Intro
Web Proxy是浏览器和服务器的中间人:浏览器访问网页时,将请求发给代理,由代理将该请求发给服务器;服务器返回结果时,先发送给代理,由代理发给浏览器。之所以这么做,是因为可以在Proxy这做一些事情:
- 防火墙:
有些不能直接访问的网站可以通过代理去访问; - 匿名器:代理可以隐藏浏览器的信息,使其对服务器匿名;
- 缓存:暂存服务器返回结果,加快访问速度。
本项目要实现一个简单的Web Proxy,支持以下Features:
- 中间人功能
- 并发
- 缓存
Background Knowledge
- HTTP/1.0 GET
当用户在浏览器输入URLhttp://www.cnblogs.com/EIMadrigal并按下回车后,浏览器会向代理发送HTTP请求,请求行可能如下:
GET http://www.cnblogs.com:8080/EIMadrigal HTTP/1.1
代理要将这个请求解析为主机名www.cnblogs.com、端口8080和路径/EIMadrigal,之后代理可以尝试连接www.cnblogs.com并且向服务器发送新的HTTP请求,请求行如下:
GET /EIMadrigal HTTP/1.0
- Request Header
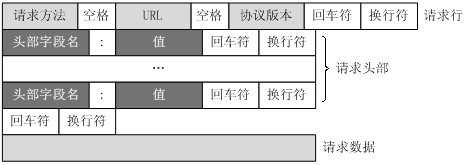
请求头可能有多行,每行的基本组成就是头部字段名和值,需要注意的是:HTTP请求的每一行都以
项目要求:对于浏览器自带的request header,代理应该原封不动地转发。但必须将以下4项补齐,即如果自带的请求头包含以下4项之一,就按照自带请求头转发;否则按照下面的默认值转发。对于自带的其它请求头,直接转发即可:
Host:服务器主机名,如果浏览器自带,直接转发;否则使用请求行里解析出的hostname。
User-Agent:用户的操作系统/浏览器等信息。
Connection:第一次请求/响应完成后,当前连接是否keep alive。
Proxy-Connection:同上。
Host: www.cnblogs.com
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3
Connection: close
Proxy-Connection: close
- 端口
请求端口:URL中的可选字段,如果用户输入时指定,代理应该连接指定端口,否则使用默认端口80。
监听端口:代理应该在该端口监听用户的连接请求,由命令行参数给出。可以是1024~65536之间的未被其他进程占用的任意值。
Implementation
- Sequential Web Proxy
代理首先要接收浏览器HTTP请求,将浏览器的标准请求解析,转换为自己的请求发送。
这里的实现不难,只要模仿Tiny Server在一个死循环中监听来自浏览器的请求,接收之后在void doit(int fd)里完成解析请求行、请求头、将处理后的请求发送给server、接收server的响应并写回浏览器。
一些比较方便的函数:
int accept(int listenfd, struct sockaddr *addr, int *addrlen):在listenfd等待连接请求,将client的socket信息和长度存入addr和addrlen;
