sed
sed 是一种流编辑器,常被用于进行文本处理,能够完美的配合正则表达式使用。其处理流程大致分为以下几步:
- 把当前处理的行存储在临时缓冲区中,称为”模式空间”(pattern space)。
- 使用 sed 命令处理缓冲区中的内容。
- 处理完后,把缓冲区的内容送往屏幕。
- 接着处理下一行,这样不断重复,直到文件末尾。
- 整个处理过程文件内容并没有发生改变,除非你使用重定向存储输出。
命令格式:
sed [选项]... {脚本(如果没有其他脚本)} [输入文件]...
sed 支持的命令:
| 命令 | 说明 |
|---|---|
| a | 在当前行下面插入文本 |
| i | 在当前行上面插入文本 |
| c | 把选定的行改为新的文本 |
| d | 删除选择的行 |
| D | 删除模板块的第一行 |
| s | 替换指定字符 |
| h | 拷贝模板块的内容到内存中的缓冲区 |
| H | 追加模板块的内容到内存中的缓冲区 |
| g | 获得内存缓冲区的内容,并替代当前模板块中的文本 |
| G | 获得内存缓冲区的内容,并追加到当前模板块文本的后面 |
| l | 列出不能打印字符的清单 |
| n | 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令 |
| N | 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号 |
| p | 打印模板块的行 |
| P | 打印模板块的第一行 |
| q | 退出 Sed |
| ! | 后面的命令对所有没有被选定的行发生作用 |
| = | 打印当前行号 |
| # | 把注释扩展到下一个换行符以前 |
sed 命令的替换标记:
| 标记 | 说明 |
|---|---|
| g | 行内全面替换 |
| p | 打印行 |
| w | 把行写入一个文件 |
| x | 互换模板块中的文本和缓冲区中的文本 |
| \1 | 子串匹配标记 |
| & | 已匹配字符串标记 |
