关键字:算法工程的类图,架构分析,设计模式,组合模式
首先,上一个我刚完成的针对上一篇Knowledge_SPA——精研查找算法文中使用的工程,所画的类图,由此来分析它的架构。如下图所示:
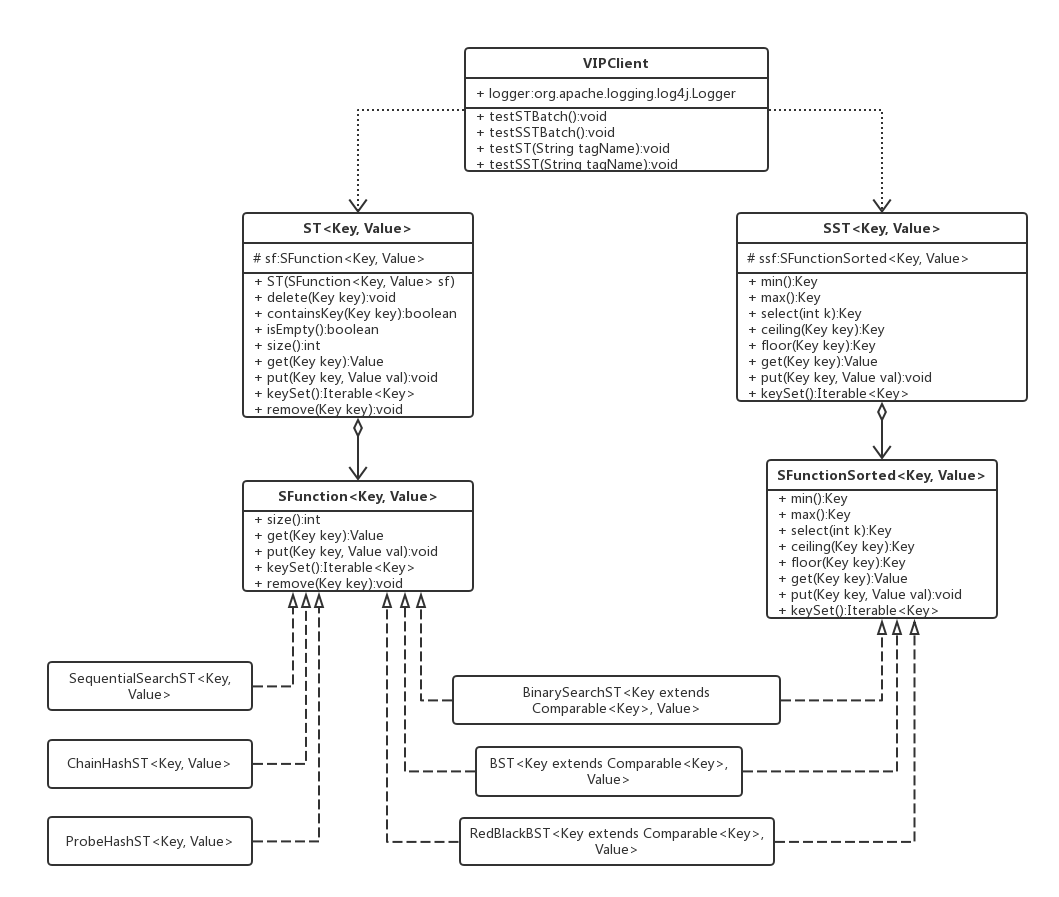
我们这个工程中使用到了很多设计模式,考虑到了不少设计原则,这一篇又回到了设计模式的学习路线,那么可以勉强使用这个工程来分析一下组合模式。
组合模式:将对象组合成树形结构以表示“部分-整体”的层次结构。
分角色
如果要使用组合模式,首先要将你的系统区分出几个角色:
- 主干
- 叶子结点
- 树枝
这三个角色是什么意思呢?
从上面定义可知,对象之间通过组合关系形成树形结构。那么从这个树形结构中去将这三个角色区分出来并不难。
我们结合算法的工程来举例分析,由于还有其他架构在里面,这里我们只分析ST这一支。
- 主干是ST
- 叶子结点是SequentialSearchST, BinarySearchST, BST, RedBlackBST, ChainHashST, ProbeHashST
- 树枝是SFunction
角色的活
角色区分完毕以后,要给他们安排具体任务,
- 主干就是最终提供给客户端调用的类
- 叶子结点是继承于主干,他是干具体活,实现具体操作的类
- 树枝是用来存储叶子结点,同时也是继承于主干
抛砖
从这里我们可以看出不同,我们的查找算法工程(如上图)是呈现三层结构,
ST -> SFunction -> XXXST
而组合模式的意思是什么?
