故事背景
公司有这样一个需求,需要将某些数据用 BI 工具 Metabase 展示出来,但是这里面就涉及到多个数据库的联合查询的问题。然而这些数据库在不同的机器上面,Metabase 部署基于同一个连接联合查询会有问题,所以就要想办法将这些数据库集中在一个连接上面。
当时方案有以下一些:
1. 使用 MySQL Federated 引擎,在特定的表上面加入联合数据库的连接。(效率很低,很慢)
2. MyCat,连接多个数据库,统一到一个连接。(存在问题,不支持联合)
3. DBLE,MyCat 加强版,能够实现。(连接查询也没问题,但是结合 Metabase 的时候扫描数据不出结果)
最终选择的方式则是通过多主一从的方式将需要的数据库都统一到一个数据库里面,因为这个工具只是很多展示作用,所以访问人数不多。
具体说说实现过程!
搭建方法
1. 首先我目前的服务器结构是这样的:
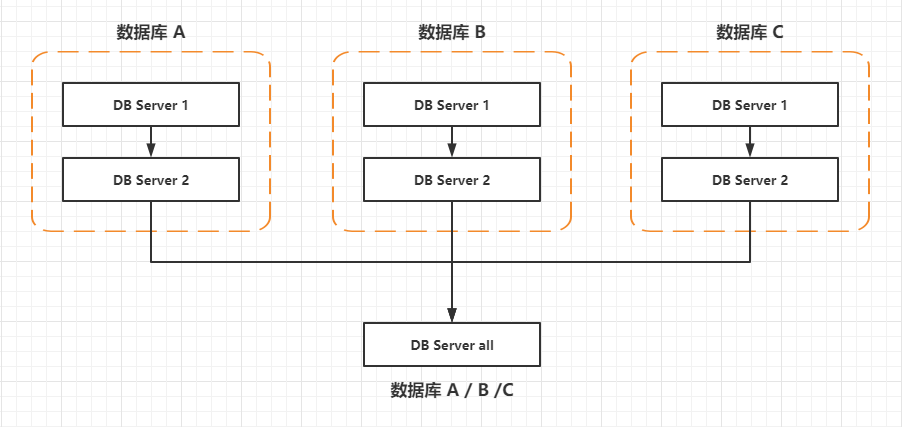
有三个主从结构的数据库,分别各有数据库 A / B / C,我们需要通过各自的 DB Server 2 从库将各自的数据库都同步到 DB Server all 这台服务器上面。
具体主从实现方式可以参考我之前的博客,这里就不多做介绍了。
2. 在各自从库上面配置文件中加入 binlog 需要记录哪些数据库,以 A 为例:
# 记录的数据库 binlog-do-db=A # 忽略的数据库 binlog-ignore-db=information_schema binlog-ignore-db=mysql binlog-ignore-db=performance_schema binlog-ignore-db=sys
这样的目的是为例保证同步不会出现冲突,因为系统的那几个库所有的都有,多要最好忽略他们。
配置完成后需要重启冲库。
3. 在各台数据库的从库上面分别备份指定的库:
mysqldump -uroot -p -E -R --triggers --master-data=2 --single-transaction --max-allowed-packet=64M -B A > A.sql
这里以 A 库为例,然后查看备份文件的指针:
head -50 A.sql
可以看到类似的binlog 位置和指针:
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000006', MASTER_LOG_POS=2664;
我们需要记录下这个:mysql-bin.000006 和 2664。
4. 在 DB Server all 数据库上面将三个库 A / B / C 都导入:
为提升导入速度,我们可以在登录的时候增加参数:
mysql -uroot -p --max-allowed-packet=1024M
登录数据库后临时禁用检查和自动提交,可以提升导入速度:
set foreign_key_checks=0; set unique_checks=0; set autocommit=off;
然后使用 source 将三个数据库都导入到数据库里面即可!
5. 修改 DB Server all 配置文件,告诉他我们需要同步哪些数据库:
replicate_do_db=A replicate_do_db=B replicate_do_db=C replicate_ignore_db=information_schema replicate_ignore_db=mysql replicate_ignore_db=performance_schema replicate_ignore_db=sys
此时就可以重启数据库,然后配置同步:
6. 在 DB Server all 上配置同步,这里以 A 为例:
CHANGE MASTER TO MASTER_HOST='192.168.x.x', MASTER_PORT=3306, MASTER_USER='xxx', MASTER_PASSWORD='xxxxxxxxx', MASTER_LOG_FILE='mysql-bin.0000xxx', MASTER_LOG_POS=xxxx FOR CHANNEL '100';
这里需要注意的是:
1. 注意之前备份文件中指针和 binlog 文件,这里需要用到。
2. 同步用户需要实现在所有从库都存在。
3. 最重要的就是最后的 CHANNEL 配置,不同的数据库必须使用不同的 CHANNEL,这样才能分开同步,不会同步失败。
7. 最终启动 slave:
start slave;
show slave statusG
可以看到这个库的同步状态!