和 grep 一样,sed 也是支持正则表达式的。
使用示例
准备 demo.txt,内容如下:
SDNAIUFQX Q CH9ASGDA
ASNBA3 RQ323 FAK ADN
ASJDBAAJ3DJA 0ADQ38DA
DJAAH 823EU 3U0QJDSD BADI
SDAND8 39E 3IE QD QNDQD09A
ASDVAN3 8AWDA EDN3 8GDA IDA
替换操作(s)
只是将结果输出到屏幕,并不会改变文本的内容。
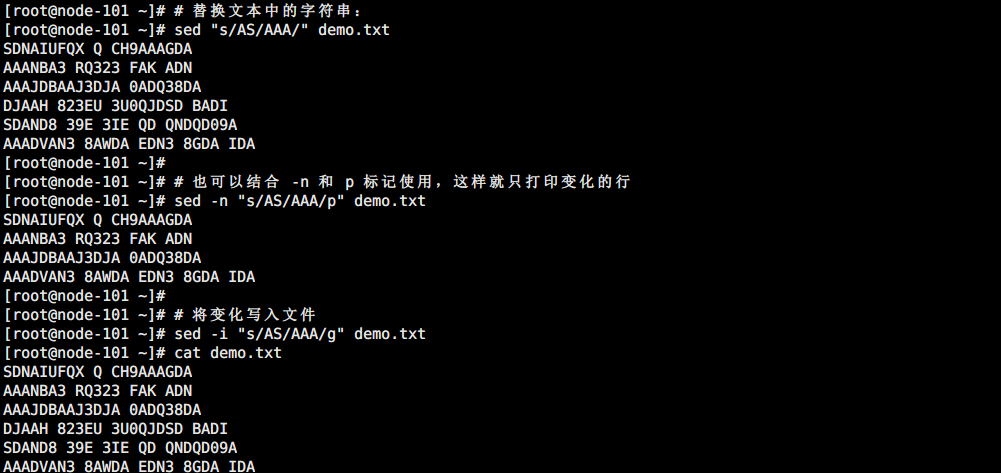
# 替换文本中的字符串:
sed "s/AS/AAA/" demo.txt
# 也可以结合 -n 和 p 标记使用,这样就只打印变化的行
sed -n "s/AS/AAA/p" demo.txt
# 将变化写入文件
sed -i "s/AS/AAA/g" demo.txt
如图所示:
替换标记(g)
使用后缀 /g 标记会替换每一行中的所有匹配,也可指定从哪里开始替换。
# 全替换
echo "AbAbAbAbAbAbAbAb" | sed "s/Ab/Cd/g"
# 从第几个开始替换
echo "AbAbAbAbAbAbAbAb" | sed "s/Ab/Cd/3g"
如图所示:
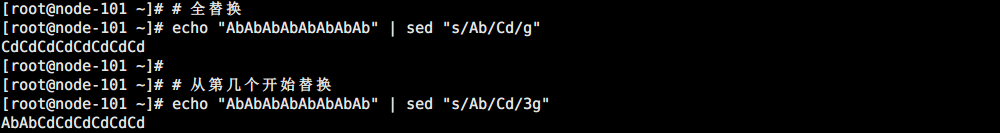
定界符(/)
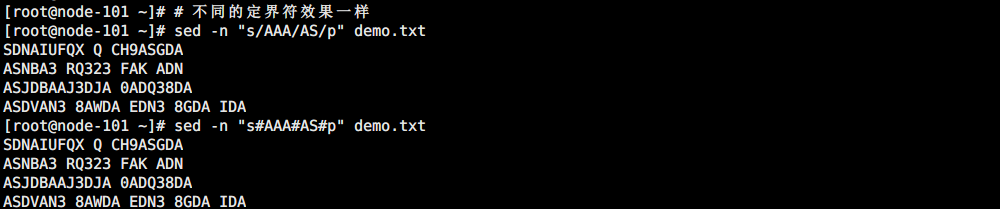
一般默认的定界符就是 /,如果遇到特殊情况,如替换的文本中本身就含有 / 符号,此时就可以使用 \ 转义或者直接使用其它定界符,如::,# 等。
# 不同的定界符效果一样
sed -n "s/AAA/AS/p" demo.txt
sed -n "s#AAA#AS#p" demo.txt
如图所示:
删除操作(d)
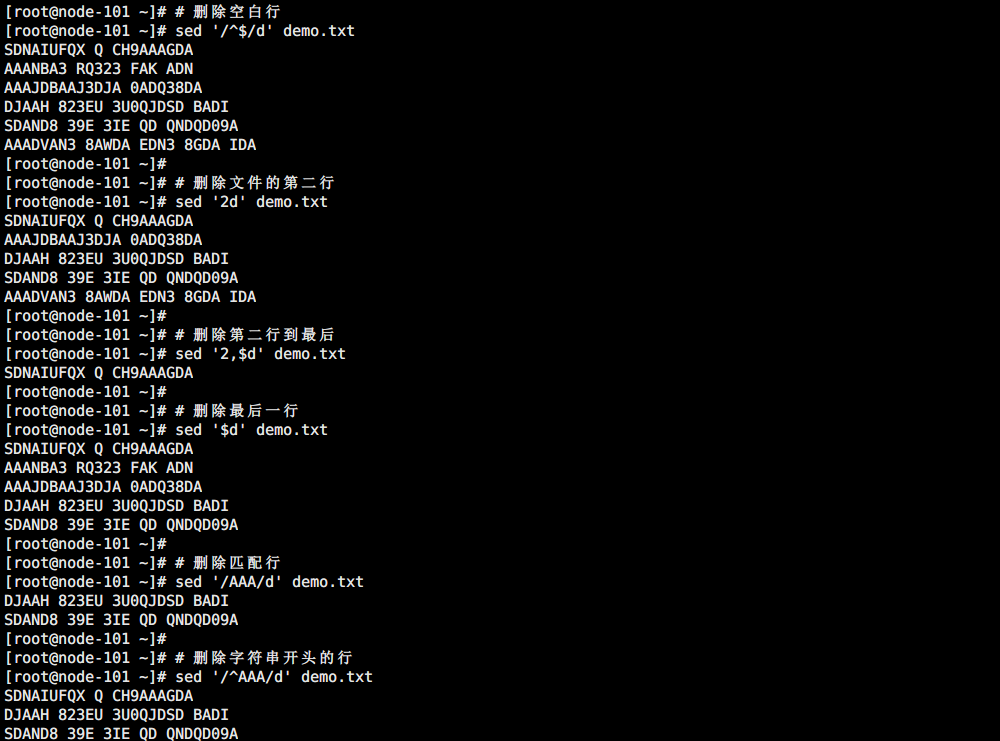
# 删除空白行
sed '/^$/d' demo.txt
# 删除文件的第二行
sed '2d' demo.txt