ST -> SFunction -> XXXST; ST->XXXST
所以,通过查找算法工程的类图,我们抛砖引玉,引出了真正的组合模式,能够看出来么,组合模式的核心思想是在三层基础上,仍旧保持主干和叶子结点的关联关系,这有什么好处呢?
组合模式解耦了客户程序与复杂元素内部结构,从而使客户程序可以像处理简单元素一样来处理复杂元素。
换句话说,就是客户端操作的主干类,这个主干类可以注入叶子结点和树枝,叶子结点就是简单元素,树枝因为它本身包含很多叶子结点,因此它是复杂元素。这样以来,客户端实际在操作叶子结点和树枝时,所付出的“辛苦”是相同的。这里再用算法工程的类图来表示就不合适了。
引玉
业界常见的例子是操作系统里面的文件管理器,我们也来画一个。
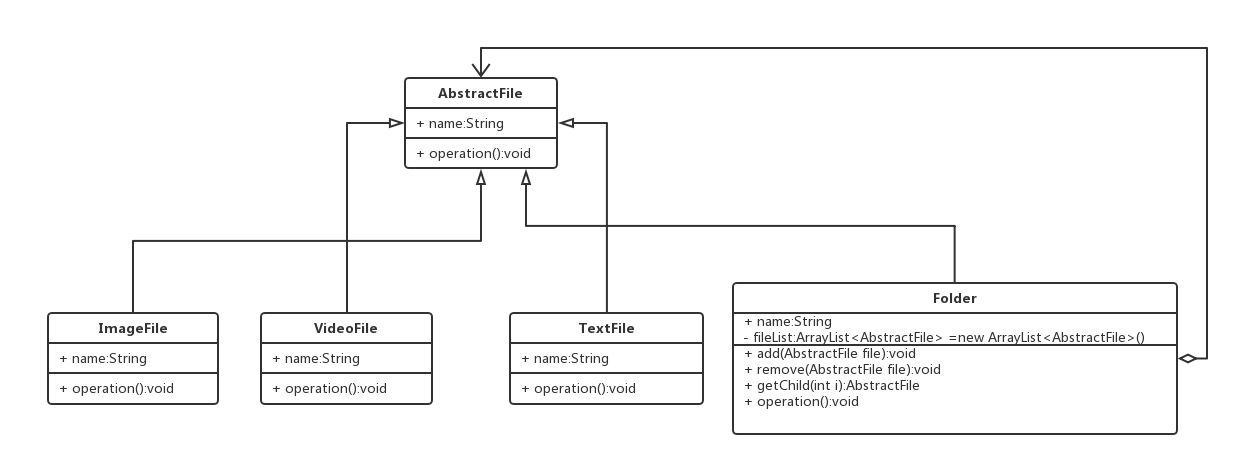
这是组合模式最终的版本的样子,下面来解释一下上面的类图。
-
AbstractFile
主干类,也叫Component,提供给客户端直接调用的对象,它是目前所有对象的基类,定义了operation方法。
-
XXXFile
叶子结点,具体文件的具体类型,继承了AbstractFile类并实现了不同类型文件的具体的operation方法内容,同时它也是Folder对象的一份子,与Folder对象是多对一的关系。
-
Folder
组合模式的核心对象。首先它也继承了AbstractFile类,该有的继承方法和属性都与XXXFile一样,然而他的不同之处在于它有一个成员属性是一个存储基类的列表,相应地,它还拥有着对这个列表的增删改查的方法用来堵这个列表进行调整。最后,与XXXFile实现的operation方法的内容不同的是,Folder实现的operation方法是遍历当前列表并依次调用他们内部具体的operation方法。
组合模式的英文全称为Composite Pattern,而Folder所代表的对象即上面说的树枝,英文也被称为Composite。
组合模式总结
组合模式理解起来非常简单,也很巧妙,但是要注意在客户端要调整Composite里的列表时,要直接调用Composite对象的方法,而不是统一只有一个Component对象暴露在客户端。这一点确实有损面向对象的封装性,但是却避免了将这些列表操作方法放入Component类中,让叶子结点也去实现这些跟他们毫无关系的方法,并且在运行时一旦有程序调用了叶子结点的这些方法会引发错乱,相比于此,在客户端暴露出Composite对象是代价比较小的方式。
- 适用场景
在具有整体和部分的层次结构中,希望通过一种方式忽略整体与部分的差异,客户端可以一致地对待它们,那就选择使用组合模式吧。