题外话:
前面学了那么多,相信你已经对python很了解了,对爬虫也很有见解了,然后本来的计划是这样的:(请忽略编号和日期,这个是不定数,我在更博会随时改的)
上面截图的是我的草稿
然后当我开始写博文的时候,我发现讲解PhantomJS的话,会涉及到JS代码,而相信跟着我的学习路线从小白上来的,应该都还没学过JS吧,说到JS,那么和Phantom很像的一个模块casperjs,也要跟着提点下,那么还要从JS开始讲解
然后说到PyQuery,其又几乎和JQuery差不多,又要提下JQuery
接着爬虫框架pyspider只支持32位操作系统,我的电脑现在是64位的系统,真要讲解的话,又得重装系统或者在虚拟机下操作
还有个最大的问题,爬虫篇确实延伸得有点多了,这路线走下来,感觉爬虫篇都占了大半了,所以我打算早点结束了,并且我现在也在学习阶段,时间不太多,更博时间也少了。
真不是我懒或者不愿意和大家分享,要把以上的东西说明白,确实需要花些时间,而渐渐的优点偏离我的初衷和本板块的主线。
所以我决定直接讲解爬虫框架Scrapy,其他的暂时不讲解了,以后有时间再讲解了,如果你们确实对爬虫这方面感兴趣(如果你想从事爬虫工程师的工作以上的真需要掌握下),可以网上找资料或者去这里看一位大神的文章:传送门
总之,那几个模块或者框架暂时不更了,后期有时间再更,目前暂时以Scrapy框架作为爬虫篇的收尾吧,后面开始python全栈开发和项目实战了
Scrapy框架
1.简介
1)什么是框架:
- 提供形状或强度的结构系统(如屋架)
- 比喻事物的组织、结构
在IT圈里,框架指为解决一个开放性问题而设计的具有一定约束性的支撑结构。在此结构上可以根据具体问题扩展、安插更多的组成部分,从而更迅速和方便地构建完整的解决问题的方案
通俗的理解,框架就是一套体系,基本整合某一方面的大部分功能,使用它一个就够了,不需要再用其他的多个程序和软件来组合运行处理问题。但是框架也不是万能的,只能完成大部分工作
2)Scrapy框架:
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的web应用框架。它为爬虫提供更灵活更全面的工具和用法,使爬虫工作变得方便,当使用它时,已经默认为你设置好大部分准备工作。
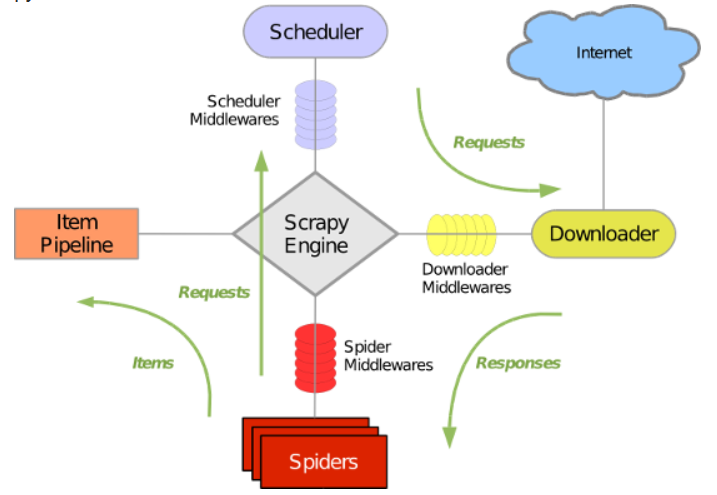
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下:
(一张老掉牙的图片)
Scrapy主要包括了以下组件:
- 引擎(Scrapy):用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler):用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader):用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders):爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares):位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares):介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares):介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
2.安装/配置
注意:
1.python3目前还不能完美支持Scrapy(下面都是在python2上进行)
2.windows平台需要依赖pywin32,请根据自己系统32/64位选择下载安装,安装pywin32链接(你直接点这个链接,浏览器就会开始下载了,已经给你们选好下载包,下载完成双击,一路下一步就行)
使用pip install scrapy 安装:
安装好后,在cmd下运行测试是否安装成功:
至此,Scrapy框架已经安装完成,下面就开始使用了
3.简单使用
1)创建项目
在cmd下,进入你希望的路径,使用命令:scrapy startproject (项目名称) 创建项目
然后scrapy会自动创建一些东西:
自动创建文件夹:
可以用pycharm一目了然:
文件含义:
- scrapy.cfg:项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py:设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines:数据处理行为,如:一般结构化的数据持久化
- settings.py:配置文件,如:递归的层数、并发数,延迟下载等
- spiders:爬虫目录,如:创建文件,编写爬虫规则(爬虫程序就放在此文件夹下 )
2)编写代码
注意:为了创建一个Spider,您必须继承scrapy.spiders.Spider类(后面有详解,姑且这么认定就行)
在spiders目录中新建 sc_test.py 文件
import scrapy
class bdspider(scrapy.spiders.Spider):
name = 'baidu'
allow_domains = ['baidu.com']
start_urls = [
'http://www.baidu.com',
'http://news.baidu.com',
'http://zhidao.baidu.com'
]
def parse(self,response):
filename = response.url.split('/')[-2]
f = open('filename','wb')
f.write(response.body)
f.close()
在爬虫项目的根目录下,也就是你刚才创建的项目文件夹下,执行爬虫程序命令:scrapy crawl name(此name即为刚才自定义里的name,比如我上面代码里的‘baidu')
scrapy 就是框架名嘛,crawl就是爬行的意思,这条命令就是开始爬虫程序
运行结果:
G:programmePythonpython projectscrapytest>scrapy crawl baidu
2017-12-12 13:56:13 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: scrapyte
st)
2017-12-12 13:56:13 [scrapy.utils.log] INFO: Overridden settings: {'NEWSPIDER_MO
DULE': 'scrapytest.spiders', 'SPIDER_MODULES': ['scrapytest.spiders'], 'ROBOTSTX
T_OBEY': True, 'BOT_NAME': 'scrapytest'}
2017-12-12 13:56:13 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.logstats.LogStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2017-12-12 13:56:13 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-12-12 13:56:14 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-12-12 13:56:14 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-12-12 13:56:14 [scrapy.core.engine] INFO: Spider opened
2017-12-12 13:56:14 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pag
es/min), scraped 0 items (at 0 items/min)
2017-12-12 13:56:14 [scrapy.extensions.telnet] DEBUG: Telnet console listening o
n 127.0.0.1:6023
2017-12-12 13:56:14 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.ba
idu.com/robots.txt> (referer: None)
2017-12-12 13:56:14 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by
robots.txt: <GET http://www.baidu.com>
2017-12-12 13:56:14 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://news.b
aidu.com/robots.txt> (referer: None)
2017-12-12 13:56:14 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by
robots.txt: <GET http://news.baidu.com>
2017-12-12 13:56:14 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://zhidao
.baidu.com/robots.txt> (referer: None)
2017-12-12 13:56:14 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (
301) to <GET https://zhidao.baidu.com/> from <GET http://zhidao.baidu.com>
2017-12-12 13:56:15 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://zhida
o.baidu.com/> (referer: None)
2017-12-12 13:56:15 [scrapy.core.engine] INFO: Closing spider (finished)
2017-12-12 13:56:15 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/exception_count': 2,
'downloader/exception_type_count/scrapy.exceptions.IgnoreRequest': 2,
'downloader/request_bytes': 1205,
'downloader/request_count': 5,
'downloader/request_method_count/GET': 5,
'downloader/response_bytes': 57574,
'downloader/response_count': 5,
'downloader/response_status_count/200': 4,
'downloader/response_status_count/301': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 12, 12, 5, 56, 15, 360000),
'log_count/DEBUG': 8,
'log_count/INFO': 7,
'response_received_count': 4,
'scheduler/dequeued': 4,
'scheduler/dequeued/memory': 4,
'scheduler/enqueued': 4,
'scheduler/enqueued/memory': 4,
'start_time': datetime.datetime(2017, 12, 12, 5, 56, 14, 19000)}
2017-12-12 13:56:15 [scrapy.core.engine] INFO: Spider closed (finished)
(时间暂且忽略,因为我是为了和后面的使用代码运行作对比而补充的,本来不想给出来的,因为占空间,也没多大的作用)
(只截取了部分,上面显示的都是日志 )
你可以不让它显示日志:使用命令:scrapy crawl name --nolog:

再看这部分代码:
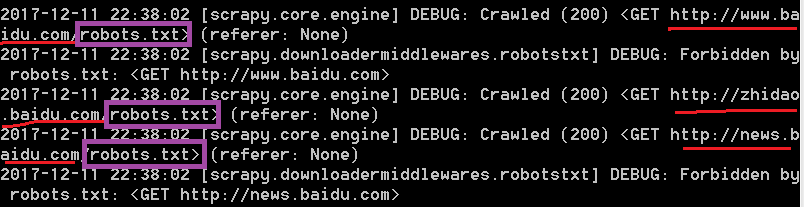
这里面的请求url正好就是之前定义的start_urls里的url
其中我圈出来的robots.txt,还有forbidden什么什么的,这些是什么意思,robot就是机器人的意思,robots.txt就是一个协议,大部分网站都会有的就是防爬虫程序,大概意思就是请求被robots.txt协议拒绝。
可以直接访问一下这个文件:

(图片只截取了部分)
里面的User_agent就是请求头部信息,只要有这些信息就直接disallow(拒绝的意思)。
当然你要知道scrapy是个框架啊,这种简单的防爬机制怎么能难得住scrapy,在setting.py文件里可以修改的,后面再做详解
先来解释下,当我运行这条命令scray crawl name 时,都发生了什么:
Scrapy给Spider的start_urls属性中的每个URL创建了一个spider.request对象,并将parse方法作为回调函数(callback)赋值给了request。Request对象经过调度,执行生成scrapy.http.response对象并送回给spider的parse方法。
所以,你可能看着代码有点云里雾里,你只要修改部分就行,其他的scrapy框架为你自动设置,这就是scrapy的特性,这就是框架的好处
相信有朋友觉得在终端下手动执行命令来运行scrapy爬虫有点麻烦了,是的,python这么高端的,怎么会用这么低级的运行方式呢?
方法有两个:
1.在pycharm里可以配置(详细的就自己查了,不难)
2.写一个运行文件run.py
此run.py必须放在创建项目的根目录下,比如我这里的根目录就是scrapytest
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from spiders.sc_test import bdspider
settings =get_project_settings()
process = CrawlerProcess(settings=settings)
process.crawl(bdspider)
process.start()
运行结果:
2017-12-12 13:55:06 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: scrapytest)
2017-12-12 13:55:06 [scrapy.utils.log] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'scrapytest.spiders', 'SPIDER_MODULES': ['scrapytest.spiders'], 'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'scrapytest'}
2017-12-12 13:55:06 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.logstats.LogStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2017-12-12 13:55:07 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-12-12 13:55:07 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-12-12 13:55:07 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-12-12 13:55:07 [scrapy.core.engine] INFO: Spider opened
2017-12-12 13:55:07 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-12-12 13:55:07 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-12-12 13:55:08 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.baidu.com/robots.txt> (referer: None)
2017-12-12 13:55:08 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET http://www.baidu.com>
2017-12-12 13:55:08 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://news.baidu.com/robots.txt> (referer: None)
2017-12-12 13:55:08 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET http://news.baidu.com>
2017-12-12 13:55:08 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://zhidao.baidu.com/robots.txt> (referer: None)
2017-12-12 13:55:08 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://zhidao.baidu.com/> from <GET http://zhidao.baidu.com>
2017-12-12 13:55:09 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://zhidao.baidu.com/> (referer: None)
2017-12-12 13:55:09 [scrapy.core.engine] INFO: Closing spider (finished)
2017-12-12 13:55:09 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/exception_count': 2,
'downloader/exception_type_count/scrapy.exceptions.IgnoreRequest': 2,
'downloader/request_bytes': 1205,
'downloader/request_count': 5,
'downloader/request_method_count/GET': 5,
'downloader/response_bytes': 57227,
'downloader/response_count': 5,
'downloader/response_status_count/200': 4,
'downloader/response_status_count/301': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 12, 12, 5, 55, 9, 578000),
'log_count/DEBUG': 8,
'log_count/INFO': 7,