int Open_clientfd(char *hostname, char *port):Open connection to server at <hostname, port>, return a socket descriptor ready for reading and writing.
读写时可以使用提供的RIO包。
这里需要注意的是请求的解析:思路是在proxy这里整合所有的请求行和请求头信息,对于所有浏览器发来的请求头的内容,原封不动保存到reqHeader里;对于默认的4个请求头,缺少几个,就按照规定内容增加进去。
还要注意:因为规定Connection和Proxy-Connection都有Connection这个单词,所以用strstr查找的时候:如果浏览器自带的请求头没有Connection但是有Proxy-Connection,这时程序就可能误判为有Connection,所以最好用函数strncmp或者memcmp。
要写一个非常robust的URI解析器还是挺繁琐的,由于C没有正则表达式(也许可以用其他语言写好编译成库,然后C程序调用?),需要考虑的情况很多。
首先明确URI的格式:一般由4部分组成:protocol://hostname:[port]/path/[parameters][?query][#fragment]
协议目前只支持HTTP和HTTPS,其它一律不合法。
因为一旦和服务器建立连接后,protocol和hostname就没用了,只需要path以及后面的query和fragment,为了方便起见,将/也放入path字段,因为其表示根目录,但是对于query和fragment,没有放?和#,因为找到请求内容的位置后,一些具体的搜索/片段直接用关键字即可,与?和#没关系,只有/特殊一些。
- Multiple Concurrent Requests
对于Iterative Server,同时只能处理一个连接请求: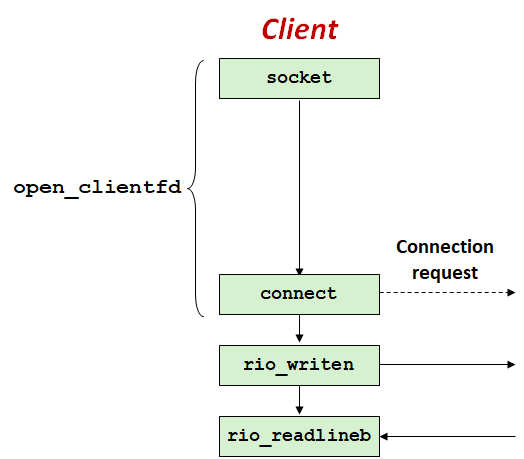
当第二个客户试图去连接:调用connect会正常返回,但Server不会Accept该请求,会用TCP Listen Backlog技术将该请求入队;调用rio_writen也会正常返回,Server会把写入的数据存入缓存;调用rio_readlineb会阻塞,因为Server没有发送任何的response。
解决方法就是并发处理,我们的代理要能同时处理多个请求,具体的方法很多:多进程、I/O多路复用、预线程化(类似生产者-消费者问题,先创建n个线程,相当于n个缓冲区),最直接的方式就是专门有一个线程负责监听,每收到一个连接请求,就开一个新线程去进行读写。这里要采用可分离的线程模型:当其终止时,内存资源会被系统自动回收。
这部分本来很简单,但是写完后测试发现挂了:

这很可能是NOP Server出了问题,这个Server是用Python写的,我去启动了一下:
./nop-server.py 15000
发现:

这个问题是Python的版本不匹配,把nop-server.py第一行的#!/usr/bin/python改为#!/usr/bin/python3即可,指定用python3的解释器执行脚本。
