1. 本周学习总结
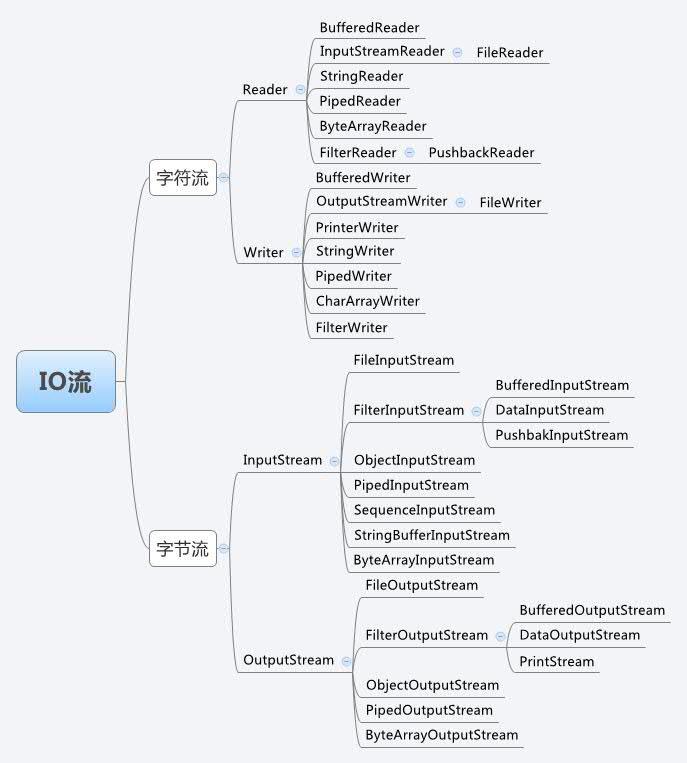
1.1 以你喜欢的方式(思维导图或其他)归纳总结多流与文件相关内容。

2. 面向系统综合设计-图书馆管理系统或购物车
- 使用流与文件改造你的图书馆管理系统或购物车。
2.1 简述如何使用流与文件改造你的系统。文件中数据的格式如何?
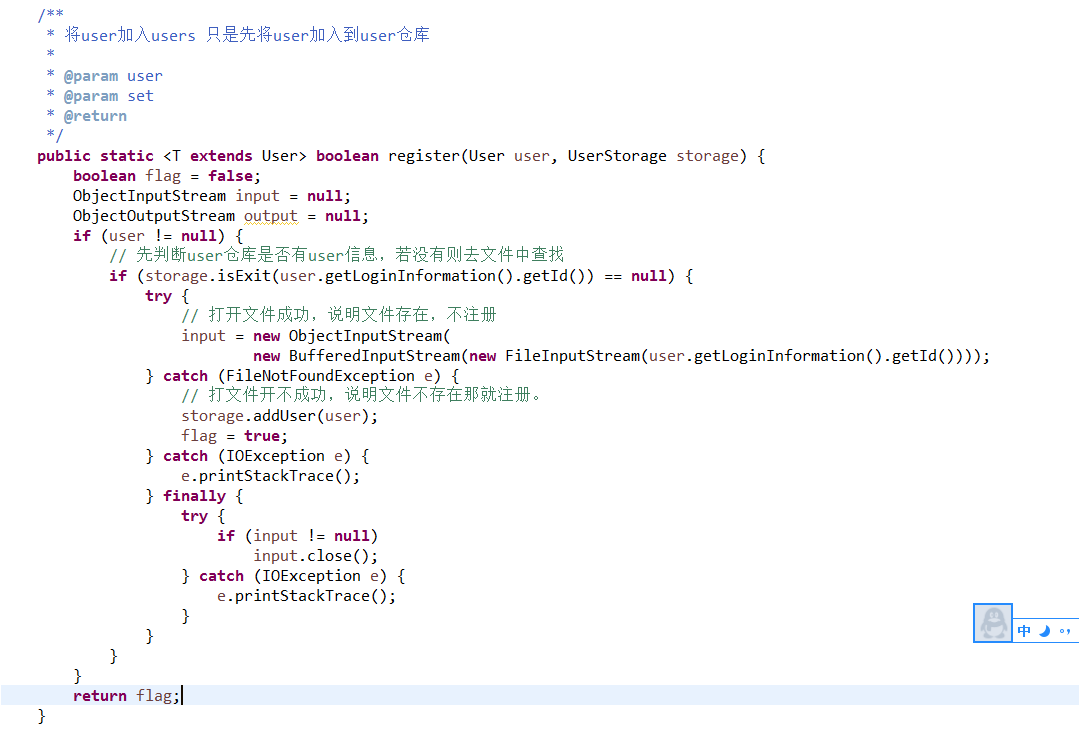
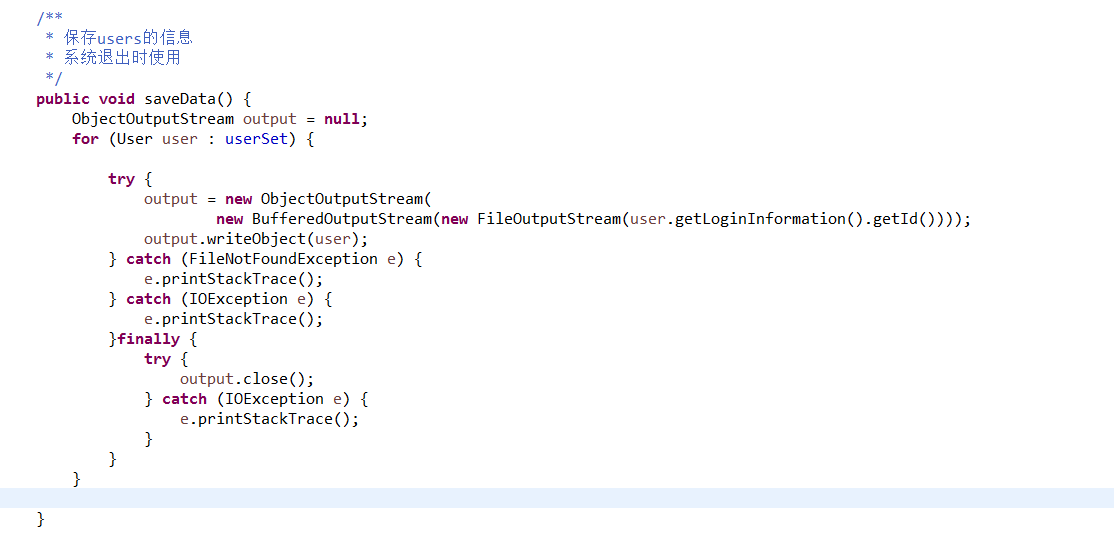
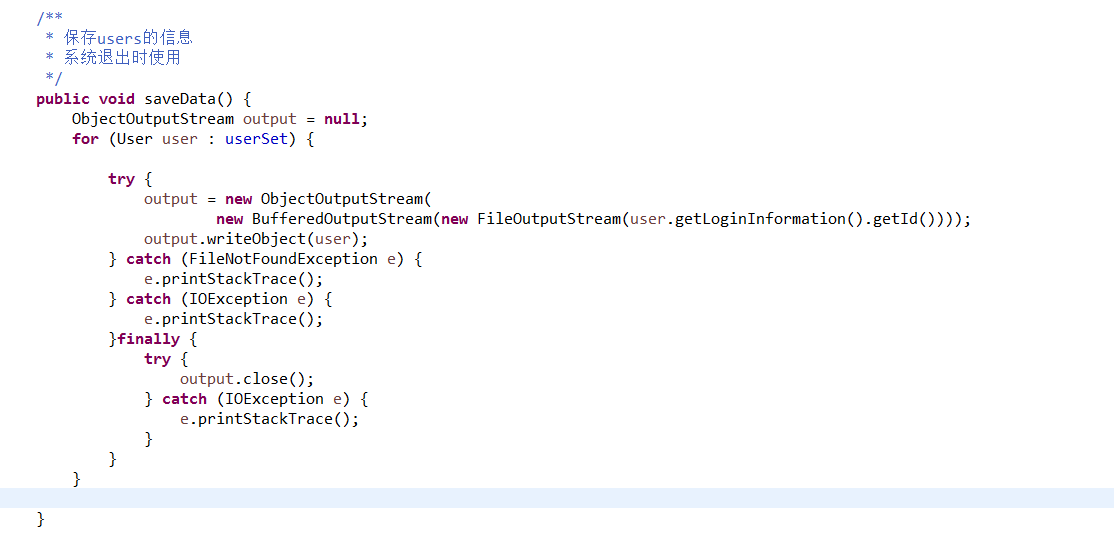
采用对象流将用户信息以及图书馆中的藏书写入流,当启动程序时,进行反序列化操作,当关闭程序时进行序列化操作。对象流写入到文件是以16进制保存的,适用于在网络之间传输。
2.2 简述系统中文件读写部分使用了流与文件相关的什么接口与类?为什么要用这些接口与类?