'response_received_count': 4,
'scheduler/dequeued': 4,
'scheduler/dequeued/memory': 4,
'scheduler/enqueued': 4,
'scheduler/enqueued/memory': 4,
'start_time': datetime.datetime(2017, 12, 12, 5, 55, 7, 921000)}
2017-12-12 13:55:09 [scrapy.core.engine] INFO: Spider closed (finished)
对比上面在终端下的运行结果是一样的
3)定义和设置item (可选步骤,没有这一步一样可以运行,不过稍微大型点的爬虫项目建议加上这一步)
item是保存爬取到的数据的容器,使用方法和python字典类似, 它还提供了额外保护机制来避免拼写错误导致的未定义字段错误。
首先要根据需求从baidu.com获取到的数据对item进行建模,我们需要从百度中获取名字,url,以及网站的描述。 对此,在item中定义相应的字段。编辑scrapytest目录中的item.py文件
import scrapy
class scrapytestitem(scrapy.Item):
title = scrapy.Field() #标题
link = scrapy.Field() #url
desc = scrapy.Field() #描述
scrapy.Item的用法与python中的字典用法基本一样,只是做了一些安全限制,属性定义使用Field,这里只是进行了声明,而不是真正的属性,使用的时候通过键值对操作,但不支持属性访问,意味着所有的属性赋值都得用字符串
利用上面定义的title,link,desc则可以对parse方法进行修改,得到需要得到的值:(下面的是伪代码,具体代码根据具体情况来)
import scrapy
class bdspider(scrapy.spiders.Spider):
name = 'baidu'
allow_domains = ['baidu.com']
start_urls = [
'http://www.baidu.com',
'http://news.baidu.com',
'http://zhidao.baidu.com'
]
def parse(self,response):
for i in response.xpath('//div/ul') #此处的html标签只是一个假设
bd_item = ScrapytestItem()
bd_item['title'] = i.xpath('li/text()').extract()
bd_item['link'] = i.xpath('li/text()').extract()
bd_item['desc'] = i.xpath('li/text()').extract()
4.scrapy类
前面已经对scrapy有个大概了解了,那么开始详细的scrapy类讲解了
1)scrapy.spiders.spider类(即上面创建爬虫代码继承的类)
其常用属性/方法
属性:
- name:即爬虫的名字,
它是唯一的,用于区别不同的Spider,不可以为不同的Spider设定相同的名字 - start_urls:
包含Spider在启动时进行爬取的url列表 - parse()
是spider的一个方法。 被调用时,每个初始URL完成下载后生成的response对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的request对象 - custom_settings:自定义配置,覆盖settings.py
中的默认配置(一般很少对这个属性进行修改)
方法
- start_requets():启动爬虫的时候调用,默认是调用make_requests_from_url方法爬取start_urls的链接,可以在这个方法里面定制,如果重写了该方法,start_urls默认将不会被使用,可以在这个方法里面定制一些自定义的url,如登录,从数据库读取url等,本方法返回Request对象
- make_requests_from_url():默认由start_requets调用,可以配置Request对象,返回Request对象
- parse():response到达spider的时候默认调用,如果在Request对象配置了callback函数,则不会调用,parse方法可以迭代返回Item或者Request对象,如果返回Request对象,则会进行增量爬取
2)Request和respone对象
每个请求都是一个Request对象,Request对象定义了请求的相关信息(url, method, headers, body, cookie, priority)和回调的相关信息(meta, callback, dont_filter, errback),通常由spider迭代返回。其中meta相当于附加变量,可以在请求完成后通过respone.meta访问
请求完成后,会通过respone对象发送给spider处理,常用属性有(url, status, headers, body, request, meta)
详细介绍参考官网:
- https://doc.scrapy.org/en/latest/topics/request-response.html#request-objects
- https://doc.scrapy.org/en/latest/topics/request-response.html#response-objects
scrapy的类最常见的就这几个
5.提取数据
既然都能爬网站,当然希望从网页里爬取我们需要的数据,而当我们爬取大量的网页,针对某一段我们需要的数据时,如果还是用re或者BeautifulSoup的话,那就完全没必要用scrapy框架了对吧?并且这也很浪费时间,没让人失望,scrapy内部确实支持更简单的查询语法,帮助我们查询需要的数据。
