一、hive环境准备
1、安装hive
按照hive安装步骤安装好hive
CREATE USER 'spark'@'%' IDENTIFIED BY '123456';
GRANT all privileges ON hive.* TO 'spark'@'%';
- 1
- 2
flush privileges;
2、环境配置
将配置好的hive-site.xml放入$SPARK-HOME/conf目录下,,下载mysql连接驱动,并拷贝至spark/lib目录下
启动spark-shell时指定mysql连接驱动位置
bin/spark-shell --master spark://mini1:7077 --executor-memory 1g --total-executor-cores 2 --driver-class-path /home/hadoop/spark/lib/mysql-connector-java-5.1.35-bin.jar
- 1
二、Spark SQL
1、概述
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
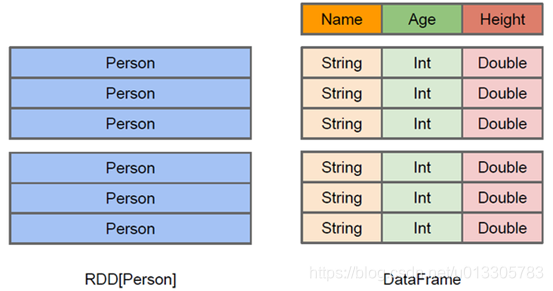
2、DataFrames
与RDD类似,DataFrame也是一个分布式数据容器。然而DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从API易用性的角度上 看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。由于与R和Pandas的DataFrame类似,Spark DataFrame很好地继承了传统单机数据分析的开发体验。
3、操作实例
from pyspark import Row
from pyspark.sql import SparkSession
from pyspark.sql.types import StructField, StringType, StructType
if __name__ == "__main__":
spark = SparkSession
.builder
.appName("PythonWordCount")
.master("local")
.getOrCreate()
sc = spark.sparkContext
line = sc.textFile("D:\code\hadoop\data\spark\day4\person.txt").map(lambda x: x.split(' '))
# personRdd = line.map(lambda p: Row(id=p[0], name=p[1], age=int(p[2])))
# personRdd_tmp = spark.createDataFrame(personRdd)
# personRdd_tmp.show()
#读取数据
schemaString = "id name age"
fields = list(map(lambda fieldName: StructField(fieldName, StringType(), nullable=True), schemaString.split(" ")))
schema = StructType(fields)
rowRDD = line.map(lambda attributes: Row(attributes[0], attributes[1],attributes[2]))
peopleDF = spark.createDataFrame(rowRDD, schema)
peopleDF.createOrReplaceTempView("people")
results = spark.sql("SELECT * FROM people")
results.rdd.map(lambda attributes: "name: " + attributes[0] + "," + "age:" + attributes[1]).foreach(print)
# SQL风格语法
# personRdd_tmp.registerTempTable("person")
# spark.sql("select * from person where age >= 20 order by age desc limit 2").show()
#方法风格语法
# personRdd_tmp.select("name").show()
# personRdd_tmp.select(personRdd_tmp['name'], personRdd_tmp['age'] + 1).show()
# personRdd_tmp.filter(personRdd_tmp['age'] > 21).show()
# personRdd_tmp.groupBy("age").count().show()
# personRdd_tmp.createOrReplaceTempView("people")
# sqlDF = spark.sql("SELECT * FROM people")
# sqlDF.show()
# personRdd_tmp.createGlobalTempView("people")
# spark.sql("SELECT * FROM global_temp.people").show()
#
# spark.newSession().sql("SELECT * FROM global_temp.people").show()
# 保存为指定格式
# people = line.map(lambda p: (p[0],p[1], p[2].strip()))
# schemaString = "id name age"
#
# fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split()]
# # # 通过StructType直接指定每个字段的schema
# schema = StructType(fields)
# schemaPeople = spark.createDataFrame(people, schema)
# schemaPeople.createOrReplaceTempView("people")
# results = spark.sql("SELECT * FROM people")
# results.write.json("D:\code\hadoop\data\spark\day4\personout.txt")
# results.write.save("D:\code\hadoop\data\spark\day4\personout1")
# results.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
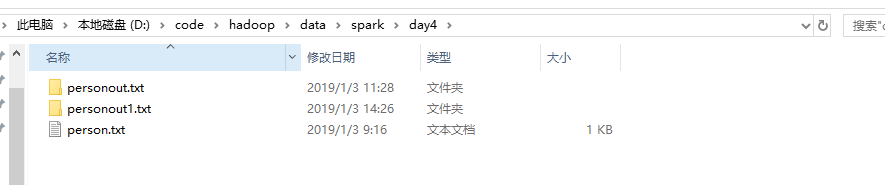
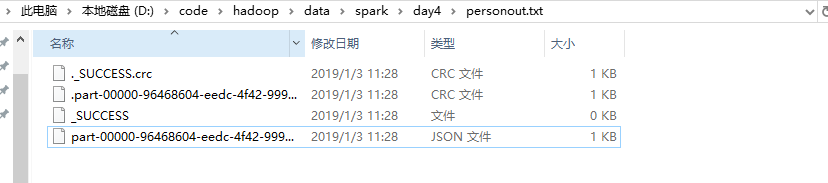
结果如下:

保存为JSON文件如下
从mysql中读写数据
#JDBC
# sqlContext = SQLContext(sc)
# df = sqlContext.read.format("jdbc").options(url="jdbc:mysql://localhost:3306/hellospark",
# driver="com.mysql.jdbc.Driver", dbtable="(select * from actor) tmp",
# user="root", password="123456").load()
# schemaPeople.write
# .format("jdbc")
# .option("url", "jdbc:mysql://localhost:3306/hellospark")
# .option("dbtable", "person")
# .option("user", "root")
# .option("password", "123456")
# .mode("append")
# .save()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
三、Spark Sql + Hive
需要指定warehouse_location,并将配置好的hive-site.xml放入$SPARK-HOME/conf目录下
from os.path import abspath
from pyspark.sql import SparkSession
# from pyspark.sql.types import StructField, StringType, StructType
if __name__ == "__main__":
# spark = SparkSession
# .builder
# .appName("PythonWordCount")
# .master("spark://mini1:7077")
# .getOrCreate()
# sc = spark.sparkContext
warehouse_location = abspath('spark-warehouse')
spark = SparkSession
.builder
.appName("Python Spark SQL Hive integration example")
.config("spark.sql.warehouse.dir", warehouse_location)
.enableHiveSupport()
.getOrCreate()
# spark.sql("CREATE TABLE IF NOT EXISTS person(id STRING, name STRING,age STRING) row format delimited fields terminated by ' '")
# spark.sql("LOAD DATA INPATH 'hdfs://mini1:9000/person/data/person.txt' INTO TABLE person")
spark.sql("SELECT * FROM person").show()
# line = sc.textFile("hdfs://mini1:9000/person/data/person.txt").map(lambda x: x.split(' '))
# people = line.map(lambda p: (p[0],p[1], p[2].strip()))
# schemaString = "id name age"
#
# fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split()]
# # # 通过StructType直接指定每个字段的schema
# schema = StructType(fields)
# schemaPeople = spark.createDataFrame(people, schema)
# schemaPeople.createOrReplaceTempView("people")
#
# schemaPeople.write
# .format("jdbc")
# .option("url", "jdbc:mysql://192.168.62.132:3306/hellospark")
# .option("dbtable", "person")
# .option("user", "root")
# .option("password", "123456you")
# .mode("append")
# .save()
spark.stop()
# sc.stop()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
还可以使用org.apache.spark.sql.hive.HiveContext来实现。