主要使用了ObjectInputStream和ObjectOutputStream类,Serializable接口。
使用ObjectInputStream和ObjectOutputStream类将整个对象以及其内部的引用变量一起写入流,要进行序列化的对象必须要实现Serializable接口,
2.3 截图读写文件相关代码。关键行需要加注释。


3. 代码量统计
3.1 统计本周完成的代码量
- 需要将每周的代码统计情况融合到一张表中。
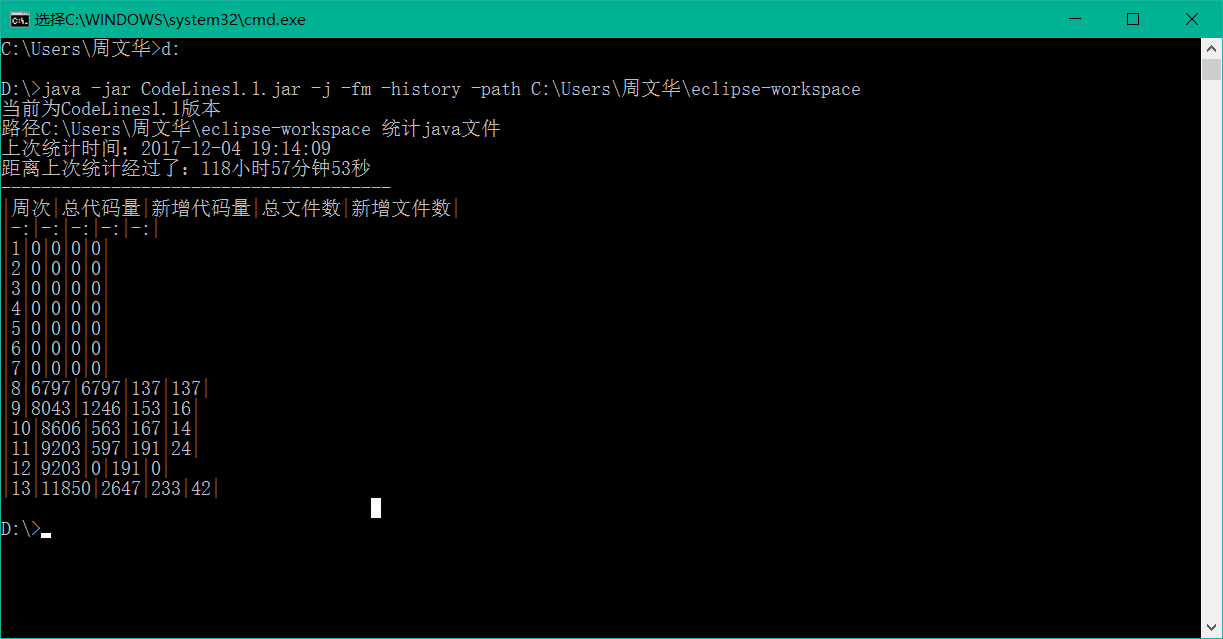
| 周次 | 总代码量 | 新增文件代码量 | 总文件数 | 新增文件数 |
|---|---|---|---|---|
| 1 | 665 | 20 | 20 | 20 |
| 2 | 1705 | 23 | 23 | 23 |
| 3 | 1834 | 30 | 30 | 30 |
| 4 | 1073 | 1073 | 17 | 17 |
| 5 | 1073 | 1073 | 17 | 17 |
| 6 | 2207 | 1134 | 44 | 27 |
| 7 | 3292 | 1085 | 59 | 15 |
| 8 | 3505 | 213 | 62 | 3 |
| 9 | 8043 | 1246 | 153 | 16 |
| 10 | 8606 | 543 | 167 | 14 |
| 11 | 9203 | 597 | 191 | 24 |
| 12 | 9203 | 0 | 191 | 0 |
| 13 | 11850 | 2647 | 233 | 42 |
选做:4. 流与文件学习指导(底下的作业内容全部都是选做)
1. 字符流与文本文件:使用 PrintWriter(写),BufferedReader(读)
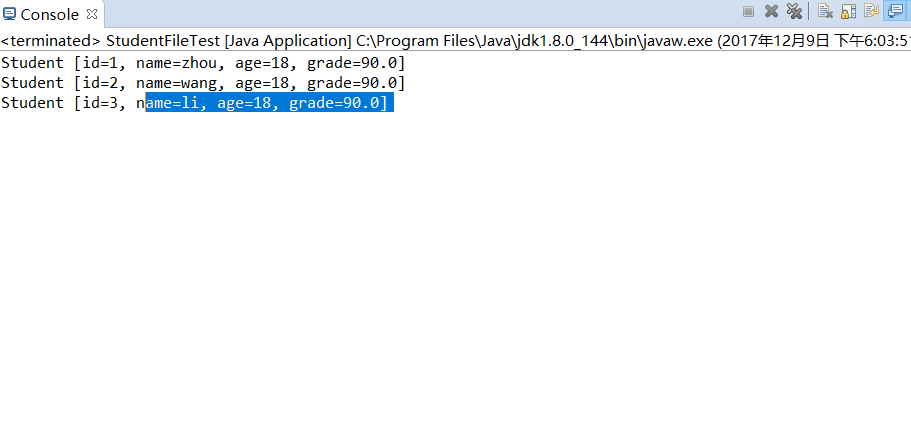
- 将Student对象(属性:int id, String name,int age,double grade)写入文件student.data、从文件读出显示。
1.1 生成的三个学生对象,使用PrintWriter的println方法写入student.txt,每行一个学生,学生的每个属性之间用|作为分隔。使用Scanner或者BufferedReader将student.txt的数据读出。(截图关键代码,出现学号)

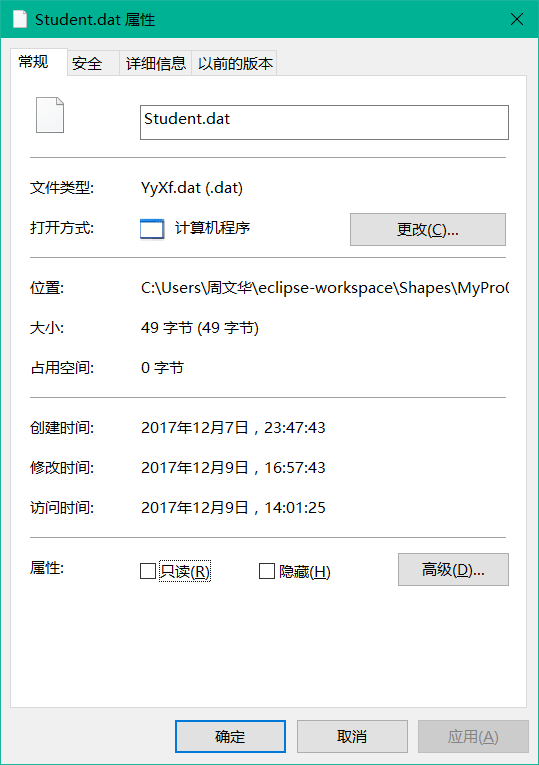
1.2 生成文件大小多少(使用右键文件属性查看)?分析该文件大小


分析: 使用PrintWriter读入一个字符即一个字节,使用println进行写入时一个换行两个字节。
1.3 如果调用PrintWriter的println方法,但在后面不close。文件大小是多少?为什么?
分析:若不进行close,文件大小为0字节。
原因:使用PrintWriter将数据写到缓冲区,close方法可将缓冲区数据写到硬盘,实现真正的存储。
2. 缓冲流
2.1 使用PrintWriter往文件里写入1千万行(随便什么内容都行),然后对比使用BufferedReader与使用Scanner从该文件中读取数据的速度(只读取,不输出),使用哪种方法快?截取测试源代码,出现学号。请详细分析原因?提示:可以使用junit4对比运行时间
测试源代码
@Test
public void PrintWritertest() {
String FILENAME = "test.txt";
PrintWriter pw = null;
try {
