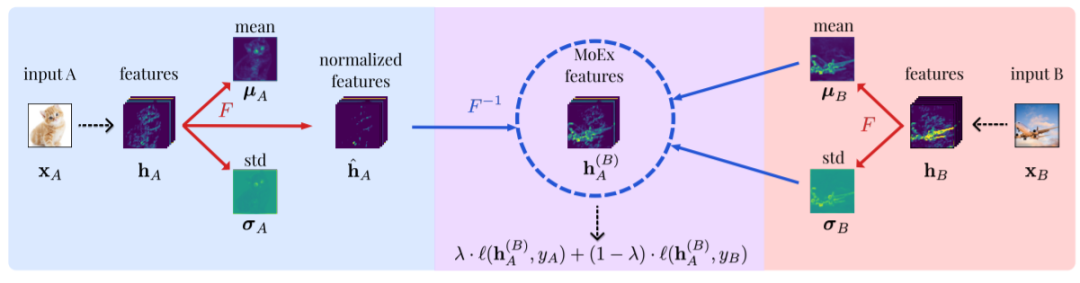
不同于传统在输入空间变换的数据增强方法,神经网络可将输入样本映射为网络层的低维向量(表征学习),从而直接在学习的特征空间进行组合变换等进行数据增强,如MoEx方法等。
3.2 基于生成模型的数据增强
生成模型如变分自编码网络(Variational Auto-Encoding network, VAE)和生成对抗网络(Generative Adversarial Network, GAN),其生成样本的方法也可以用于数据增强。这种基于网络合成的方法相比于传统的数据增强技术虽然过程更加复杂, 但是生成的样本更加多样。
-
变分自编码器VAE
变分自编码器(Variational Autoencoder,VAE)其基本思路是:将真实样本通过编码器网络变换成一个理想的数据分布,然后把数据分布再传递给解码器网络,构造出生成样本,模型训练学习的过程是使生成样本与真实样本足够接近。
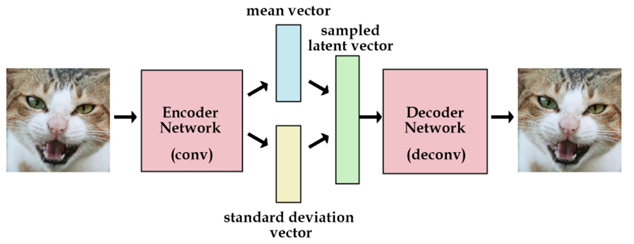
-
# VAE模型
-
class VAE(keras.Model):
-
...
-
def train_step(self, data):
-
with tf.GradientTape() as tape:
-
z_mean, z_log_var, z = self.encoder(data)
-
reconstruction = self.decoder(z)
-
reconstruction_loss = tf.reduce_mean(
-
tf.reduce_sum(
-
keras.losses.binary_crossentropy(data, reconstruction), axis=(1, 2)
-
)
-
)
-
kl_loss = -0.5 * (1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var))
-
kl_loss = tf.reduce_mean(tf.reduce_sum(kl_loss, axis=1))
-
total_loss = reconstruction_loss + kl_loss
-
grads = tape.gradient(total_loss, self.trainable_weights)
-
self.optimizer.apply_gradients(zip(grads, self.trainable_weights))
-
self.total_loss_tracker.update_state(total_loss)
-
self.reconstruction_loss_tracker.update_state(reconstruction_loss)
-
self.kl_loss_tracker.update_state(kl_loss)
-
return {
-
"loss": self.total_loss_tracker.result(),
-
"reconstruction_loss": self.reconstruction_loss_tracker.result(),
-
"kl_loss": self.kl_loss_tracker.result(),
-
}
-
-
-
-
生成对抗网络GAN
生成对抗网络-GAN(Generative Adversarial Network) 由生成网络(Generator, G)和判别网络(Discriminator, D)两部分组成, 生成网络构成一个映射函数G: Z→X(输入噪声z, 输出生成的图像数据x), 判别网络判别输入是来自真实数据还是生成网络生成的数据。
-

-
# DCGAN模型
-
-
class GAN(keras.Model):
-
...
