数据库有三级模型的概念,在这里,数据仓库也是有着三级模型并且是有着相似的思路。
1.概念模型
“信息世界”中的信息结构,也常常借用关系数据库设计中的E-R方法,不过在数据仓库的设计是以主题替代实体。
根据业务的范围和使用来划分主题
划分的方法是首先要确定系统边界,包括了解决策者需求(关注点),需求类型。通过对业务系统的详细说明,确定数据覆盖范围,对数据进行梳理,列出数据主题详细的清单,了解源数据状况。
对每个数据主题都作出详细的解释,然后经过归纳、分类,整理成各个数据主题域,确定系统包含的主题。列出每个数据主题域包含哪些部分,并对每个数据主题域作出详细的解释,最后划分成主题域概念模型。

2.逻辑模型
逻辑模型的设计是数据仓库实施中最重要的一步,因为它直接反映了数据分析部门的实际需求和业务规则,同时对物理模型的设计和实现具有指导作用。它的特点就是通过实体和实体之间的关系勾勒出整个企业的数据蓝图和规划。逻辑模型一般遵循第三范式,与概念模型不同,它主要关注细节性的业务规则,同时需要解决每个主题包含哪些概念范畴和跨主题域的继承和共享的问题。
根据需求列出需要分析的主题,需求目标纬度指标,纬度层次分析的指标,分析的方法、数据来源等
对于一些纬度存在层次问题,比如说产品存在产品的类别,产品的子类别以及具体的产品
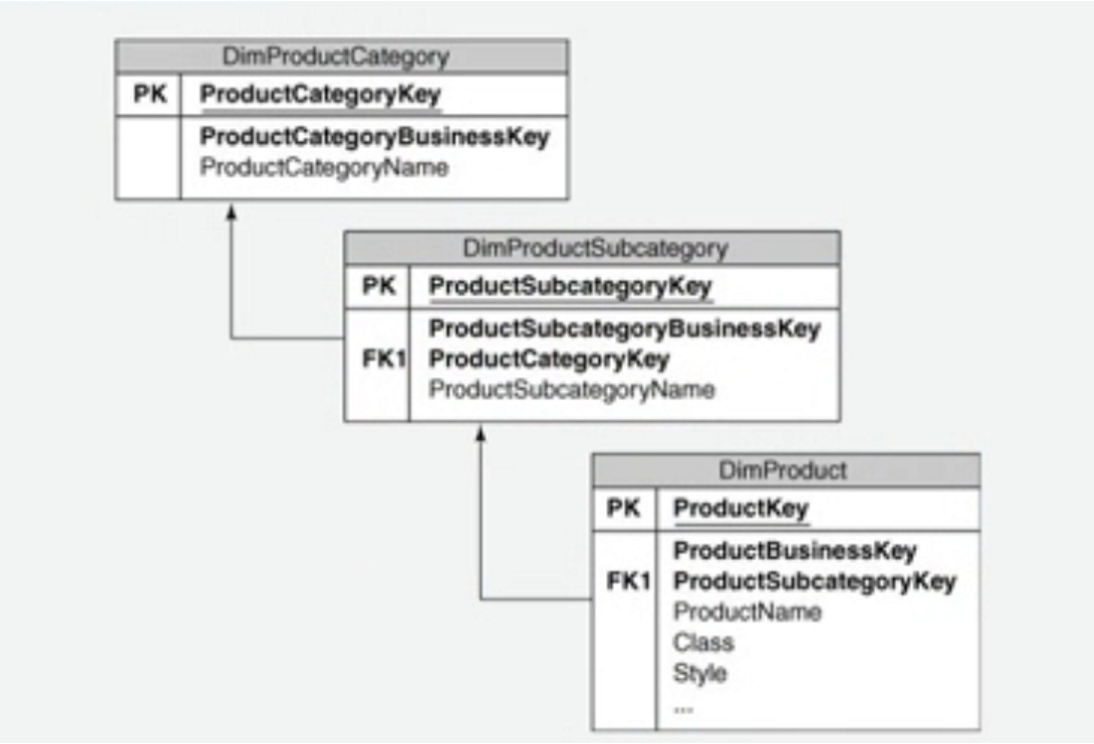
在逻辑模型设计中需要考虑粒度层次的划分。数据仓库的粒度层次划分直接影响了数据仓库模型的设计,通常细粒度的数据模型直接从企业模型选取实体作为逻辑模型的实体,而粗粒度的数据模型需要经过汇总计算得到相应的实体。粒度决定企业数据仓库的实现方式、性能、灵活性和数据仓库的数据量。
粒度指的是描述数据的综合程度。粒度规定了数据仓库潜在的能力和灵活性,如果没有粒度级别的变化,数据仓库将不能回答需要低于所采用细节级的问题。同时,粒度级别是数据库规模的主要决定因素之一,对操作的开销及性能都有显著影响。
数据粒度越小,信息越细,数据量越大;颗粒粒度越大就忽略了众多的细节,数据量越小。
3.物理模型
将逻辑模型转变为物理模型包括以下几个步骤:
(1)实体名(Entity) 转变为表名(Table)。
(2)属性名(Attribute) 转换为列名(Column) ,确定列的属性(Property) 。
(3)确定表之间连接主键和外键属性或属性组。
在物理模型设计中同时要考虑数据的存储结构、存取时间、存储空间利用率、维护代价等。根据数据的重要程度、使用频率和响应时间将数据分类,不同类数据分别存放在不同存储设备中,重要性高、经常存取并对反应时间要求高的数据存放在高速存储设备上:存取频率低或对存取响应时间要求低的数据可以存放在低速存储设备上。根据数据量设定存储块、缓冲区大小和个数。
两大类物理模型
数据仓库的的数据模型相对数据库更简单一些,根据事实表和维度表的关系,主要有星形结构模型和雪花型结构模型两种。
当所有维表都直接连接到“事实表”上时,整个图解就像星星一样,故将该模型称为星型模型。
星型架构是一种非规范化的结构,多维数据集的每一个维度都直接与事实表相连接,所以数据有一定的冗余,如在商店维度表中,存在省A的城市B以及省A的城市C两条记录,那么省A的信息分别存储了两次,即存在冗余。
雪花型架构相对于星形架构的优点是,能够直接利用现有的数据库建模工具进行建模,提高工作效率;以后对维度表的变更会更加灵活,而星形结构会牵涉到大量的数据更新:由于不存在数据冗余,因此数据的装载速度会更快。雪花型架构通过去除了数据冗余,通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。