并发这块也妥了:
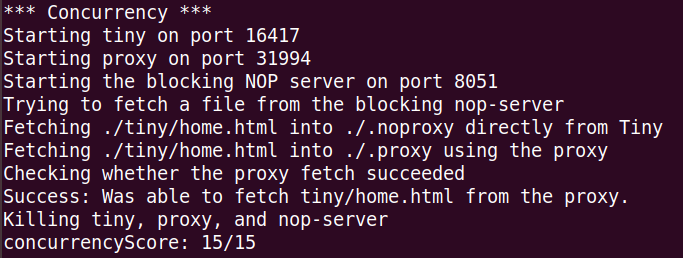
这里的测试逻辑是这样的:Client1通过proxy连接到nop-server,这个服务器永远不会发送response,也就是这条连接一直保持;Client2通过proxy连接到Tiny,看看能不能从Tiny取个文件回来,如果能,说明并发是ok的,如果不能,说明不支持并发。之所以要用nop-server,是因为这东西可以一直连接,比较方便。如果Client1也是通过proxy连Tiny,那么可能很快就执行完了,这时Client2再去连接,很可能就不是并发的访问了,失去了测试的意义。
做第三部分之前,先实际测试下proxy的健壮性。用FireFox浏览器试试,先升级到最新版本,然后设置浏览器的代理方式:
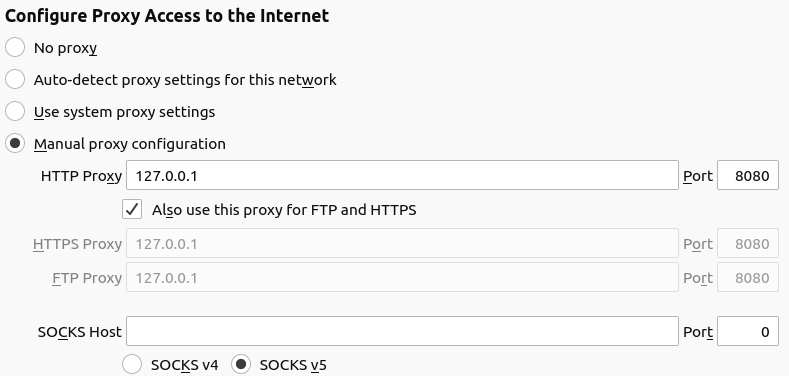
在8080端口运行proxy,然后找个HTTP网站http://csrankings.org/试一下,现在网站基本都是HTTPS,看来后续的Features要支持HTTPS了(先挖个坑)。
运行proxy之前,画风是这样的:
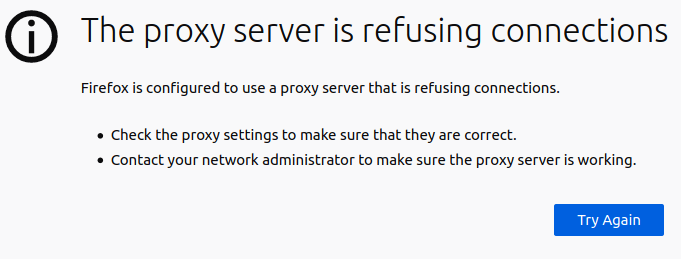
运行proxy之后:
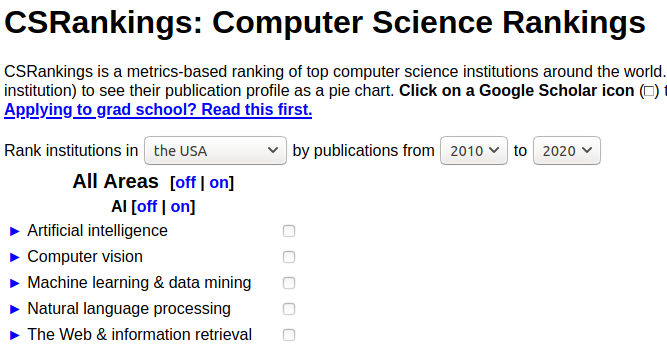
通过代理访问该网页时,页面只能加载一部分,收到59420B数据后,会segmentation fault ,最后发现
主要原因是init_cache()时空间分配写错了,但是修改后又出现了如下错误:

是memcpy时候数组越界,处理buffer时候要千万小心。
这里要改下csapp.c中的错误处理,里面都是直接exit(0),但是作为一个服务器,不能随便终止,所以我们注释掉所有Error-handling functions里的exit(),如果在读数据或者什么时候遇到错误,return即可:exit()是系统调用级别的,结束整个进程;return是函数级别的,返回给调用者,当然在main()里return也就是exit(0)。
- Caching Web Objects
缓存可以说是整个项目的难点,需要考虑的问题比较多。为了模块化,将这一部分单独写作cache.c/cache.h,并修改Makefile。
主要问题有2个:
1、多线程同步:对于cache的访问应当是线程安全的,多个线程可以同时读,但只有一个线程可以写,这就是典型的读者-写者问题(又用到操作系统的知识了);
2、替换策略:cache块的数量是有限的,没有空间时就需要换出换入。一般来讲都是采用LRU方式,一个单线程的严格的LRU Cache可以参考leetcode146题。
我们首先来解决问题一:
读者写者问题可以分为读优先、写优先2种:
读优先:来了一个读进程,除非有一个写进程正在访问,否则读者直接去读,可能导致写进程饥饿;
写优先:有进程读时,如果来了写进程,那么禁止后续读进程请求,现有进程读完后,写进程立即去写,可能导致读进程饥饿。
写优先实现起来稍微麻烦一些,所以这里采用读优先。这里就不自己实现读者写者了,使用读写锁pthread_rwlock_t,确保不会死锁。