-
def train_step(self, real_images):
-
batch_size = tf.shape(real_images)[0]
-
random_latent_vectors = tf.random.normal(shape=(batch_size, self.latent_dim))
-
# G: Z→X(输入噪声z, 输出生成的图像数据x)
-
generated_images = self.generator(random_latent_vectors)
-
# 合并生成及真实的样本并赋判定的标签
-
combined_images = tf.concat([generated_images, real_images], axis=0)
-
labels = tf.concat(
-
[tf.ones((batch_size, 1)), tf.zeros((batch_size, 1))], axis=0
-
)
-
# 标签加入随机噪声
-
labels += 0.05 * tf.random.uniform(tf.shape(labels))
-
# 训练判定网络
-
with tf.GradientTape() as tape:
-
predictions = self.discriminator(combined_images)
-
d_loss = self.loss_fn(labels, predictions)
-
grads = tape.gradient(d_loss, self.discriminator.trainable_weights)
-
self.d_optimizer.apply_gradients(
-
zip(grads, self.discriminator.trainable_weights)
-
)
-
-
random_latent_vectors = tf.random.normal(shape=(batch_size, self.latent_dim))
-
# 赋生成网络样本的标签(都赋为真实样本)
-
misleading_labels = tf.zeros((batch_size, 1))
-
# 训练生成网络
-
with tf.GradientTape() as tape:
-
predictions = self.discriminator(self.generator(random_latent_vectors))
-
g_loss = self.loss_fn(misleading_labels, predictions)
-
grads = tape.gradient(g_loss, self.generator.trainable_weights)
-
self.g_optimizer.apply_gradients(zip(grads, self.generator.trainable_weights))
-
# 更新损失
-
self.d_loss_metric.update_state(d_loss)
-
self.g_loss_metric.update_state(g_loss)
-
return {
-
"d_loss": self.d_loss_metric.result(),
-
"g_loss": self.g_loss_metric.result(),
-
}
-
3.3 基于神经风格迁移的数据增强
神经风格迁移(Neural Style Transfer)可以在保留原始内容的同时,将一个图像的样式转移到另一个图像上。除了实现类似色彩空间照明转换,还可以生成不同的纹理和艺术风格。

神经风格迁移是通过优化三类的损失来实现的:
style_loss:使生成的图像接近样式参考图像的局部纹理;
content_loss:使生成的图像的内容表示接近于基本图像的表示;
total_variation_loss:是一个正则化损失,它使生成的图像保持局部一致。
-
-
-
# 样式损失
-
def style_loss(style, combination):
-
S = gram_matrix(style)
-
C = gram_matrix(combination)
-
channels = 3
-
size = img_nrows * img_ncols
-
return tf.reduce_sum(tf.square(S - C)) / (4.0 * (channels ** 2) * (size ** 2))
-
-
# 内容损失
-
def content_loss(base, combination):
-
return tf.reduce_sum(tf.square(combination - base))
-
-
# 正则损失
-
def total_variation_loss(x):
-
a = tf.square(
-
x[:, : img_nrows - 1, : img_ncols - 1, :] - x[:, 1:, : img_ncols - 1, :]
-
)
-
b = tf.square(
-
x[:, : img_nrows - 1, : img_ncols - 1, :] - x[:, : img_nrows - 1, 1:, :]
-
)
-
return tf.reduce_sum(tf.pow(a + b, 1.25))
-
-
-
3.4 基于元学习的数据增强
深度学习研究中的元学习(Meta learning)通常是指使用神经网络优化神经网络,元学习的数据增强有神经增强(Neural augmentation)等方法。
-
神经增强
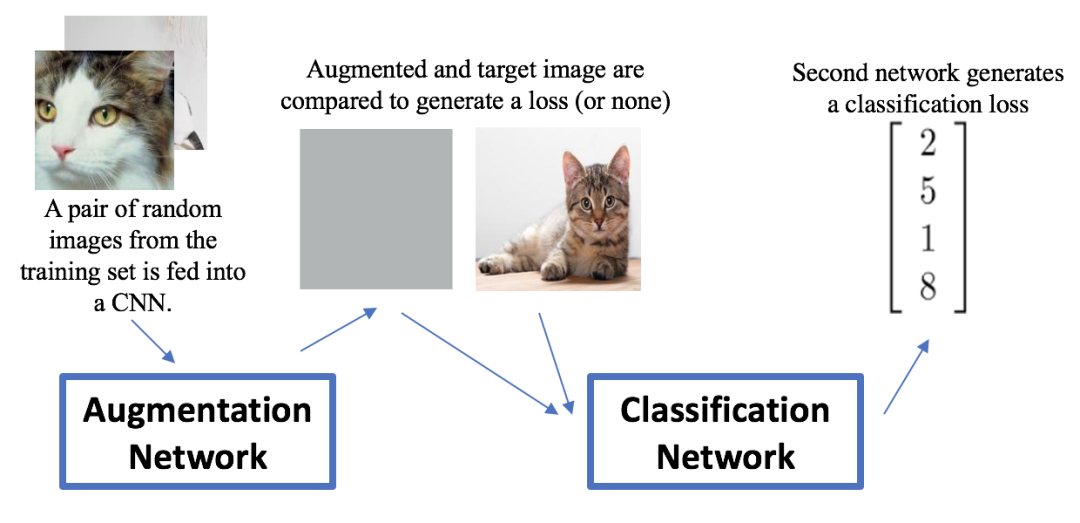
神经增强(Neural augmentation)是通过神经网络组的学习以获得较优的数据增强并改善分类效果的一种方法。其方法步骤如下:
1、获取与target图像同一类别的一对随机图像,前置的增强网络通过CNN将它们映射为合成图像,合成图像与target图像对比计算损失;
2、将合成图像与target图像神经风格转换后输入到分类网络中,并输出该图像分类损失;
3、将增强与分类的loss加权平均后,反向传播以更新分类网络及增强网络权重。使得其输出图像的同类内差距减小且分类准确。