# 删除第二行到最后
sed '2,$d' demo.txt
# 删除最后一行
sed '$d' demo.txt
# 删除匹配行
sed '/AAA/d' demo.txt
# 删除字符串开头的行
sed '/^AAA/d' demo.txt
如图所示:
已匹配字符标记(&)
& 符号能够指代已经匹配到的项,从而对他进行额外的操作。
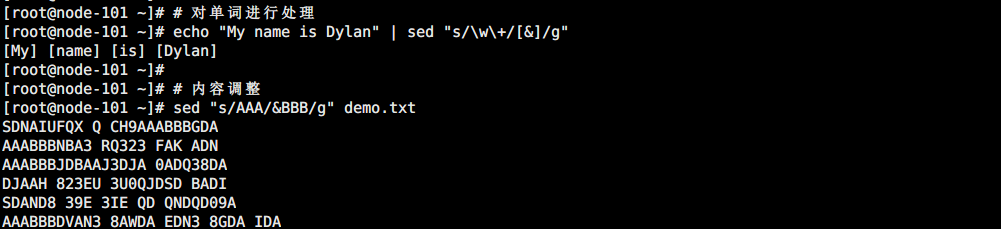
# 对单词进行处理
echo "My name is Dylan" | sed "s/\w\+/[&]/g"
# 内容调整
sed "s/AAA/&BBB/g" demo.txt
如图所示:
字串匹配标记(\1)
在匹配选项中增加 () 能够在后面通过序号应用。
# 只有一个需要引用时
echo "I am 18 years old" | sed "s#am \([0-9]\+\)#\1#g"
# 存在多个引用时
echo "I am 17 or 18 years old" | sed "s#am \([0-9]\+\) or \([0-9]\+\)#\1 OR \2#g"
如图所示:

选定行范围(,)
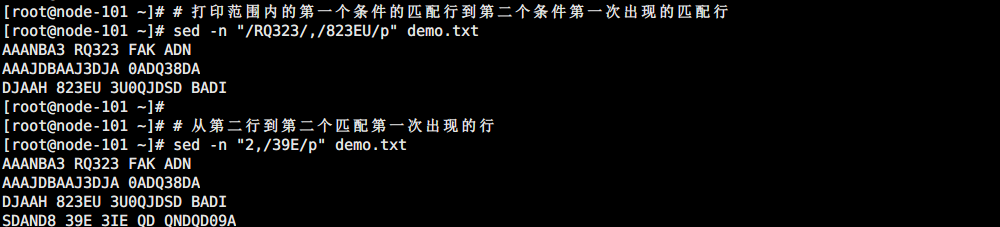
# 打印范围内的第一个条件的匹配行到第二个条件第一次出现的匹配行
sed -n "/RQ323/,/823EU/p" demo.txt
# 从第二行到第二个匹配第一次出现的行
sed -n "2,/39E/p" demo.txt
如图所示:
多点编辑(e)
sed -e "1,2d" -e "s/3IE/BBB/" demo.txt
如图所示:

第一个 e 是删除 1,2 行,第二个 e 是替换字符串,注意顺序对结果是有影响的。
文件读入(r)
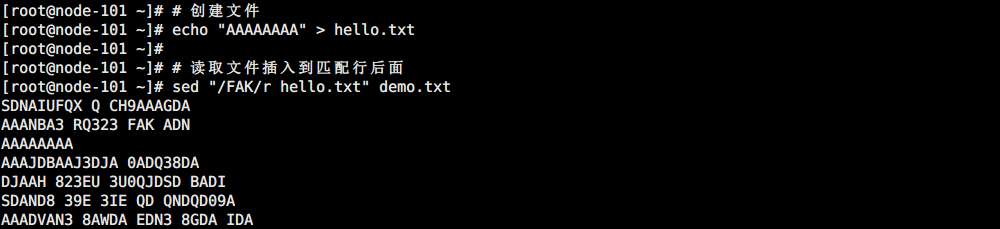
先准备一个 hello.txt 文本:
# 创建文件
echo "AAAAAAAA" > hello.txt
