正则表达式RE
正则表达式概览
正则表达式(regular expression, RE)是一种字符模式,用于在查找过程中匹配指定的字符。
在大多数程序里,正则表达式都被置于两个正斜杠之间;例如/l[oO]ve/就是由正斜杠界定的正则表达式,它将配被查找的行中任何位置出现的相同模式。在正则表达式中, 元字符是最重要的概念。
匹配数字: [1]+$ ---> 123 456 5y7
匹配 Mail: [a-z0-9_]+@[a-z0-9]+.[a-z]+ ---> yangsheng131420@126.com
匹配 IP: [0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3} 或 [[:digit:]]{1,3}.[[:digit:]]{1,3}.[[:digit:]]{1,3}.[[:digit:]]{1,3}
--->
[root@hadoop04 shell_function]# egrep '[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}' /etc/sysconfig/network-scripts/ifcfg-eth0
IPADDR=172.22.34.20
GATEWAY=172.22.34.1
NETMASK=255.255.255.0
DNS1=172.22.23.166
[root@hadoop04 shell_function]# egrep '[[:digit:]]{1,3}.[[:digit:]]{1,3}.[[:digit:]]{1,3}.[[:digit:]]{1,3}' /etc/sysconfig/network-scripts/ifcfg-eth0
IPADDR=172.22.34.20
GATEWAY=172.22.34.1
NETMASK=255.255.255.0
DNS1=172.22.23.166
元字符
定义:元字符是这样一类字符,它们表达的是不同于字面本身的含义
shell 元字符(也称为通配符) 由 shell 来解析,如 rm -rf *.pdf,元字符 * Shell 将其解析为任意多个字符
正则表达式元字符 由各种执行模式匹配操作的程序来解析,比如 vi、grep、sed、awk、python
正则表达式元字符
基本正则表达式元字符
| 元字符 | 功能 | 备注 |
|---|---|---|
| ^ | 行首定位符 | 锚定行首,此字符后面的任意内容必须出现在行首 |
| $ | 行尾定位符 | 锚定行尾,此字符前面的任意内容必须出现在行尾 |
| . | 匹配任意单个字符 | |
| * | 匹配前导符 0 到多次 | 匹配其前面的字符任意次,可以是0次,也可以是多次 |
| .* | 匹配任意长度的任意字符 | |
| [] | 匹配指定范围内的任意单个字符 | 指定范围内的【一个】字符 |
| [ - ] | 匹配指定范围内的一个字符 | |
| [^] | 匹配指定范围外的任意单个字符 | 匹配不在[]内的字符 |
| 用来转义元字符 | ||
| < | 词首定位符 | 锚定词首,其后面的任意字符必须作为单词首部出现 |
| > | 词尾定位符 | 锚定词尾,其前面的任意字符必须作为单词的尾部出现 |
| (..) | 匹配稍后使用的字符的标签 | |
| x{m} | 字符 x 重复出现 m 次 | |
| x{m,} | 字符 x 重复出现 m 次以上 | |
| x{m,n} | 字符 x 重复出现 m 到 n 次 |
^ 行首定位符
# 匹配以root开头的内容
[root@hadoop04 ~]# grep "^root" /etc/passwd
root:x:0:0:root:/root:/bin/bash

$ 行尾定位符
# 匹配以bash结尾的内容
[root@hadoop04 ~]# grep "bash$" /etc/passwd
root:x:0:0:root:/root:/bin/bash
sysadmin:x:1000:1000::/home/sysadmin:/bin/bash
alice:x:1001:1001::/home/alice:/bin/bash

. 匹配单个字符
# 匹配带有r和t、中间为任意字符的三字符内容
[root@hadoop04 ~]# grep "r.t" /etc/passwd
operator:x:11:0:operator:/root:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin

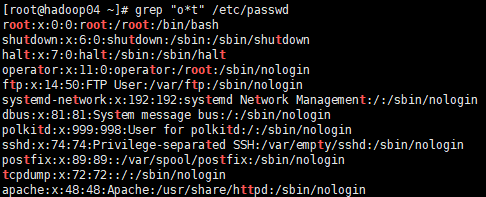
* 匹配前导符 0 到多次
# 匹配o出现0到多次、结尾是t的内容
[root@hadoop04 ~]# grep "o*t" /etc/passwd
root:x:0:0:root:/root:/bin/bash
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
operator:x:11:0:operator:/root:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
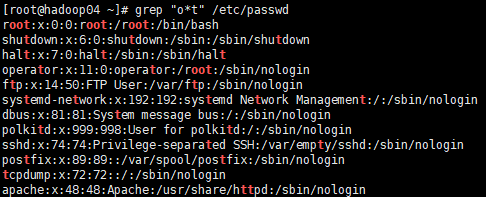
.* 任意多个字符
# 匹配以o开始、以t结尾、中间可以有任意多个字符的内容
[root@hadoop04 ~]# grep "o.*t" /etc/passwd
root:x:0:0:root:/root:/bin/bash
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
operator:x:11:0:operator:/root:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
[] 匹配指定范围内的一个字符
# 匹配root或者Root
[root@hadoop04 ~]# grep "[rR]oot" /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin

转义元字符
元字符具有特殊含义,如果需要匹配元字符的原本字符,就需要使用 进行转义
比如
love. ==> 表示love后面还有一个字符
love. ==> 表示love. 这个字符串
< 词首定位符
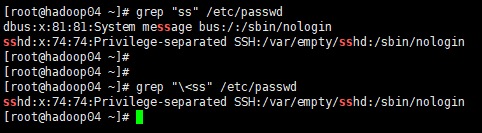
# 匹配含有ss的内容,不管ss出现在什么位置
[root@hadoop04 ~]# grep "ss" /etc/passwd
dbus:x:81:81:System message bus:/:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
# 匹配ss作为单词首部出现的内容
[root@hadoop04 ~]# grep "<ss" /etc/passwd
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
> 词尾定位符
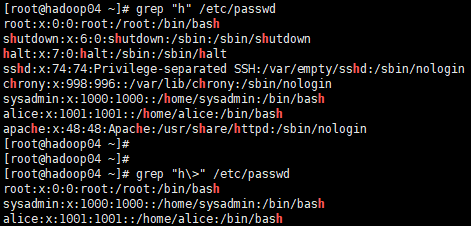
# 匹配含有h的内容,不管h出现在什么位置
[root@hadoop04 ~]# grep "h" /etc/passwd
root:x:0:0:root:/root:/bin/bash
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
sysadmin:x:1000:1000::/home/sysadmin:/bin/bash
alice:x:1001:1001::/home/alice:/bin/bash
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
# 匹配h作为单词结尾出现的内容
[root@hadoop04 ~]# grep "h>" /etc/passwd
root:x:0:0:root:/root:/bin/bash
sysadmin:x:1000:1000::/home/sysadmin:/bin/bash
alice:x:1001:1001::/home/alice:/bin/bash
(..) 1 2 标签匹配字符
(..) 匹配稍后使用的字符的标签
示例说明
==> 将网络配置文件中的IPADDR修改为172.22.34.100
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
NAME=eth0
DEVICE=eth0
ONBOOT=yes
IPADDR=172.22.34.100
GATEWAY=172.22.34.1
NETMASK=255.255.255.0
DNS1=172.22.23.166
传统替换方式 ==> :%s/172.22.34.20/172.22.34.100/
正则匹配替换 ==> :%s/(172.22.34).20/1.100/
说明:(172.22.34) 括号包括了172.22.34,后面 1 表示引用这部分内容,即172.22.34
也就是说,1 表示 引用第一个左括号以及与之对应的右括号所包括的所有内容
除了1 还可以有 2 、3 ,具体意义可以类推,1 表示 引用第二个左括号以及与之对应的右括号所包括的所有内容;
比如 :% s/(172.)(16.)(130.)1/1235/
1表示引用 172.
2表示引用 16.
3表示引用 130.
{m} 重复出现 m 次
x{m} 表示字符 x重复出现 m 次
{m,} 重复出现 m 次以上
x{m,} 字符 x重复出现 m 次以上
{m,n} 重复出现 m 到 n 次
x{m,n} 字符 x 重复 m 到 n 次
[2] 和[^]的区别
^[^0-9a-z]
==>第一个^的作用是:以...开头
==>第二个^的作用是:取反,匹配不在指定组内的字符
==>综合起来,[^0-9a-z]匹配不是数字也不是小写字母,^[^0-9a-z]开头不是数字也不是小写字母
扩展正则表达式元字符
+ 匹配一个或多个前导字符
[root@hadoop04 ~]# egrep "s+" /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
# 匹配到两个s,其他行都只匹配到一个s
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
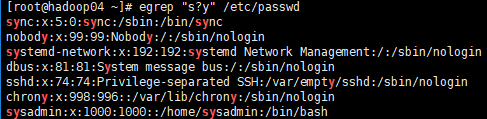
? 匹配零个或一个前导字符
# 匹配s出现0次或者1次、以y结尾的内容
[root@hadoop04 ~]# egrep "s?y" /etc/passwd
sync:x:5:0:sync:/sbin:/bin/sync
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
sysadmin:x:1000:1000::/home/sysadmin:/bin/bash
| 或者
# a|b 匹配 ==> a 或 b
# love|hate ==> 匹配 love 或 hate
# 匹配出服务端口为22或者514
[root@hadoop04 ~]# ss -an | egrep ':514|:22>'
udp UNCONN 0 0 *:514 *:*
udp UNCONN 0 0 :::514 :::*
tcp LISTEN 0 128 *:22 *:*
tcp LISTEN 0 25 *:514 *:*
tcp ESTAB 0 52 172.22.34.20:22 172.22.11.1:12315
tcp LISTEN 0 128 :::22 :::*
tcp LISTEN 0 25 :::514 :::*
() 组字符
# loveable|rs ==> 表示loveable或者rs
# love(able|rs) ==> 表示 loveable或者lovers
(..)(..)12 标签匹配字符
与 (..) 1 2 一样,只不过 (..)(..)12 只适用于支持扩展正则表达式元字符的工具中
{m} 重复 m 次
x{m} 字符 x 重复 m 次
{m,} 重复至少 m 次
x{m,} 字符 x 重复至少 m 次
{m,n} 重复 m 到 n 次
x{m,n} 字符 x 重复 m 到 n 次
正则匹配示例: vim
/love/ # 匹配包含love的内容
/^love/ # 匹配love开头的内容
/love$/ # 匹配love结尾的内容
/l.ve/ # 匹配l和ve之间包含一个任意字符的内容
/lo*ve/ # 匹配l和ve之间有0-多个o的内容
/[Ll]ove/ # 匹配包含Love或者love的内容
/love[a-z]/ # 匹配love后面跟上小写字母的内容
/love[^a-zA-Z0-9]/ # 匹配love后面跟上特殊字符的内容
/.*/ # 匹配整行
/^$/ # 匹配空行
/^[A-Z]..$/ # 匹配大写字母开头,后面跟上两个任意字符结尾的内容
/^[A-Z][a-z ]*3[0-5]/ # 匹配大写字母开头,后面跟上0-多个小写字母,跟一个数字3,再跟上0-5的一个数字的内容
/[a-z]*./ # 匹配0-多个小写字母,后面跟上.的内容
/^ *[A-Z][a-z][a-z]$/ # 匹配0-多个空格开头,后面跟一个大小字母,两个小写字母结尾的内容
/^[A-Za-z]*[^,][A-Za-z]*$/ # 匹配0-多个英文字母开头,后面跟上^或者逗号,以0-多个英文字母结尾的内容
/<fourth>/ # 匹配包含单词fourth的内容
/<f.*th>/ # 匹配包含单词:以f开头,th结尾,f和th之间任意长度任意字符的内容
/5{2}2{3}./ # 匹配5出现两次,2出现3次,后面跟上.的内容
# 空行
/^$/ # 只包含换行符空行
/^[ ]*$/ # 包含0-多个空格或者tab的空行
# 注释行
/^#/ # 以#开始的注释行
/^[ ]*#/ # 以0-多个空格或者tab开始,后面跟上#的注释行
:1,$ s/([Oo]ccur)ence/1rence/ # 将occurence或Occurence替换成occurrence或Occurrence
:1,$ s/(square) and (fair)/2 and 1/ # 将"square and fair"替换成"fair and square"