前面几节讲的都是单机 RPC 服务的模式,无论是多线程也好多进程也好,它们都只能算是单点的设计。现代企业的关键性 RPC 服务是绝不可以只使用单点部署的。本节我们要对 RPC 服务进行分布式化,使得服务可以容忍个别节点故障仍能继续对外提供服务。
客户端
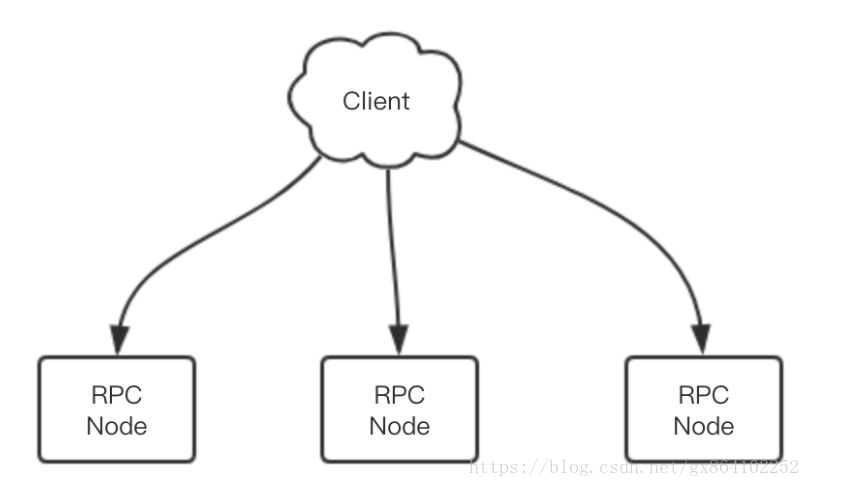
当 RPC 服务部署在多个节点上时,客户端得到的是一个服务列表,有多个 IP 端口对。客户端的连接池可以随机地挑选任意的 RPC 服务节点进行连接。
每个服务节点应该有个权重值,当所有节点的权重值一样时,它们的流量分配就是均匀的。如果某个节点的相对权重值较小,它被客户端选中的概率也会相对比较小。
class RPCNode {
String addr; // 服务地址
int weight; // 节点权重
}
class RPCCluster {
RPCNode[] nodes; // 节点列表
Node random(); // 按权重随机挑选节点
}容灾Failover
当有一个服务节点挂掉时,客户端需要采取一定的策略避免请求失败。当请求失败时,客户端还要进行重试,但是也不可以无限重试,要有一定的重试策略。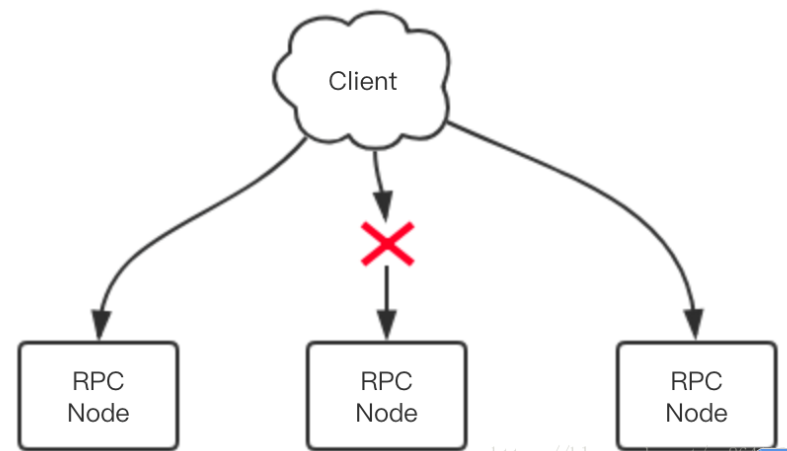
比如当节点挂掉时,将失效节点摘除,放置到失效节点列表中。然后每隔一段时间检查失效节点是否恢复了,如果恢复了,那就从失效节点中移除,再将节点地址重新加入到有效节点列表中。那如何判断节点真的挂掉了呢,一般需要设置一个时间窗口,统计在一定时间窗口里出现的错误数量。如果这个数量过大,那就意味着失效了。这也是为了防止网络偶然抖动导致服务节点流量的大幅波动。
降权法
上面提到客户端会为每个节点赋予一个权值,改变权值就可以改变节点的相对流量。如果某个节点出现了一次调用错误,可以对该节点进行降权。如果错误次数过多,降权会降的很快,最终达到一个最小值。之所以不应该降到零,那是为了给节点提供一个恢复的机会。被降权的节点后来只要有一次调用成功,那么 weight 值就应该尽快被还原,这样节点就可以快速恢复为正常节点。