# 读取文件插入到匹配行后面
sed "/FAK/r hello.txt" demo.txt
如图所示:
文件写入(w)
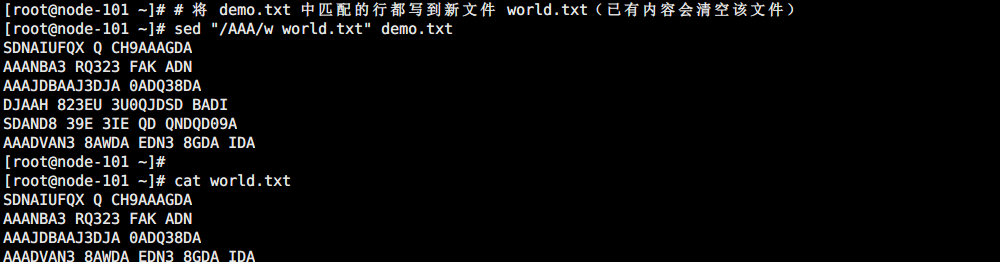
# 将 demo.txt 中匹配的行都写到新文件 world.txt(已有内容会清空该文件)
sed "/AAA/w world.txt" demo.txt
如图所示:
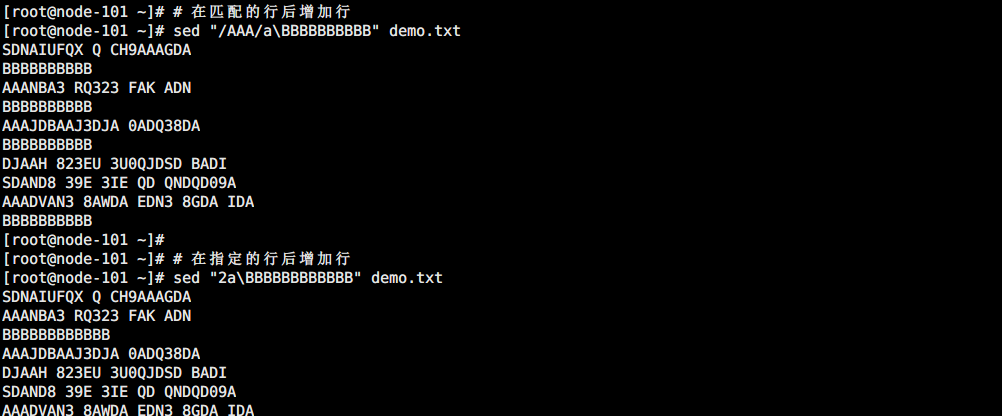
行下追加(a\)
# 在匹配的行后增加行
sed "/AAA/a\BBBBBBBBBB" demo.txt
# 在指定的行后增加行
sed "2a\BBBBBBBBBBBB" demo.txt
如图所示:
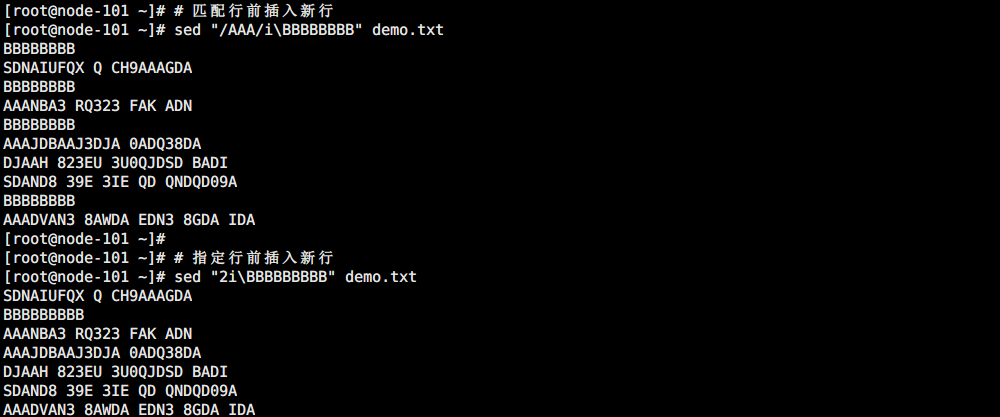
行上插入(i\)
# 匹配行前插入新行
sed "/AAA/i\BBBBBBBB" demo.txt
# 指定行前插入新行
sed "2i\BBBBBBBBB" demo.txt
如图所示:
操作下一行(n)
# 如果条件匹配到,则操作下一行
sed "/FAK/{n; s/AAA/BBB/g}" demo.txt
如图所示:

变形(y)
在操作指定范围的行时需要使用到 y,如果没有 y 会报错。
# 将 1,2 行中的 AAA 换成 aaa
sed "1,2y/AAA/aaa/" demo.txt
如图所示:

退出(q)
# 打印前三行
sed "3q" demo.txt
如图所示:

脚本(scriptfile)
# 先创建一个 sedfile,内容如下
s/FAK/HELLO/g
s/3IE/WORLD/g
1d
# 执行
sed -f sedfile demo.txt
如图所示:

特殊用法
- 输出奇数偶数行:
# 奇数行
sed -n "p;n" demo.txt
# 方法2
sed -n '1~2p' demo.txt
# 偶数行(跳过了第一行,所以是偶数行)
sed -n "n;p" demo.txt
# 方法2
sed -n '2~2p' demo.txt
如图所示:
