前言
本次针对某个翻译平台的js逆向,同时并不存在恶意,只是本着学习研究为主,同时,在分析期间并未高频次测试导致该平台服务器不可用
观察
首先直接体验下:
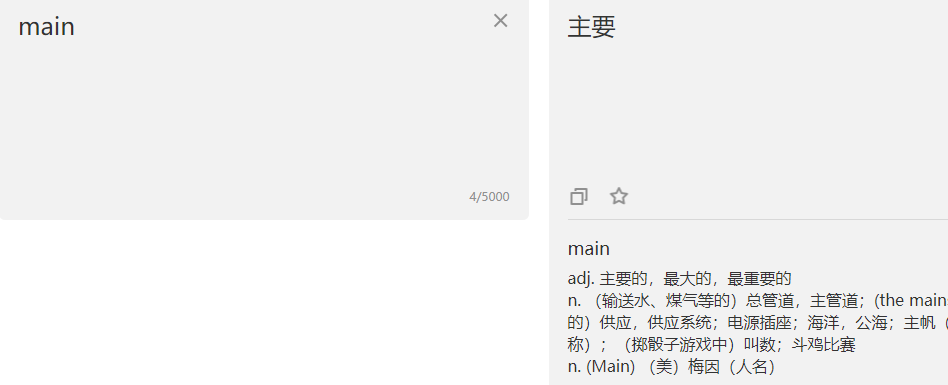
抓包查看请求的接口:

然后请求参数有这些:

一看,i应该就是我传的参数了,常规思维走起来,直接复制这些参数,然后在python里运行:
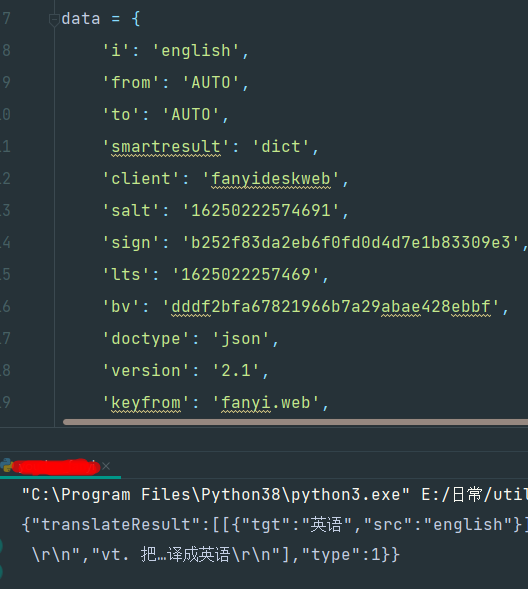
我把i换成main翻译试试:
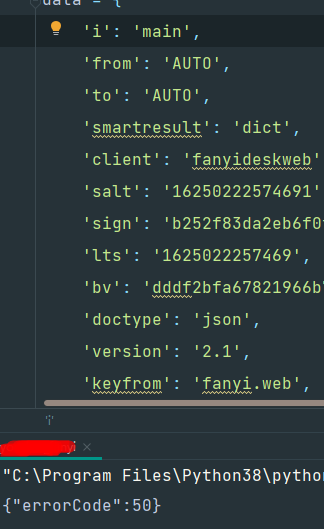
不行了,有点意思哈,为啥复制的english就可以翻译呢?
原因是这样的:
像这种翻译平台,肯定很多人调用,然后同时段用的人肯定很多,加上,有些人有一种习惯,就是在翻译中途,数据还没出来的话,就想再点一次,而此时服务器其实翻译好了正准备返回或者已经返回,这样,服务器缓存一下,可以节省实际的翻译部分代码产生的资源占用,而直接就把翻译结果返回了,同时可以把这个资源给其他需要翻译的人用,所以就会有为什么同一个待翻译字段和同一组请求参数可以用,换一个待翻译字段用同一组请求参数就不能用了。
有朋友会说了,同一个待翻译字段,它同一套加密算法,出来肯定是一样的值啊,所以怎么确定不是同样的翻译一次而是你说的缓存翻译结果直接返回呢,注意哈,请求参数里有个时间戳字段,这个可是每次都会变的啊,所以大概率是我说的那种情况。当然实际情况是这样的啊,我也不是该平台的实际研发人员,所以具体情况我也不清楚哈
接着我又翻译几次之后,发现,就有4个值是一直会变得,其他不会变,就 lts,bv,salt,sign,就这四个,然后i就是我们输入的待翻译的字段
好,不废话,直接看这几个值在哪生成的,直接全局搜sign:

进入这个js文件,再搜,看到有11处,好,那一个一个看下

第一个:
这个的请求参数不太像,再看下面的,

这个也不太像,我们刚才的请求参数没有cache这个值,接着再看:

这个有点像,
再接着看:
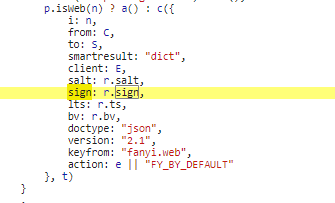
这个感觉有点像
分析
对上面看到的两处有点像的,打上断点看看:
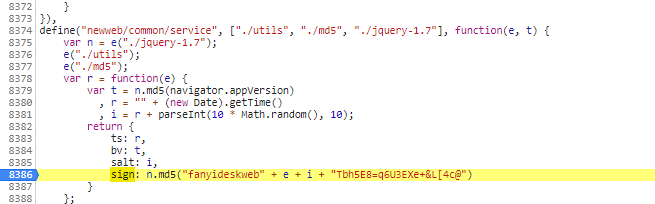
动态调试
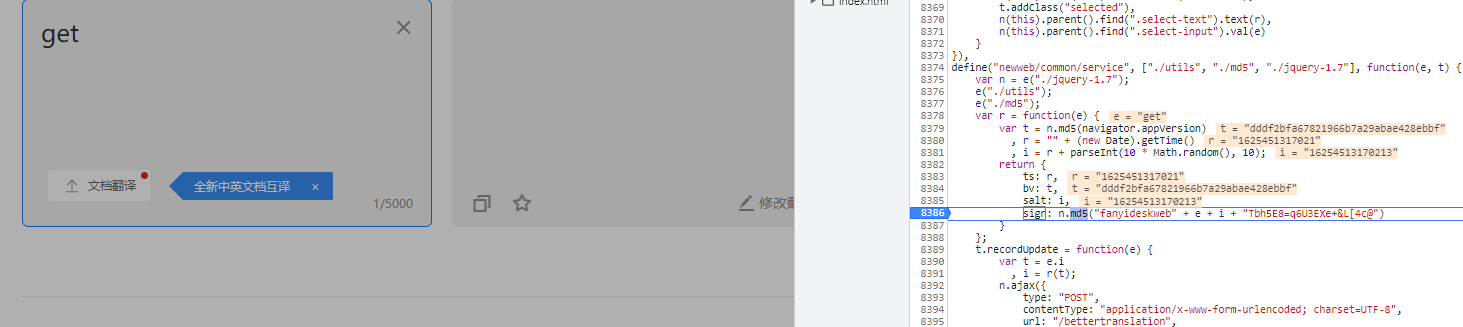
输入get立即就被断上了,那说明我们打断点打对地方了
那么我们开始找那4个参数怎么来的了
第一个,ts

不用说了,这个就是个时间戳,然后被转成了字符串的,先看下它是多少位的时间戳:
用在线的时间戳转换工具直接看

看来是毫秒级的时间戳了,而我们python默认的time模块并不是毫秒级的:
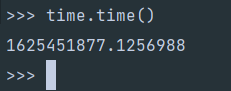
这个后面乘以个1000然后取整就可以了,ts搞定了
第二个,bv

看代码,bv其实就是t,而t 就是navigator.appversion参数再md5之后的字段,先看下navigator.appversion是啥东西,把鼠标放上去,它自己就显示了