- 查询某个子标签(以a标签为例):/a
- 查询某个子标签下的子标签(以a标签为例)://a
- 查询标签中带有某个class属性的标签://div[@class=’fm′]:即子子孙孙中标签是div且class=‘fm’的标签
- 查询标签中带有某个class=‘fm’并且自定义属性name=‘test’的标签://div[@class=’fm′][@name='test']
- 查询某个标签的文本内容://div/span/text():即查询子子孙孙中div下面的span标签中的文本内容
- 查询某个属性的值(例如查询a标签的href属性)://a/@href
不过这也并不是说scrapy有自己的一套查询语句,Scrapy是使用了一种基于 XPath 和 CSS 表达式机制: Scrapy Selectors
Selector有六个基本的方法:
- 基本的文本操作(这不废话吗)
- dom树形结构操作:BeautifulSoup
- re():根据传入的正则表达式对数据进行提取,返回unicode字符串list列表
- xpath():传入xpath表达式,返回该表达式所对应的所有节点的selector list列表(scrapy默认支持选择器的功能,自带的选择器构建与lxml之上,并对其进行了改进,使用起来更为简洁明了)
- css():传入CSS表达式,返回该表达式所对应的所有节点的selector list列表
- extract():序列化该节点为unicode字符串并返回list(可以和xpath配套使用)
基本的文本操作,正则表达式,以及BeautifulSoup就不废话了,前面都讲过的
1)xpath:
XPpath是标准的XML文档查询语言,可以用于查询XML文档中的节点和内容,其实单独的把它拿出来也可以作爬虫操作的,与re和BeautifulSoup一样的,但因为它用的是xml文档,可能很多人用不惯(我也用不惯),所以感觉上并没有re,BeautifulSoup操作简单
Selector相当于节点,通过xpath去到子节点集合(SelectorList),可以继续搜索,通过extract方法可以取出节点的值,extract方法也可以作用于SelectorList,对于SelectorList可以通过extract_first取出第一个节点的值
A.通过text()取出节点的内容

B.通过@href取出节点属性值
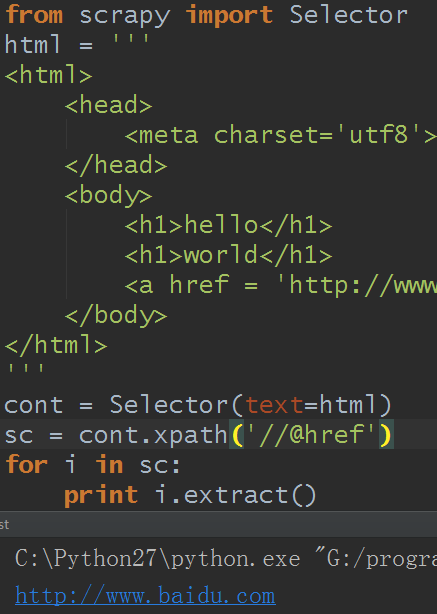
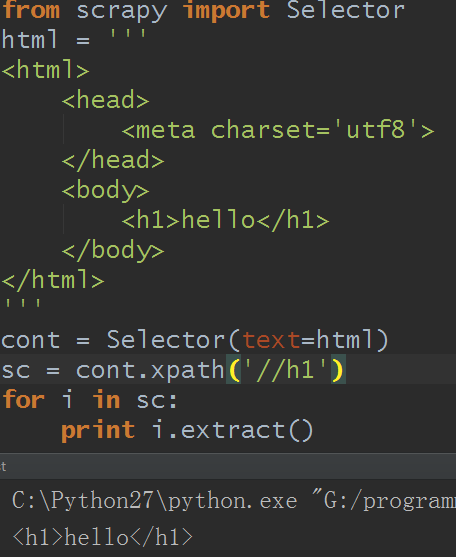
C.直接对节点取值,则是输出节点的字符串
2)css:
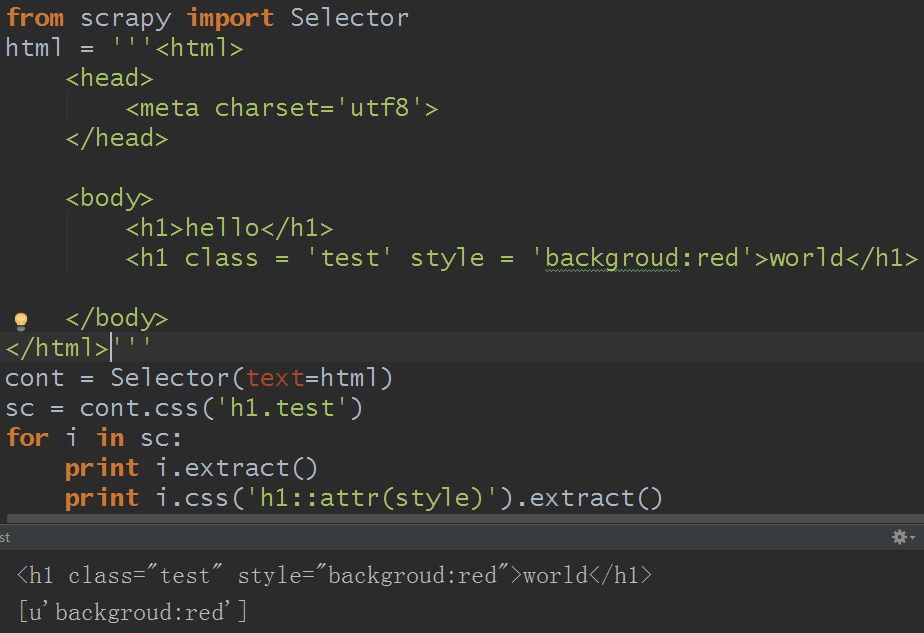
有关css的用法,详细可见:https://www.w3.org/TR/selectors/
爬虫的通常需要在一个网页里面爬去其他的链接,然后一层一层往下爬,scrapy提供了LinkExtractor类用于对网页链接的提取,使用LinkExtractor需要使用CrawlSpider爬虫类中,CrawlSpider与Spider相比主要是多了rules,可以添加一些规则,那么这个Rule其实也是一个对象
6.Rule和LinkExtractor
1)Rule对象参数:
- link_extractor:链接提取规则
- callback:link_extractor提取的链接的请求结果的回调
- cb_kwargs:附加参数,可以在回调函数中获取到
- follow:表示提取的链接请求完成后是否还要应用当前规则(boolean),如果为False则不会对提取出来的网页进行进一步提取,默认为False
- process_links:处理所有的链接的回调,用于处理从response提取的links,通常用于过滤(参数为link列表)
- process_request:链接请求预处理(添加header或cookie等)
2) LinkExtractor对象参数:
- allow:提取符合正则表达式的链接
- deny:拒绝符合正则表达式的链接(优先级高于allow,在开发中,一般都是拒绝优先)
- allow_domains:允许的域名(可以是str或list)
- deny_domains:拒绝的域名(可以是str或list)
- restrict_xpaths:提取满足XPath选择条件的链接(可以是str或list)
- restrict_css:提取满足css选择条件的链接(可以是str或list)
- tags:提取指定标签下的链接,默认从a和area中提取(可以是str或list)
- attrs:提取满足拥有属性的链接,默认为href(类型为list)
- unique:链接是否去重(类型为boolean)
- process_value:值处理函数(优先级大于allow)
注意:如果使用rules规则,请不要覆盖或重写CrawlSpider的parse方法,否则规则会失效,可以使用parse_start_urls方法
同样是有些伪代码的感觉,你们知道大概怎么操作就行了
from scrapy.spider import CrawlSpider,Rule
from scrapy.linkextractor import LinkExtractor
class bdnewspider(CrawlSpider):
name ='bdnew'
allowed_domains = ['baidu.com']
start_urls = ['http://news.baidu.com/ent']
rules = [
Rule(LinkExtractor(allow=(r'http://ent.ifeng.com/a/20171212/$')),callback='parse_item'),
