
本文主要谈谈关于主机网络和容器网络的实现原理!
容器资源限制
在某些时候我们不想让容器肆无忌惮的抢占系统资源,所以就会对其做一系列的限制,这些参数可以使用蛮力查看到:
docker container run --help
主要的限制参数包含以下这些:
--cpu-shares:CPU 使用占比,如一个容器配置 10,一个配置 20,另外一个配置 10,那就是资源分配:1:2:1。
--memory:限制内存,比如配置 200M,但是如果不配置 swap,则实际内存其实是 400M。
--memory-swap:限制 swap,结合内存限制使用。
虚拟机网络名称空间(选择性了解)
docker 网络隔离的实现方式其实就是网络名称空间的方式,但是这方面的知识其实对于就算是运维工程师也不一定有详细的了解,所以这部分内容作为选择性了解。简单的对其实现方式说明,然后看看效果是怎样的。
1. 建立两个网络名称空间:
# 查看现有的网络名称空间 ip netns ls # 新建两个网络名称空间 ip netns add net-ns-1 ip netns add net-ns-2 # 在两个网络名称空间中分别查看它的网卡信息 ip netns exec net-ns-1 ip a ip netns exec net-ns-2 ip a
结果如图:
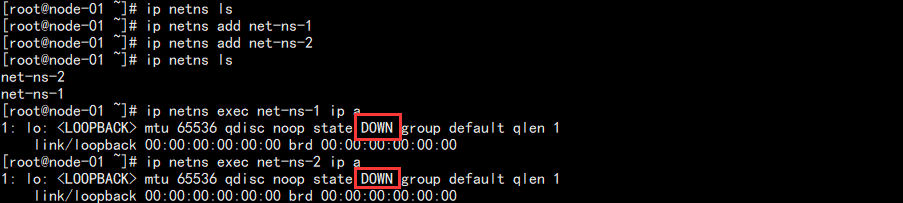
可以看到各自拥有一张回环网卡,并且未启动。我们可以将其启动起来再查看:
# 分别启动网络名称空间中的回环网卡 ip netns exec net-ns-1 ip link set dev lo up ip netns exec net-ns-2 ip link set dev lo up # 查看启动效果 ip netns exec net-ns-1 ip a ip netns exec net-ns-2 ip a
结果如图:
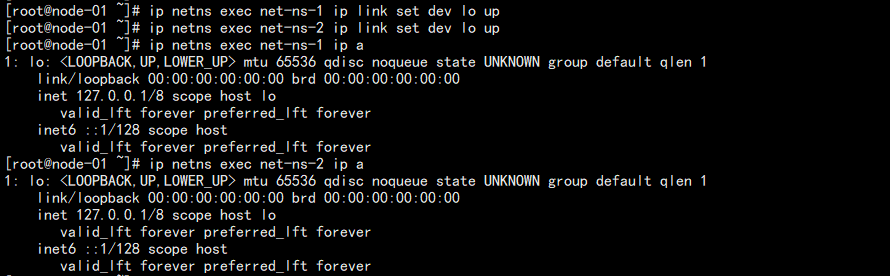
此时状态变成 UNKNOW,这就相当于一个机器,你至少一头差了网线,另外一端没有插线的状态。
2. 新建两个虚拟网卡,并把它们绑定到命名空间中:
# 新建两个网卡 ip link add veth-1 type veth peer name veth-2
结果如图:

将网卡分别分配到两个网络名称空间:
# 将网卡分别分配到指定的网络名称空间 ip link set veth-1 netns net-ns-1 ip link set veth-2 netns net-ns-2 # 查看当前虚拟机网卡信息 ip link # 查看指定网络名称空间的网卡信息 ip netns exec net-ns-1 ip link ip netns exec net-ns-2 ip link
结果如图:
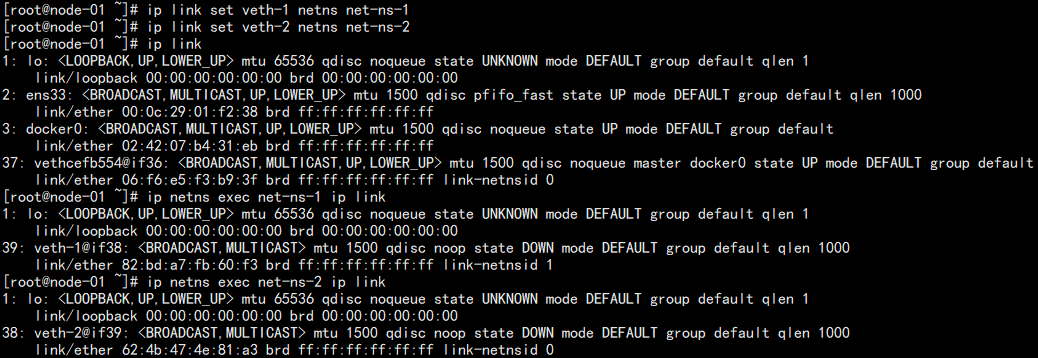
可以发现本机中已经不存在这两张网卡了,但是之前建立网络名称空间中可以看到他们。
这样的场景就类似于之前是一根网线的两头,我们把它拔了下来,一头插到了第一个网络名称空间的网口上,一头插到了另一个。
3. 给网口配置 IP 测试连通性:
# 配置 IP ip netns exec net-ns-1 ip addr add 192.168.1.1/24 dev veth-1 ip netns exec net-ns-2 ip addr add 192.168.1.2/24 dev veth-2 # 启动网卡 ip netns exec net-ns-1 ip link set dev veth-1 up ip netns exec net-ns-2 ip link set dev veth-2 up # 查看网卡信息 ip netns exec net-ns-1 ip a ip netns exec net-ns-2 ip a
结果如下:
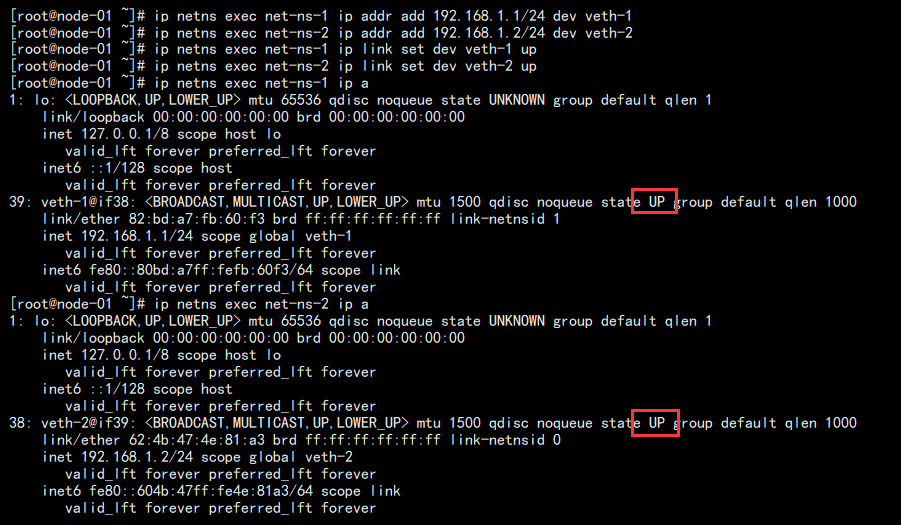
此时在网络名称空间之中测试网络连通性:
ip netns exec net-ns-1 ping 192.168.1.2
结果如图:

可以发现网络名空间之中因为两个网卡相当于连接通的了效果,但是和宿主机本身却是无法通信的。
这样就实现了 docker 的明明本机却能够做到网络隔离的效果。当然 docker 并非单单如此。
容器的网络原理
docker 的网络相较于上文的网络模式多了一个 docker0 网桥,我们可以将其当做交换机:

而且由于 iptables 的原因,容器内部还能够上网!
查看容器的网络:
docker network ls
结果如图:

熟悉 VMware 的人就应该很熟悉这些:
bridge:桥接网络,默认就是它,能够独立网段于宿主机本身网络,但是又能和宿主机所在的网络其它主机通信。
host:主机网络,这意味着容器和宿主机将会共享端口,同样的端口会导致端口冲突。
none:完全独立,无法通信。
因为这三种网络的关系,意味着本机通属于一个 bridge 的容器是可以互相通信的。可以自己建立一个桥接网络和两个容器测试:
docker network create -d bridge my-bridge
结果如图:

开两个窗口,分别新建容器并加入到这个网络:
# 窗口1 docker container run -it --name b3 --network my-bridge busybox /bin/sh # 窗口2 docker container run -it --name b4 --network my-bridge busybox /bin/sh
查看窗口1 IP:

查看窗口2 IP:

窗口1 测试通信:

窗口1 测试和宿主机通信:

可以发现能够和其它的宿主机通信!但是无法和其它宿主机的容器通信,很简单,因为他们是自己单独的 IP,不说其它,单单是他们两个就可能是一样的 IP 地址。
同时,我们新开窗口查看网卡情况:
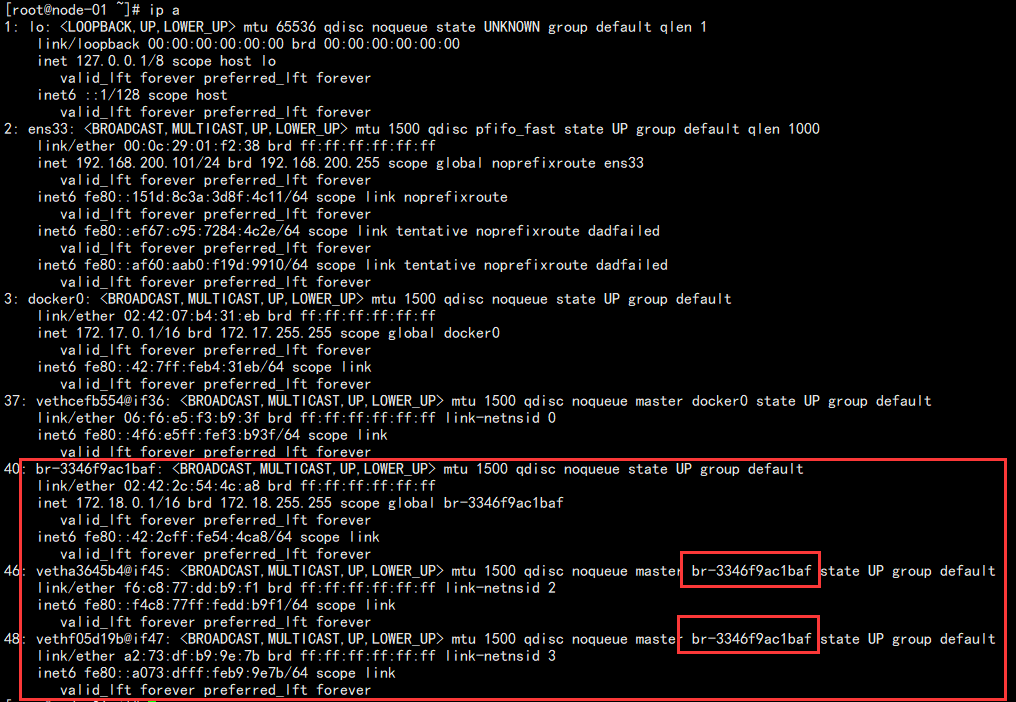
可以发现后面三个网卡其实就是类似于一个网络连接,后面两个都相当于一个网线,一头会连接到 br-xxx 上面,一头连接到容器中,所以它们能够通信。
这个 br-xxx 其实就是我们创建网络的时候出现的。至于如何和其它宿主机通信则是通过 iptables 的 nat 实现的。
查看网络详细信息:
docker network inspect my-bridge
结果如下:
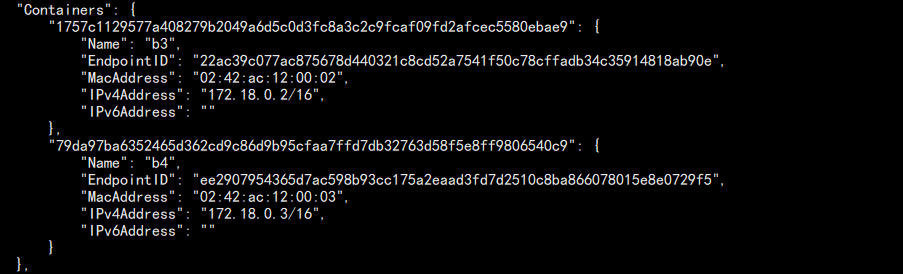
可以看到哪些容器属于该网络!