不觉得这个很像个啥吗,搞爬虫,应该一眼就能认出来这是啥了,就是ua啊,

然后用第一个【/】作为分隔符把它分割了:
用python做个验证,这个值果然可以对上

也就是说,只要我们的请求不变,那一直都可以用这个值。
第三个,salt
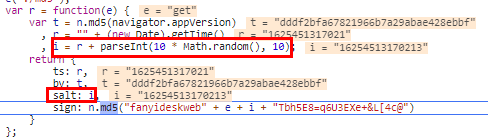
这个,看代码就看出来,就是用刚才的时间戳参数,然后乘以了一个随机的0到1之间的小数,然后再乘以10取整数跟之前的时间戳以字符串拼接起来的,那不就是直接加了一个0-9的随机整数嘛
第四个,sign
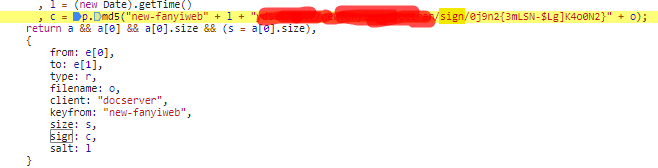
这个就是最重要的了,
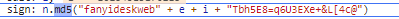
而,主要就是看下e和i是啥了,仔细看,
e就是我们待翻译参数

i就是刚才的salt参数了
这个sign参数每次都是由时间戳+待翻译参数生成出来的,这也是为什么,刚才我用同一组固定的请求参数翻译【english】时可以翻译,但是翻译【main】不行了
ok,后面就是代码实现了
python实现
import requests
import time
from hashlib import md5
import random
def get_md5(something):
if isinstance(something, str):
m = md5()
m.update(something.encode('utf-8'))
return m.hexdigest()
def format_ts():
now = time.time()
now = int(now * 1000)
return now
def format_bv(some_headers):
ua = some_headers.get('User-Agent')
ua = ua.split('/', 1)[1]
# print(1231232, ua)
bv = get_md5(ua)
return bv
def format_salt(ts):
# ts + parseInt(10 * Math.random(), 10)
number = random.randint(0, 9)
if not isinstance(ts, str):
ts = str(ts)
salt = ts + str(number)
return salt
def format_sign(keywords, salt):
# n.md5("fanyideskweb" + keywords + salt + "Tbh5E8=q6U3EXe+&L[4c@")
k = 'fanyideskweb' + keywords + salt + 'Tbh5E8=q6U3EXe+&L[4c@'
sign = get_md5(k)
return sign
def main(keyword):
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="90", "Google Chrome";v="90"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'Origin': 'https://xxxx.com',
'Referer': 'https://xxxx.com'
}
# 获取结果
url = 'xxxx ' # 保密
data = {
'i': keyword,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '',
'sign': '',
'lts': '',
'bv': '',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'
}
ts = format_ts()
___rl__test__cookies = ts + 3
salt = format_salt(ts)
bv = format_bv(headers)
sign = format_sign(keyword, salt)
if ts and salt and bv and sign:
data['lts'] = ts
data['sign'] = sign
data['salt'] = salt
data['bv'] = bv
req = requests.post(url, headers=headers, data=data)
res = req.content.decode('utf-8')
print(2313123, res)
return res
main('get')
执行:
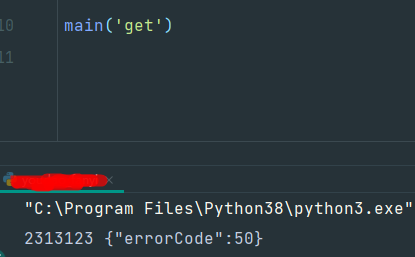
跟预期的有点不太一样啊,这个就很骚了,仔细检查代码,发现设置的这些值也没问题啊,到底哪里呢,想下为啥浏览器可以,代码为啥不行呢,有点了解的会立即想到cookie问题,看下是不是呢?
cookie字段
没事,我们用requests的session对象来请求,它会自动保存cookie的
import requests
import time
from hashlib import md5
import random
def get_md5(something):
if isinstance(something, str):
m = md5()
m.update(something.encode('utf-8'))
return m.hexdigest()
def format_ts():
now = time.time()
now = int(now * 1000)
return now
def format_bv(some_headers):
ua = some_headers.get('User-Agent')
ua = ua.split('/', 1)[1]
# print(1231232, ua)
bv = get_md5(ua)
return bv
def format_salt(ts):
# ts + parseInt(10 * Math.random(), 10)
number = random.randint(0, 9)
if not isinstance(ts, str):
ts = str(ts)
salt = ts + str(number)
return salt
def format_sign(keywords, salt):
# n.md5("fanyideskweb" + keywords + salt + "Tbh5E8=q6U3EXe+&L[4c@")
k = 'fanyideskweb' + keywords + salt + 'Tbh5E8=q6U3EXe+&L[4c@'
sign = get_md5(k)
return sign
def main(keyword):
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="90", "Google Chrome";v="90"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'Origin': 'https://xxxx.com',
'Referer': 'https://xxxx.com'
}
# # 获取cookie
session = requests.session()
req = session.get('xxxx', headers=headers) # 主站地址,保密
print(session.cookies.items())
# 获取结果
url = '' # 保密
data = {
'i': keyword,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '',
'sign': '',
'lts': '',
'bv': '',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'
}
ts = format_ts()
salt = format_salt(ts)
bv = format_bv(headers)
sign = format_sign(keyword, salt)
if ts and salt and bv and sign:
data['lts'] = ts
data['sign'] = sign
data['salt'] = salt
data['bv'] = bv
req = session.post(url, headers=headers, data=data)
res = req.content.decode('utf-8')
print(2313123, res)
return res
main('name')
再执行看看,翻译成功:

是不是以为就完了?
但是,我多了个心眼,感觉这个cookie不止这些,一定有猫腻,结果,果然,我上面的代码还没请求几次就返回了个errorcode,那么看看浏览器上的cookie到底有哪些:
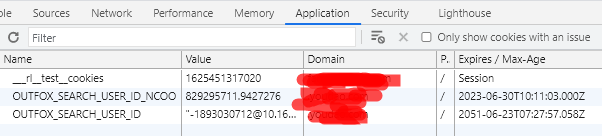
目前是这几个值,我再翻译下,看它会不会有新的变化

翻译了哈,再过来看这边的cookie:
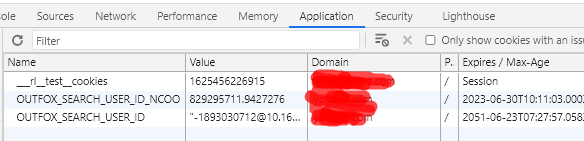
这个__rl_test_cookies变了,为了安全起见,得把这个__rl_test_cookies也用python实现下
那么接着来,在js里看看咋来的,同样的方法接着搜

很快就找到这段逻辑:
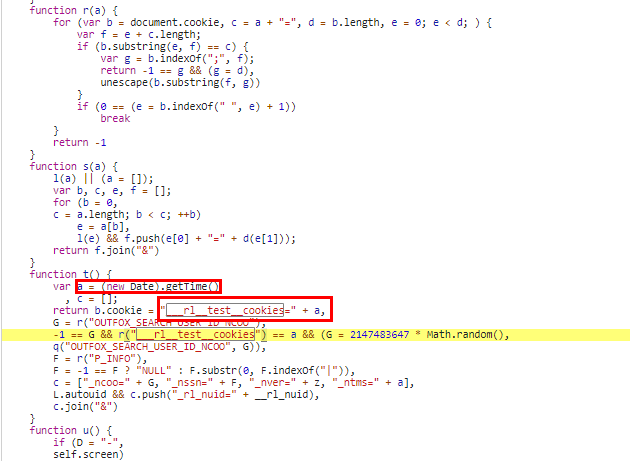
也就是这个a就是被赋值给了__rl_test_cookies,而a其实也是个时间戳字段,
要注意的是,先看请求接口时提交的参数:
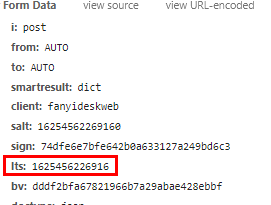
lts是1625456226916
cookie里是,1625456226915
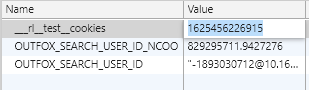
两个时间段差距很小,去格式化的时候出来的时间时分秒相等,也就细微的不一样,那我后续就在lts之上加或者减一个很小的值就可以了,然后有朋友要问,就用lts的时间戳不可以吗,我试了是可以的,但是,为了不被发现还是尽量别用同一个
同时G = 2147483647 * Math.random()其实也是OUTFOX_SEARCH_USER_ID_NCOO的值,
可以在console里调试下:


至少长度是匹配的,经过我的测试也是可行的。
然后也就OUTFOX_SEARCH_USER_ID是没有,另外两个变量都有了,另外OUTFOX_SEARCH_USER_ID是我们请求主站的时候自己返回的。
也就是我们所有的可变的参数lts,bv,salt,sign,OUTFOX_SEARCH_USER_ID,__rl_test_cookies,OUTFOX_SEARCH_USER_ID_NCOO都拿到了,现在就好办了。
最后的代码:
import requests
import time
from hashlib import md5
import random
def get_md5(something):
if isinstance(something, str):
m = md5()
m.update(something.encode('utf-8'))
return m.hexdigest()
def format_ts():
now = time.time()
now = int(now * 1000)
return now
def format_bv(some_headers):
ua = some_headers.get('User-Agent')
ua = ua.split('/', 1)[1]
# print(1231232, ua)
bv = get_md5(ua)
return bv
def format_salt(ts):
# ts + parseInt(10 * Math.random(), 10)
number = random.randint(0, 9)
if not isinstance(ts, str):
ts = str(ts)
salt = ts + str(number)
return salt
def format_sign(keywords, salt):
# n.md5("fanyideskweb" + keywords + salt + "Tbh5E8=q6U3EXe+&L[4c@")
k = 'fanyideskweb' + keywords + salt + 'Tbh5E8=q6U3EXe+&L[4c@'
sign = get_md5(k)
return sign
def main(keyword):
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="90", "Google Chrome";v="90"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'Origin': 'https://xxx.com',
'Referer': 'https://xxx.com'
}
# # 获取cookie
session = requests.session()
req = session.get('', headers=headers)
print(session.cookies.items())
time.sleep(2)
# 获取结果
url = '' #保密
data = {
'i': keyword,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '',
'sign': '',
'lts': '',
'bv': '',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'
}
ts = format_ts()
___rl__test__cookies = ts + 3
salt = format_salt(ts)
bv = format_bv(headers)
sign = format_sign(keyword, salt)
if ts and salt and bv and sign:
data['lts'] = ts
data['sign'] = sign
data['salt'] = salt
data['bv'] = bv
cookie = headers.get('Cookie')
if not cookie:
cookie = ''
for key, value in session.cookies.items():
if key and value:
cookie += '%s=%s; ' % (key, value)
cookie += '___rl__test__cookies=%s' % ___rl__test__cookies
headers['Cookie'] = cookie
req = session.post(url, headers=headers, data=data)
res = req.content.decode('utf-8')
print(2313123, res)
return res
main('put')
这个也是可以正常翻译的,而且长期可用。
对了,cookie里的这两个参数我虽然知道了怎么生成的,我没有去生成了,看浏览器里的过期时间,最早的截止在2023年去了,所以我暂时不管了。

笑死,我2023年的时候还能继续做程序员还不一定呢,说不定那个时候不知道在哪个工地上搬砖呢,哈哈哈(手动滑稽)
ok,完毕!!!!
另外,我们如果要部署到项目里的话,因为翻译字段和请求参数是配套的,翻译一次之后就可以在短期内一直用了,那么就可以做到一定的缓存机制了,也就是一个单词翻译过后我就可以再次用之前的请求参数一直翻译了。当然有个问题就是,也不知道它服务器是怎么缓存的,有可能就存个一周还是多久,肯定不会永久存储的,所以,我们可以控制在3天左右如果有相同翻译字段的话就可以缓存下
附言:
看出是哪个平台的朋友请不要评论或者说明是哪个网站,谢谢,为了安全起见哈!
这个平台其实也挺简单的,代码都没加密,也没有涉及到深入的算法,都是直接md5就完事儿了
20210706更新
今天再看的时候,发现,代码里面的那段加密字段变了

而且我用旧的key确实没法得到正常的翻译结果了,我用新的key替换旧的key,然后得到正常的结果。所以这个还不能写死,就追溯下这个js文件怎么加载的,通过源头,再实际的请求js的源地址,再去抠出新的key,运用到代码里即可