]
def parse_item(self,response):
pass
结果:
G:programmePythonpython projectscrapytest>scrapy crawl bdnew
G:programmePythonpython projectscrapytestscrapytestspidersRuletest.py:7:
ScrapyDeprecationWarning: Module `scrapy.spider` is deprecated, use `scrapy.spid
ers` instead
from scrapy.spider import CrawlSpider,Rule
G:programmePythonpython projectscrapytestscrapytestspidersRuletest.py:8:
ScrapyDeprecationWarning: Module `scrapy.linkextractor` is deprecated, use `scra
py.linkextractors` instead
from scrapy.linkextractor import LinkExtractor
<h1 class="test" style="backgroud:red">world</h1>
[u'backgroud:red']
2017-12-12 15:54:43 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: scrapyte
st)
2017-12-12 15:54:43 [scrapy.utils.log] INFO: Overridden settings: {'NEWSPIDER_MO
DULE': 'scrapytest.spiders', 'SPIDER_MODULES': ['scrapytest.spiders'], 'ROBOTSTX
T_OBEY': True, 'BOT_NAME': 'scrapytest'}
2017-12-12 15:54:43 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.logstats.LogStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2017-12-12 15:54:45 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-12-12 15:54:45 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-12-12 15:54:45 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-12-12 15:54:45 [scrapy.core.engine] INFO: Spider opened
2017-12-12 15:54:45 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pag
es/min), scraped 0 items (at 0 items/min)
2017-12-12 15:54:45 [scrapy.extensions.telnet] DEBUG: Telnet console listening o
n 127.0.0.1:6023
2017-12-12 15:54:45 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://news.b
aidu.com/robots.txt> (referer: None)
2017-12-12 15:54:45 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by
robots.txt: <GET http://news.baidu.com/ent>
2017-12-12 15:54:46 [scrapy.core.engine] INFO: Closing spider (finished)
2017-12-12 15:54:46 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/exception_count': 1,
'downloader/exception_type_count/scrapy.exceptions.IgnoreRequest': 1,
'downloader/request_bytes': 222,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 970,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 12, 12, 7, 54, 46, 67000),
'log_count/DEBUG': 3,
'log_count/INFO': 7,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2017, 12, 12, 7, 54, 45, 240000)}
2017-12-12 15:54:46 [scrapy.core.engine] INFO: Spider closed (finished)
以上的各个机制都有不同的分工,spider负责爬虫的配置,item负责声明结构化数据
7.缓存
scrapy默认已经自带了缓存的功能,我们只需要配置即可,打开settings.py文件:
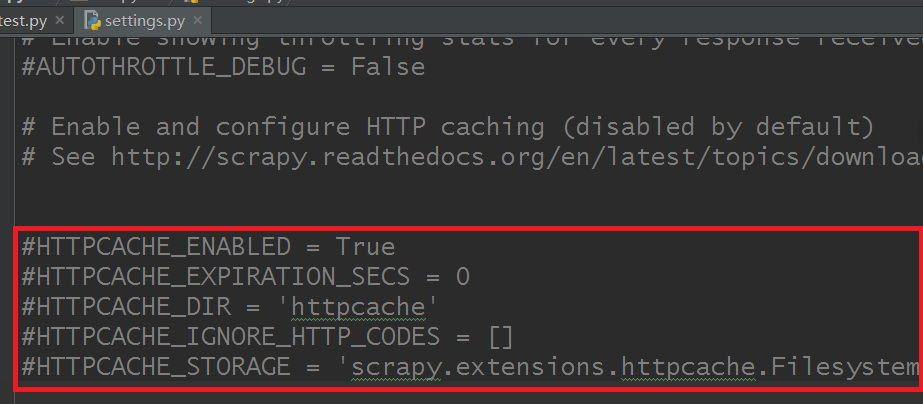
图片标注区域则是缓存设置,分别代码的意思:
# 打开缓存
HTTPCACHE_ENABLED = True
# 设置缓存过期时间(单位:秒)
#HTTPCACHE_EXPIRATION_SECS = 0
# 缓存路径(默认为:.scrapy/httpcache)
HTTPCACHE_DIR = 'httpcache'
# 忽略的状态码
HTTPCACHE_IGNORE_HTTP_CODES = []
# 缓存模式(文件缓存)
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
如果你需要设置就把前面的注释符【#】去掉就可以了
8.多线程
scrapy网络请求是基于Twisted,而Twisted默认支持多线程,相信在你使用命令【pip install scrapy】时,你应该注意到在安装过程中,安装过Twisted组件。
scrapy默认也是通过多线程请求的,并且支持多核CPU的并发,通常只需要配置以下参数即可:
# 默认Item并发数:100
CONCURRENT_ITEMS = 100
# 默认Request并发数:16
CONCURRENT_REQUESTS = 16
# 默认每个域名的并发数:8
CONCURRENT_REQUESTS_PER_DOMAIN = 8
# 每个IP的最大并发数:0表示忽略
CONCURRENT_REQUESTS_PER_IP = 0
这些参数成了默认Item并发数没有(找了很久,确实没找到,我是手动添加的),其他都在settings.py文件里面:
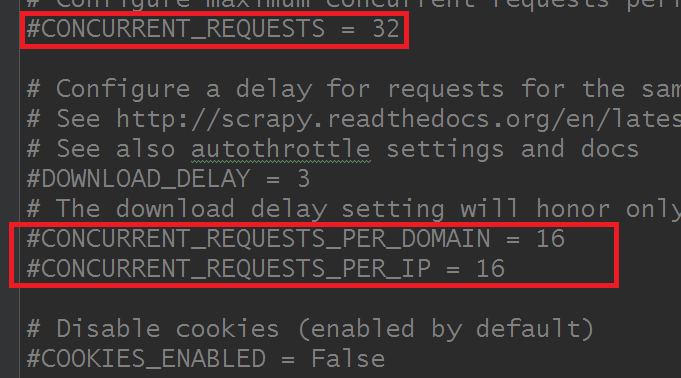
详见说明:官网文档
补充:
9.伪造报文头部
前面的测试里一直被拒绝访问,因为user-agent参数问题,scrapy当然可以设置user-agent参数的,有三个方法可行:
1)在settings.py里设置
settings.py默认的是这样的:
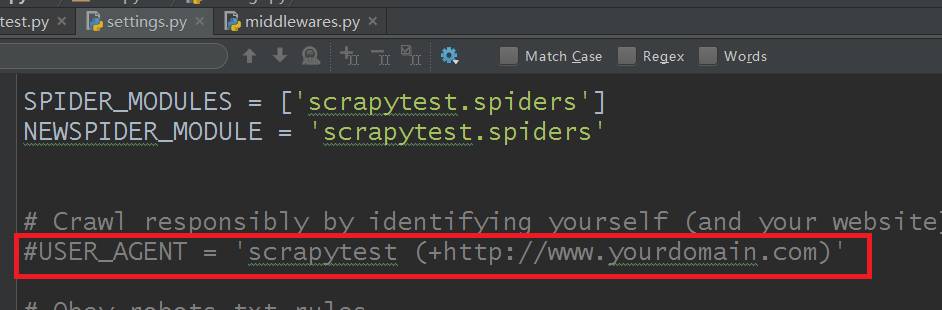
可以这么修改:
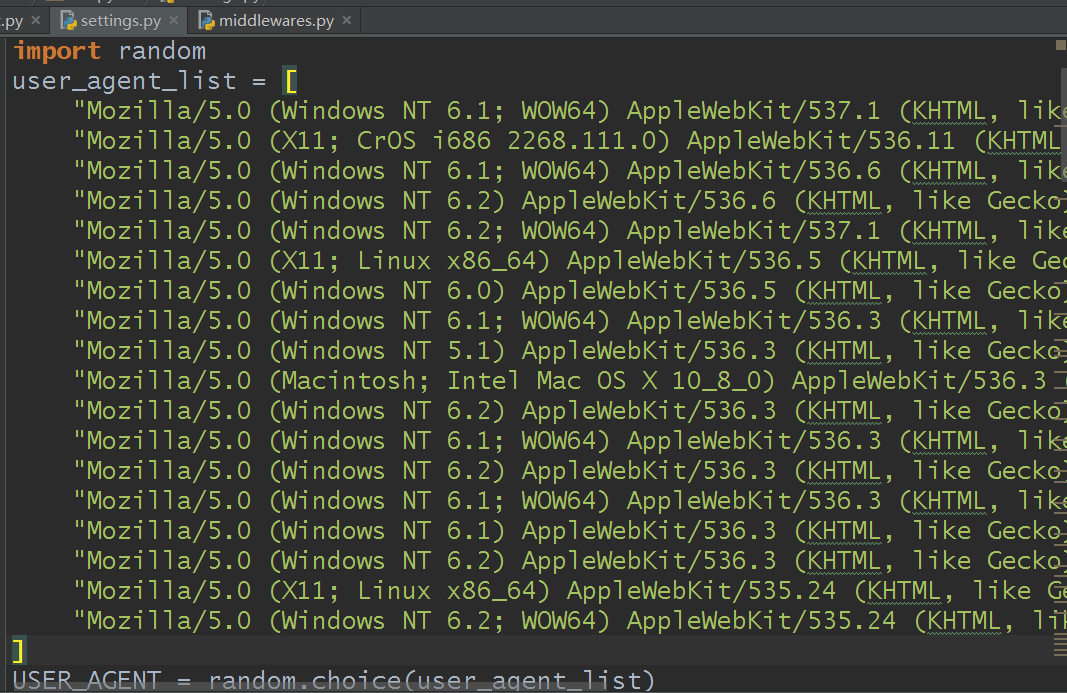
然后,如果你运行代码还是提示forbidden之类的,记得把这个参数由默认的True改为False就行:
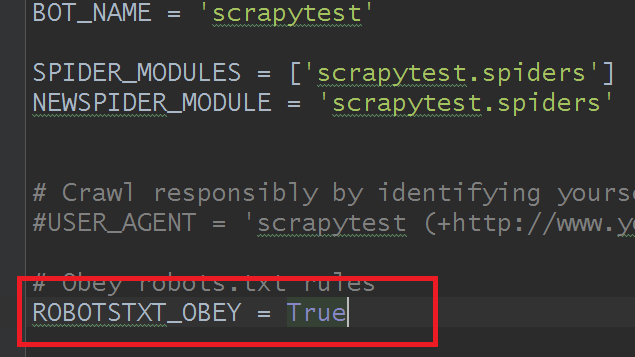
结果:
G:programmePythonpython projectscrapytest>scrapy crawl baidu
G:programmePythonpython projectscrapytestscrapytestspidersRuletest.py:7:
ScrapyDeprecationWarning: Module `scrapy.spider` is deprecated, use `scrapy.spid
ers` instead
from scrapy.spider import CrawlSpider,Rule
G:programmePythonpython projectscrapytestscrapytestspidersRuletest.py:8:
ScrapyDeprecationWarning: Module `scrapy.linkextractor` is deprecated, use `scra
py.linkextractors` instead
from scrapy.linkextractor import LinkExtractor
<h1 class="test" style="backgroud:red">world</h1>
[u'backgroud:red']
2017-12-12 16:33:55 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: scrapyte
st)
2017-12-12 16:33:55 [scrapy.utils.log] INFO: Overridden settings: {'NEWSPIDER_MO
DULE': 'scrapytest.spiders', 'SPIDER_MODULES': ['scrapytest.spiders'], 'USER_AGE
NT': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko)
Chrome/19.0.1055.1 Safari/535.24', 'BOT_NAME': 'scrapytest'}
2017-12-12 16:33:55 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.logstats.LogStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2017-12-12 16:33:56 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-12-12 16:33:56 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-12-12 16:33:56 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-12-12 16:33:56 [scrapy.core.engine] INFO: Spider opened
2017-12-12 16:33:56 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pag
es/min), scraped 0 items (at 0 items/min)
2017-12-12 16:33:56 [scrapy.extensions.telnet] DEBUG: Telnet console listening o
n 127.0.0.1:6023