pw = new PrintWriter(FILENAME);
for (int i = 0; i < 10000000; i++) {// 写入1千万行
pw.println(new Random().nextInt(100000));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
pw.close();
}
}
@Test
public void BufferedWritertest() {
String fileName = "test.txt";
BufferedWriter bfw=null;
try {
bfw = new BufferedWriter(new FileWriter(fileName));
for (int i = 0; i < 10000000; i++) {
bfw.write(new Random().nextInt(100000));
}
} catch (IOException e1) {
e1.printStackTrace();
}finally {
try {
bfw.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Test
public void ScannerReaderTest() {
String FILENAME = "test.txt";
Scanner scanner = null;
try {
scanner = new Scanner(new File(FILENAME));
while (scanner.hasNextLine()) {
scanner.nextLine();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
scanner.close();
}
}
@Test
public void BufferedReaderTest(){
String FILENAME = "test.txt";
BufferedReader br = null;
try {
br = new BufferedReader(new FileReader(new File(FILENAME)));
while (br.readLine() != null) {
}
;// 只是读出,不进行任何处理
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
使用JUnit 4时间对比

分析:由图可知使用缓冲区进行读写的时间较快。
2.2 将PrintWriter换成BufferedWriter,观察写入文件的速度是否有提升。记录两者的运行时间。试分析原因。
原因:缓冲区,内存里的一块区域,采用缓冲区时,把数据先存内存里,然后进行一次性写入与读写操作,减少了直接对硬盘的操作次数,提高效率;不采用缓冲区进行读写时,是直接对硬盘进行操作,每次对硬盘定位要花费很长时间。
3. 字符编码
3.1 现有EncodeTest.txt 文件,包含一些中文,该文件使用UTF-8编码。使用FileReader与BufferedReader将EncodeTest.txt的文本读入并输出。是否有乱码?为什么会有乱码?如何解决?(截图关键代码,出现学号)
关键代码:
public static void main(String[] args) throws IOException {
BufferedReader bfr=new BufferedReader(new FileReader("EncodeTest.txt"));
String line=null;
while((line=bfr.readLine())!=null)
System.out.println(line);
}
运行结果

关键代码:
BufferedReader bfr = new BufferedReader(new InputStreamReader(new FileInputStream("EncodeTest.txt"),"GBK"));
String line = null;
while ((line = bfr.readLine()) != null)
System.out.println(line);
}
运行结果
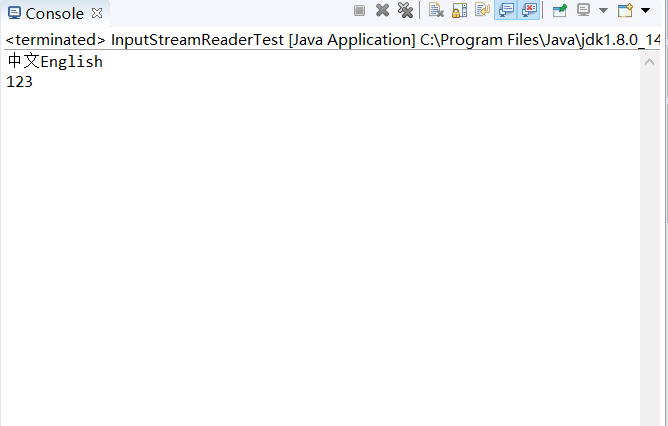
无乱码
关键代码:
BufferedReader bfr = new BufferedReader(new InputStreamReader(new FileInputStream("EncodeTest.txt"),"UTF-8"));
String line = null;
while ((line = bfr.readLine()) != null)
System.out.println(line);
}
运行结果

出现乱码
分析建立文件时时系统默认的编码方式GBK,故使用UTF-8解码时,出现了错误
3.2 编写方法convertGBK2UTF8(String src, String dst),可以将以GBK编码的源文件src转换成以UTF8编码的目的文件dst。
public static void convertGBK2UTF8(String src, String dst) throws IOException {
InputStreamReader ifr = null;
BufferedReader bfr = null;
BufferedWriter bfw = null;
try {
FileInputStream fis = new FileInputStream(src);
ifr = new InputStreamReader(fis, "UTF-8");
bfr = new BufferedReader(ifr);
bfw = new BufferedWriter(new FileWriter(dst));
String line = null;
while ((line = bfr.readLine()) != null) {
bfw.write(line);
bfw.newLine();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if (bfr != null)
bfr.close();
if (bfw != null)
bfw.close();
}
}
4. 字节流、二进制文件:DataInputStream, DataOutputStream、ObjectInputStream
4.1 参考DataStream目录相关代码,尝试将三个学生对象的数据写入文件,然后从文件读出并显示。(截图关键代码,出现学号)
关键代码
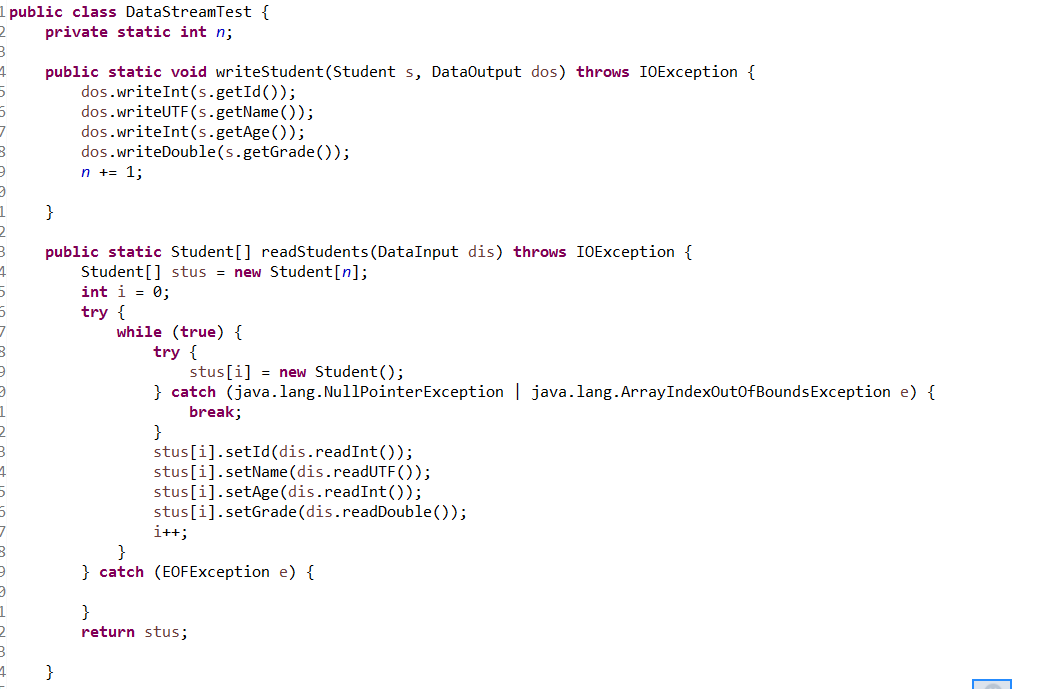
运行结果
4.2 这里生成的文件和题目1生成的文件有何不一样?生成的文件有多大?分析该文件大小?将该文件大小和题目1生成的文件对比是大了还是小了,为什么?存储数据的时候,到底是二进制文件比较节省空间还是文本文件比较节省空间?使用二进制存储文件有何好处?

分析: 该文件以.data后缀结尾,为二进制文件。与1相比文件变大了。
原因: 使用DataOutput写入数据,一个int型占4个字节,一个Double型占8个字节。使用writeUTF写入字符串时一个字符串的字节为字符数加2,写入一个中文是5个字节。
- intByte=4✖6=24
- DoubleByte=3✖8=24
- StringByte=6+6+4=16
- totalByte=24+24+16=64
4.3 使用wxMEdit的16进制模式(或者其他文本编辑器的16进制模式)打开student.data,分析数据在文件中是如何存储的。

4.4 使用ObjectInputStream(读), ObjectOutputStream(写)读写学生。(截图关键代码,出现学号) //参考ObjectStreamTest目录


5. Scanner基本概念组装对象
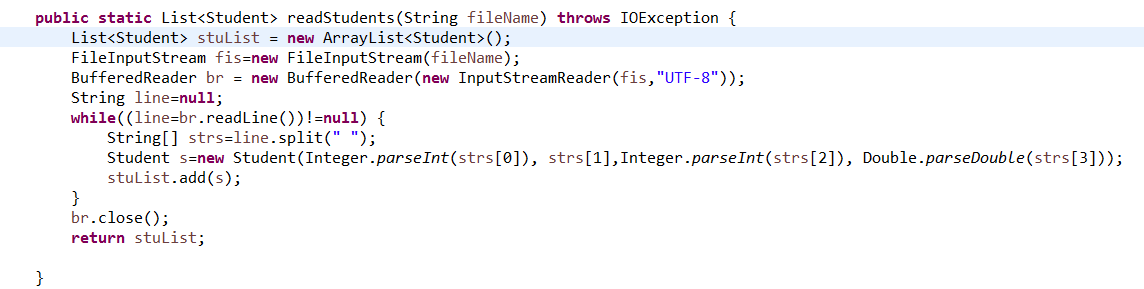
- 编写public static List
readStudents(String fileName)从fileName指定的文本文件中读取所有学生,并将其放入到一个List中。应该使用那些IO相关的类?说说你的选择理由。
关键代码
运行结果

分析: 主要使用了BufferedReader与InputStreamReader。使用BufferedReader是因为读取的是字符串,使用InputStreamReader是因为该文件是以UTF-8编码,读取文件时使用InputStreamReader将系统默认的GBK编码方式转化为UTF-8编码。