接着来解决问题二:
要实现多线程并发LRU Cache,由于C实现双向链表和Hashtable有点繁琐,所以项目要求近似LRU即可:我们可以为每一个cache块附加一个时间戳,每当该块被访问时,就更新时间戳。需要替换时,换出时间戳最小的块即可。这样带来的问题就是:读的时候也需要更新时间戳,但更新时间需要加写锁,如果其他线程占用写锁,那么读进程就无法更新时间戳,也就不是严格的LRU了。
Cache的实现既可以像malloc lab一样采用分级的思想,也可以直接均分所有空间,整体流程如下:
- 初始化
- 查Cache
- 如果miss,寻找可用位置
- 找到可用块,缓存满足大小条件的Object
- 更新时间戳
最大的缓存对象是100KB,一共的空间1MB,平均可以缓存10个Object,这样会浪费24KB空间。所以采用分级的方法:
100KB * 5块 = 500KB
50KB * 6块 = 300KB
20KB * 5块 = 100KB
10KB * 10块 = 100KB
1KB * 24块 = 24KB
接着来构思下存储结构,设计数据结构和类(函数)接口是我认为做一个工程最难的部分,当然还有最后的效率优化问题:
一个cache line最基本的构成需要存储URI和OBJ,因为下次用户请求时代理需要知道请求的是哪个网站的什么内容(通过URI确定),进而如果查找到,将内容OBJ直接返回给用户。同时还需要一个时间戳以及用于同步的读写锁:
typedef struct {
char *uri;
char *obj;
int objSize;
int64_t time;
pthread_rwlock_t rwlock;
} cache_line;
一共有5种类型的cache,每种类型有一个number,还有一个指向该种cache第一块的指针p,p指向该种的第一小块,p+1指向该种的第二小块,以此类推:
typedef struct {
int numOfLine;
cache_line *cachep;
} cache_type;
数据结构设计完后,需要设计函数接口,cache的操作有初始化、查找、写入(替换)和释放:
初始化需要为cache block分配空间,将每一块的时间戳置0,表示该块没有存储内容;
查找时需要遍历所有的type,再在该type中遍历所有的block,如果时间戳不为0,比对浏览器需要访问的URI与当前块的URI是否相等,相等则表示cache hit,直接写回给相应的fd;更新时间戳时,粒度越细越好,这里用gettimeofday精确到微秒级别;读取时如果能申请到写锁,就更新时间,否则就不更新;
写入时需要先计算object大小,寻找空闲的cache block,没有需要替换,满足要求后存入cache,并且将结果返给浏览器。这里要注意寻找空闲块时要从小往大,否则很可能一个很小的object占用了一块很大的block,造成严重浪费,类似于操作系统内存管理动态分配中的最佳适应算法。
那么这种分级的方式的缺点是:每种类型的cache块大小固定,很可能50KB的块只存了10KB内容,造成浪费,类似于固定分区分配。
关于替换,我们采取局部置换策略:即需要换入的object大小如果是30KB,我们只用50KB这种类型去存储,如果50KB的块用完了,就需要换出一块50KB,即使此时100KB的块有空闲,也仍然完成置换过程。