客户端一次调用失败会尝试重试。如果降权太慢,会导致重试次数太多,因为第二次随机挑选节点时还是很有可能再次挑选到失效节点。降权太快也不好,网络抖动会导致节点流量分配的快速抖动,瞬间从正常降到近零,又可以瞬间从近零恢复到正常。
一个简单的策略是权重减半法。错误一次权重减半,连续错误两次权重就降到 1/4,如此直到降到最小值。如果初始权重值是 1024,那么权重值就会逐渐衰减1024=>512=>256=>128=>64=>32=>16=>8=>4=>2=>1。如果节点恢复了,那么调用会成功,权重就可以直接恢复到正常值,也可以通过加倍法逐渐恢复到正常值1=>2=>4=>8=>16=>32=>64=>128=>256=>512=>1024。如果希望恢复的更快一点,可以通过乘 4 法,乘 8 法。
服务发现
健壮的服务应该是可以支持动态扩容的服务。比如 RPC 服务压力过大,希望通过增加节点的方式来减小单个 RPC 服务的压力。如果使用的是前面的静态 RPC 服务地址列表,那么当节点增加时,我们需要修改客户端的配置重启才能生效。
通过服务发现技术,当 RPC 服务节点增加或减少时,客户端可以动态快速收到服务列表的变更信息,从而可以实时调整连接配置,这样无需重启就可以完成服务的扩容和缩容。
class ServiceDiscovery(object):
def register_service(self, name, addr):
pass
def get_services(self, name):
pass
def on_services_changed(self, name):
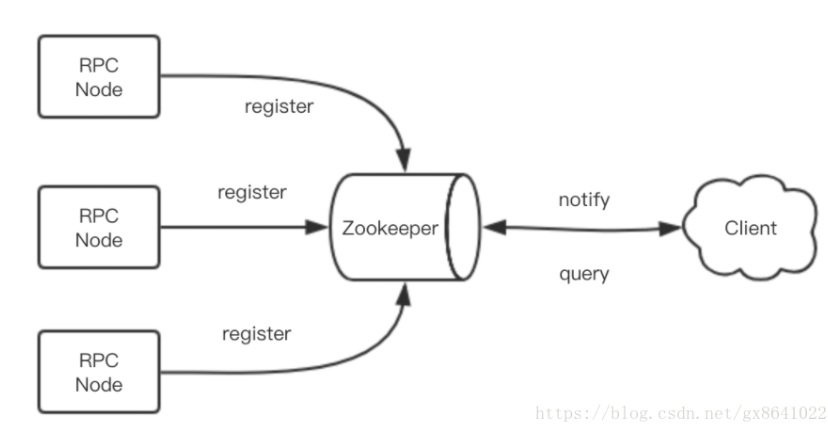
pass服务发现技术依赖于服务之间的特殊中间节点。这个节点的作用就是接受服务的注册,提供服务的查找,以及服务列表变更的实时通知功能。它一般使用支持高可用的分布式配置数据库作为解决方案,如 zookeeper/etcd 等。
- 服务注册——服务节点在启动时将自己的服务地址注册到中间节点
- 服务查找——客户端启动时去中间节点查询服务地址列表
- 服务变更通知——客户端在中间节点上订阅依赖服务列表的变更事件。当依赖的服务列表变更时,中间节点负责将变更信息实时通知给客户端。
小结
分布式的原理并没有它的名字听起来那样复杂,它在本质上也不过是将多个单机服务组合在一起对外提供服务。