6. 选做:RandomAccessFile
6.1 使用RandomAccessFile实现题目1.1。(截图关键代码,出现学号)
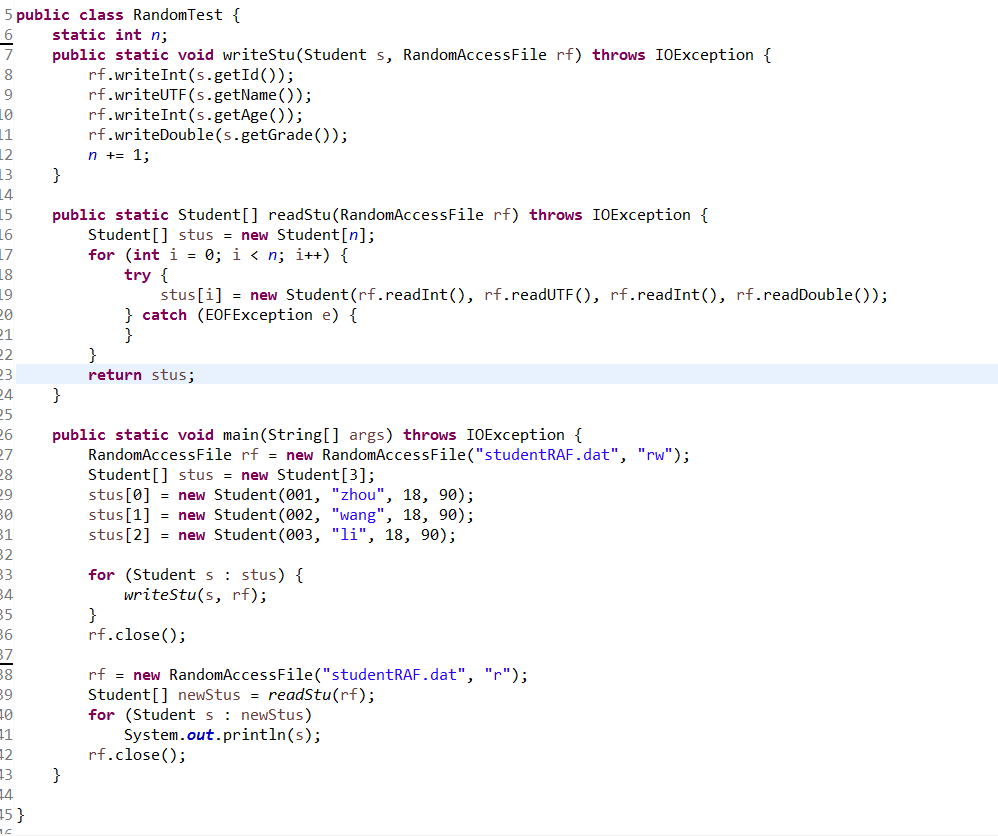
6.2 分析文件大小

分析: 分析过程同4.1
6.3 编写一个函数public Student getStuByIndext(int index),可以根据序号index使用RandomAccessFile从文件中将该学生的信息取出。(截图关键代码,出现学号)。并回答,哪里体现了RandomAccessFile对文件的随机访问特性。
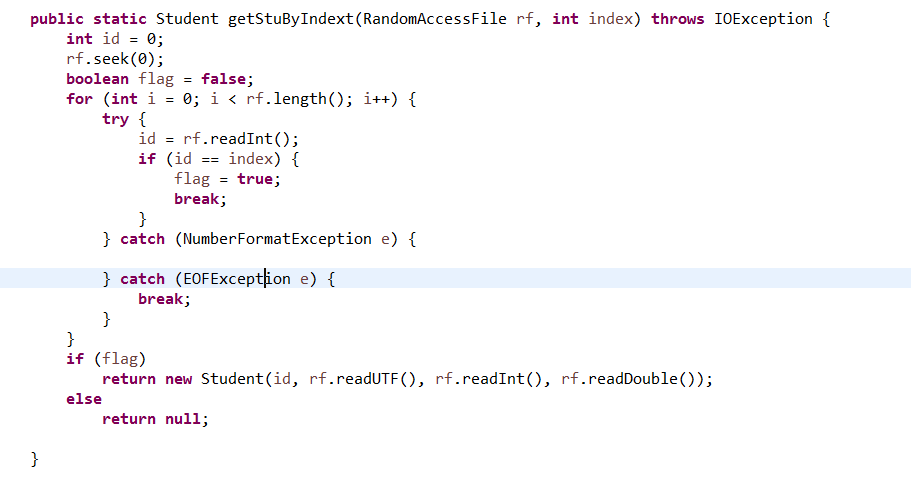
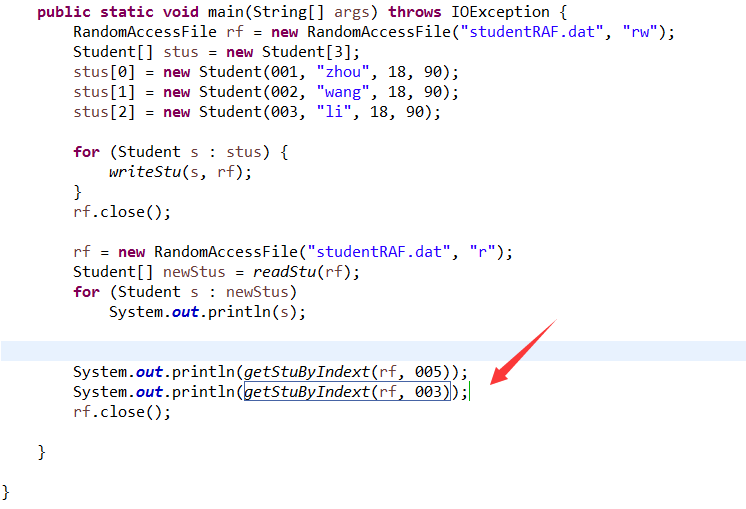
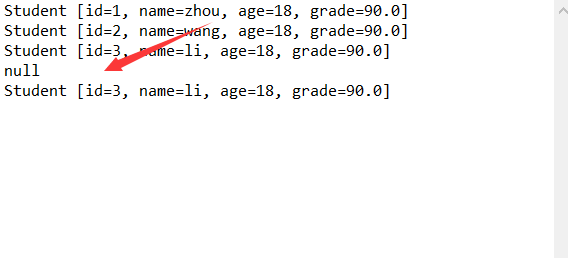
分析: 使用RandomAccessFile可以跳到文件任意位置读写数据,RandomAccessFile对象包含一个记录指针,用以标识当前读写处的位置,当程序创建一个新的RandomAccessFile对象时,该对象的文件记录指针对于文件头,当读写n个字节后,文件记录指针将会向后移动n个字节。
- long getFilePointer():返回文件记录指针的当前位置
- void seek(long pos):将文件记录指针定位到pos位置
7. 文件操作
- 编写一个程序,可以根据指定目录和文件名,搜索该目录及子目录下的所有文件,如果没有找到指定文件名,则显示无匹配,否则将所有找到的文件名与文件夹名显示出来。
7.1 编写public static void findFile(String path,String filename)函数,以path指定的路径为根目录,使用递归方式,在其目录与子目录下查找所有和filename相同的文件名,一旦找到就马上输出到控制台。(截图关键代码,出现学号)

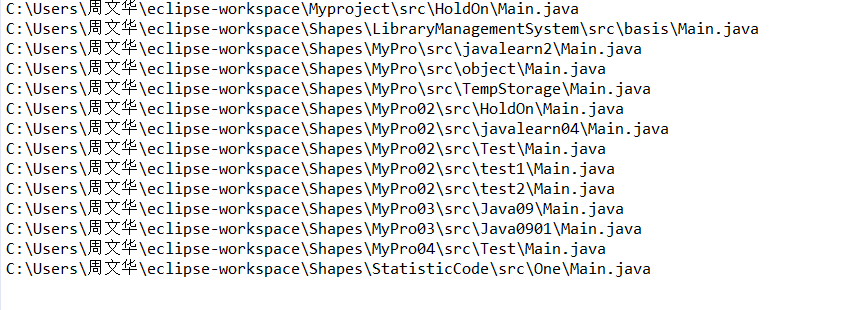
7.2 使用队列、使用图形界面、使用Java NIO.2完成(任选1)

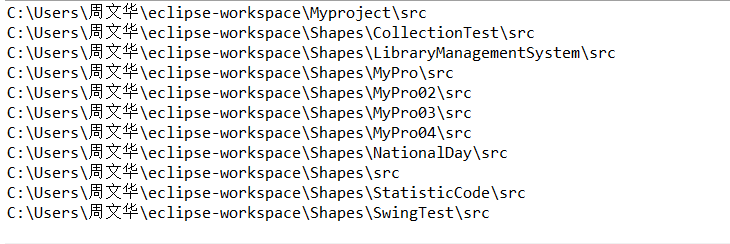
NIO即New IO,这个库是在JDK1.4中才引入的。NIO和IO有相同的作用和目的,但实现方式不同,NIO主要用到的是块,所以NIO的效率要比IO高很多。
面向流的IO一次一个字节的处理数据,一个输入流产生一个字节,一个输出流就消费一个字节。为流式数据创建过滤器就变得非常容易,链接几个过滤器,以便对数据进行处理非常方便而简单,但是面向流的IO通常处理的很慢。
面向块的IO系统以块的形式处理数据。每一个操作都在一步中产生或消费一个数据块。按块要比按流快的多,但面向块的IO缺少了面向流IO所具有的有雅兴和简单性。
7.3 选做:性能测试,测试你的findFile查找匹配文件的速度。有什么解决方案,可以让查找速度更快一些。比如类似Everything的搜索速度。
NIO主要用到的是块,所以NIO的效率要比IO高,具体原因如上题
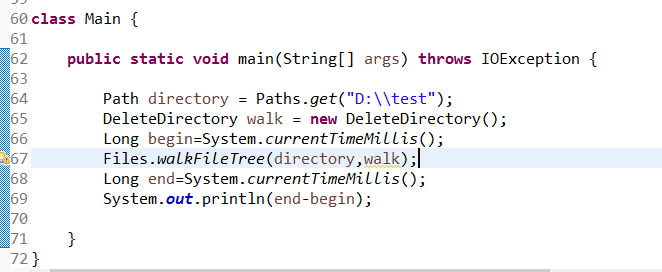
7.4 选做:实现删掉指定目录(如果该目录非空,删除掉该目录下及其子目录下的所有文件与目录)。