写完cache后,需要修改Makefile,在proxy.c中增加cache的部分。运行完以后,可以用make clean清除目录下多余的垃圾文件,比如.o文件等。
Test
测试的方式一共有3种:
- 自动化测试
利用课程提供的脚本driver.sh自动进行,执行之前,需要安装一些工具:
sudo apt-get install net-tools
做完所有内容后,先用driver.sh进行测试,发现cache部分没分。。。得,开始debug吧!我觉得GDB好难用啊,所以都是通过printfde的。
用curl先通过proxy发个请求,然后看看proxy有没有缓存服务器返回的内容。
最后发现在write_cache时需要用到URI,但是之前解析时候把URI改了,一定注意URI最好不要改,设置为const比较保险。
完了以后,cache满分了,basic又错了一个,fetch可执行对象文件tiny时:

一开始怀疑是tiny太大了,某个数组爆掉了。看了下tiny有36000+B,缓存空间足够,但是可能写入时候有些bug。tiny是二进制文件,可能比较特殊?很奇怪的是:明明objSize是36000+,但是strlen(obj)只有100,怀疑文件中可能有�,提前终止了strlen的计数。
解决方案是write_cache参数不仅要有uri和obj,还要有obj的长度len,否则直接用strlen获取长度可能就挂了。后来修改以后就满分了,一定要注意,如果用char*传参,一定要附带参数len,因为不一定读取的是字符串,还有可能是二进制文件,�也就是0很容易出现,用strlen大概率会爆掉。
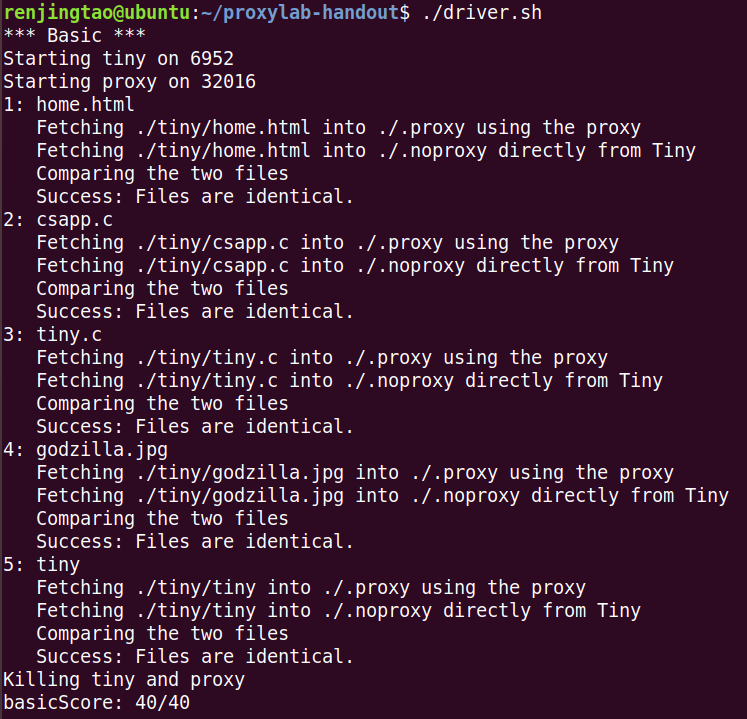
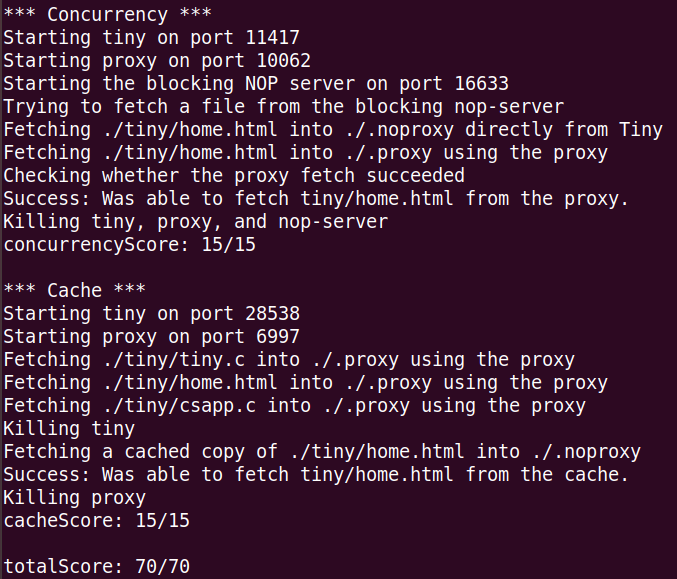
最终测试结果如下:
- 利用
curl工具
curl可以用来生成HTTP请求:假设Sever在端口15213监听,代理在端口15214监听,那么可以通过下面命令经由代理发送请求:
curl -v --proxy http://localhost:15214 http://localhost:15213/home.html
我们用该工具测试下Sequential Web Proxy:
首先启动Tiny Web Server和Proxy:
./tiny 15213
./proxy 15214
然后执行curl命令:
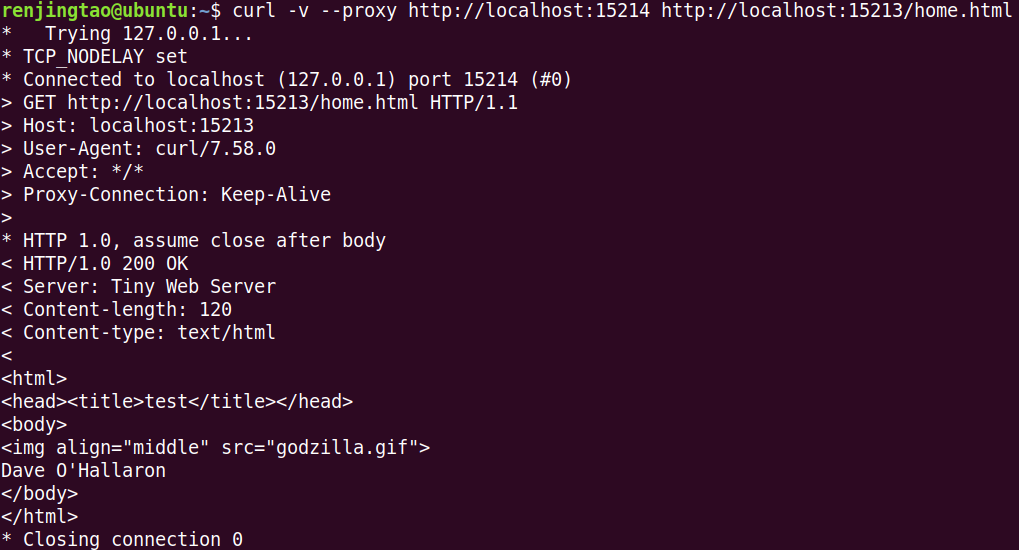
说明基本功能是OK的!!
- 实际浏览器测试
满分之后,万里长征走了一半吧,因为要在实际浏览器测试,不断增强程序的鲁棒性。
测试之前,先禁用浏览器自带的cache,清空之前的缓存。
测下内存泄漏:
valgrind --leak-check=full --show-leak-kinds=all ./proxy 8080
Code&Reference
TODO
接下来的工作可拓展的还有很多,包括但不限于:
- 增加对HTTPS的支持(看起来并不简单)
- Cache这里还有很多可优化的地方(分配策略、置换策略...)
- 目前只支持GET方式,还可以拓展到POST方式