2017-12-12 16:33:56 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (
302) to <GET https://www.baidu.com/> from <GET http://www.baidu.com>
2017-12-12 16:33:56 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (
301) to <GET https://zhidao.baidu.com/> from <GET http://zhidao.baidu.com>
2017-12-12 16:33:56 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://news.b
aidu.com> (referer: None)
2017-12-12 16:33:56 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.b
aidu.com/> (referer: None)
2017-12-12 16:33:57 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://zhida
o.baidu.com/> (referer: None)
2017-12-12 16:33:57 [scrapy.core.engine] INFO: Closing spider (finished)
2017-12-12 16:33:57 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 1696,
'downloader/request_count': 5,
'downloader/request_method_count/GET': 5,
'downloader/response_bytes': 112116,
'downloader/response_count': 5,
'downloader/response_status_count/200': 3,
'downloader/response_status_count/301': 1,
'downloader/response_status_count/302': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 12, 12, 8, 33, 57, 411000),
'log_count/DEBUG': 6,
'log_count/INFO': 7,
'response_received_count': 3,
'scheduler/dequeued': 5,
'scheduler/dequeued/memory': 5,
'scheduler/enqueued': 5,
'scheduler/enqueued/memory': 5,
'start_time': datetime.datetime(2017, 12, 12, 8, 33, 56, 371000)}
2017-12-12 16:33:57 [scrapy.core.engine] INFO: Spider closed (finished)
结果里已经没有forbidden和robots.txt之类的字眼了
2)在middlewares.py文件中设置User-Agent(也称通过改写中间件来设置User-Agent)
在middleware.py追加编写一个类,代码大概如下:
import random
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
class UAMiddleware(UserAgentMiddleware):
def __init__(self, user_agent=''):
self.user_agent = user_agent
def process_request(self, request, spider):
if random.choice(self.user_agent_list):
request.headers.setdefault('User-Agent', ua)
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
然后在setting.py文件里,把这段代码:
#DOWNLOADER_MIDDLEWARES = {
# 'scrapytest.middlewares.MyCustomDownloaderMiddleware': 543,
#}
改成这样就行:
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':None,
'scrapytest.middlewares.UAMiddleware':400, #scrapytest是创建的项目名,UAMiddleware是刚才在midddleware.py文件下自定义的一个类
}
结果和前面直接修改setting.py的相同,就不贴出来了
如果结果还是有forbidden之类的,同样的把前面那个True改为False就行
3)在scrapy主程序里直接加上User-Agent
详细操作略过,和以前的用法一样的
4)使用第三方user-agent库(fake-useragent)
使用pip安装好第三方库后,在setting.py文件里添加这么一段代码就行:
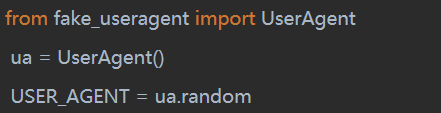
同样的,结果也相同,不再展示
其他的还有设置管道的Pipeline,还有Middleware暂时略过了,看项目来使用,一般我个人都没有用到,如果你感兴趣可以自己查查怎么用
以上所有的,如果你觉得还不够,可以看看scrapy的官方文档里的中文教程:传送门