容器网络名称解析
由于容器的 IP 是随机的,所以在很多服务使用的时候我们不能再依赖容器的的 IP 来指望连接到指定的容器。
当然这并非不行,而是太麻烦而且不便于管理。那有没有更好的办法?有。
那就是我们在创建容器时会指定容器的名称,我们看他通过解析这个名称实现通信。
这里涉及到一个参数:--link,将一个容器连接到另外一个容器。
1. 新建两个容器,然后分别从新窗口进入容器测试网络通信:
# 创建容器 docker container run --name b1 -d busybox /bin/sh -c "while true;do sleep 3000;done" docker container run --name b2 -d busybox /bin/sh -c "while true;do sleep 3000;done" # 进入容器查看 IP 后测试网络 docker container exec -it b1 /bin/sh
结果如图:
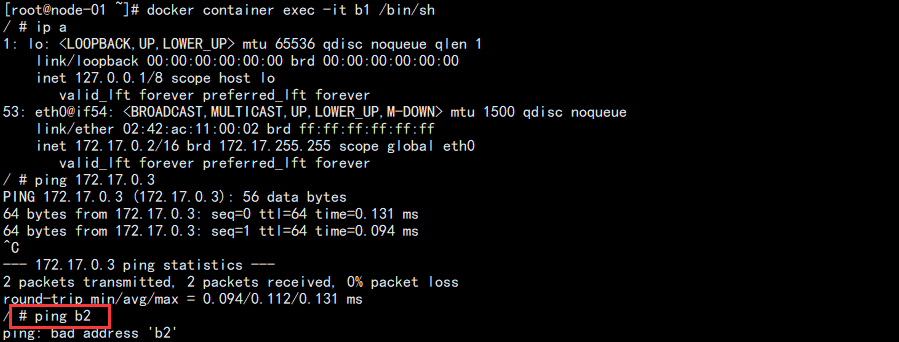
可以发现 ping IP 能够通信,但是 ping 容器名称不行。
2. 新建第三个容器,使用 link 绑定查看:
# 创建容器 docker container run --name b3 --link b1 -d busybox /bin/sh -c "while true;do sleep 3000;done" # 进入容器 docker container exec -it b3 /bin/sh
测试连通性如图:
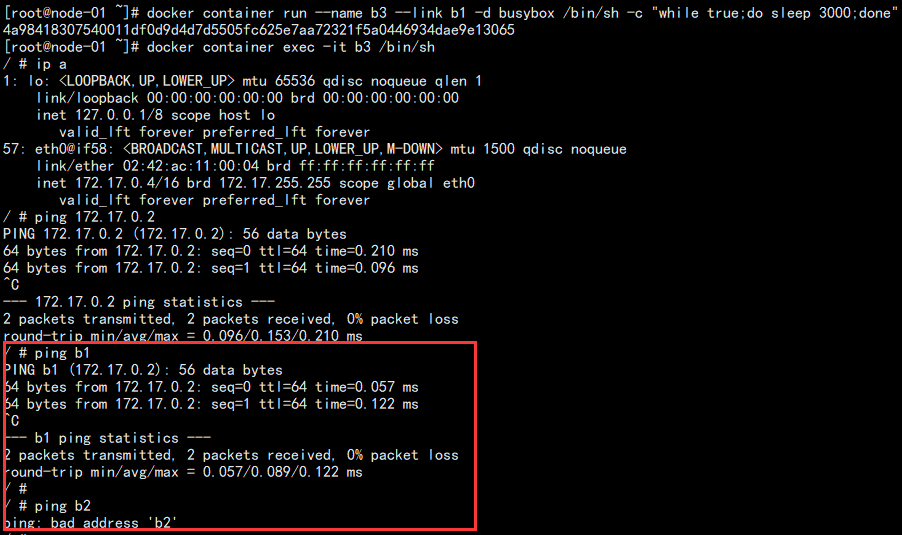
可以看到在 b3 中能够通过容器名称 ping 通 b1,但是无法 ping 通 b2。
3. 进入 b1 中测试和 b3 的连通性:
docker container exec -it b1 /bin/sh
结果如图:

无法通,由此可以得出一个结论:--link 在绑定的时候是单向解析的。
这样就解决了我们想要通过容器名称来实现服务之间的通信而不是依靠随时都可能改变的 IP 地址。
容器端口映射
将容器内部我们需要的某个端口映射到宿主机,这算是一种解决办法,因为宿主机的 IP 是固定的。
这里涉及到两个参数:
-p:将宿主机的某个端口映射到容器的某个端口。
-P:将容器的所有端口随机映射到宿主机的随机端口。
1. 为了便于理解,这里还是以之前的 Flask 项目为例,不过这里我们改一下代码,让其复杂一点。
mkdir flask-redis-demo cd flask-redis-demo/ vim app.py
内容如下:
from flask import Flask from redis import Redis import os import socket app = Flask(__name__) redis = Redis(host=os.environ.get('REDIS_HOST', "127.0.0.1"), port=6379) @app.route("/") def hello(): redis.incr('hits') return 'Redis hits: %s, Hostname: %s' % (redis.get('hits'), socket.gethostname()) if __name__ == "__main__": app.run(host="0.0.0.0", port=5000, debug=True)
其实就是 flask 通过用户传递过来的变量找到 redis 的地址连接上去,然后获取到 redis 的 hits 打印出来。
这就涉及到跨容器通信!
2. 编写 Dockerfile:
FROM python:2.7 LABEL author="Dylan" mail="1214966109@qq.com" RUN pip install flask && pip install redis COPY app.py /app/ WORKDIR /app/ EXPOSE 5000 CMD ["python", "app.py"]
制作成为镜像:
docker image build -t dylan/flask-redis-demo .
3. 先运行一个 redis 容器:
docker container run -d --name redis-demo redis
结果如图:

4. 此时运行 flask 容器并连接到 redis-demo 容器:
docker container run -d --name flask-redis-demo --link redis-demo -e REDIS_HOST="redis-demo" dylan/flask-redis-demo
这里有个新增的参数:-e 传递变量给容器,结果如图:

此时我们在容器中访问测试:
docker container exec -it flask-redis-demo curl 127.0.0.1:5000
输入如下:
Redis hits: 1, Hostname: 0a4f4560fa72
可以看到容器内部是正常的,并且 flask 容器可以去 redis 容器中获取值。但是问题还是在于该地址只能容器内部访问。
5. 新建容器,将端口随机映射出来:
docker container run -d --name flask-redis-demo-1 -P --link redis-demo -e REDIS_HOST="redis-demo" dylan/flask-redis-demo
结果如图:

可以看到宿主机的 1025 端口映射到了容器内部的 5000 端口,此时我们访问本机 1025 端口测试:
curl 192.168.200.101:1025
结果如图:

6. 新建容器,将容器端口映射到 8000 端口:
docker container run -d --name flask-redis-demo-2 --link redis-demo -e REDIS_HOST="redis-demo" -p 8000:5000 dylan/flask-redis-demo
结果如图:

访问测试:

至此,端口映射完成!
跨主机通信
虽然端口映射能够解决我们一定量的问题,但是在面对某些复杂的情况的时候也会很麻烦。比如跨主机通信。
这就不是 link 能够解决的问题,需要将所有用到的服务的端口都映射到宿主机才能完成操作!
那有没有办法将多个主机的容器做成类似于一个集群的样子?这就是涉及容器的跨主机通信问题。
这一次我们会用到两个虚拟机,192.168.200.101 和 102,都安装好 docker。
在实现这个功能之前,我们需要了解到两个东西:
overlay 网络:相当于在两个机器上面建立通信隧道,让两个 docker 感觉运行在一个机器上。
etcd:基于 zookeeper 的一个共享配置的 KV 存储系统。其中 etcd 地址如下:
https://github.com/etcd-io/etcd/tags
在使用之前需要注意:
1. 服务器的主机名最好具有一定的意义,最简单也要坐到唯一,同样的主机名可能出现 BUG。
2. 确认关闭防火墙这些东西。
3. 能有 epel 源最好。
yum -y install epel-release
我在安装的时候,epel 源中最新的 etcd 版本为:3.3.11-2
1. 在 101 上面安装 etcd 并配置:
yum -y install etcd cd /etc/etcd/ cp etcd.conf etcd.conf_bak vim etcd.conf
内容如下:
#[Member] ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380" ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379,http://0.0.0.0:4001" ETCD_NAME="docker-node-01" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.200.101:2380" ETCD_ADVERTISE_CLIENT_URLS="http://192.168.200.101:2379,http://192.168.200.101:4001" ETCD_INITIAL_CLUSTER="docker-node-01=http://192.168.200.101:2380,docker-node-02=http://192.168.200.102:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new"
注意红色的地方,名称保持一致。
同理在 102 上面也进行类似的配置:
#[Member] ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380" ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379,http://0.0.0.0:4001" ETCD_NAME="docker-node-02" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.200.102:2380" ETCD_ADVERTISE_CLIENT_URLS="http://192.168.200.102:2379,http://192.168.200.102:4001" ETCD_INITIAL_CLUSTER="docker-node-01=http://192.168.200.101:2380,docker-node-02=http://192.168.200.102:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new"
注意修改 IP 地址即可。
| 关键字 | 说明 |
|---|---|
| ETCD_DATA_DIR | 数据存储目录 |
| ETCD_LISTEN_PEER_URLS | 与其他节点通信时的监听地址列表,通信协议可以是http、https |
| ETCD_LISTEN_CLIENT_URLS | 与客户端通信时的监听地址列表 |
| ETCD_NAME | 节点名称,在也就是后面配置的那个 名字=地址 |
| ETCD_INITIAL_ADVERTISE_PEER_URLS | 节点在整个集群中的通信地址列表,可以理解为能与外部通信的ip端口 |
| ETCD_ADVERTISE_CLIENT_URLS | 告知集群中其他成员自己名下的客户端的地址列表 |
| ETCD_INITIAL_CLUSTER | 集群内所有成员的地址,这就是为什么称之为静态发现,因为所有成员的地址都必须配置 |
| ETCD_INITIAL_CLUSTER_TOKEN | 初始化集群口令,用于标识不同集群 |
| ETCD_INITIAL_CLUSTER_STATE | 初始化集群状态,new表示新建 |
2. 启动服务:
systemctl start etcd systemctl enable etcd # 查看节点 etcdctl member list # 监控检查 etcdctl cluster-health
结果如图:

可以看到集群处于健康状态!
3. 此时修改 101 的 docker 启动配置:
# 停止 docker systemctl stop docker # 修改配置 vim /etc/systemd/system/docker.service
修改内容如下:
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --registry-mirror=https://jxus37ad.mirror.aliyuncs.com -H tcp://0.0.0.0:2375 --cluster-store=etcd://192.168.200.101:2379 --cluster-advertise=192.168.200.101:2375
主要增加了红色部分,然后启动 docker:
systemctl daemon-reload
systemctl start docker
同理 102 也进行修改,注意 IP 地址:
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --registry-mirror=https://jxus37ad.mirror.aliyuncs.com -H tcp://0.0.0.0:2375 --cluster-store=etcd://192.168.200.102:2379 --cluster-advertise=192.168.200.102:2375
同样重启 docker,此时的 docker 进程发生了改变:
ps -ef | grep docker
结果如下:

4. 此时在 101 上创建 overlay 网络:
docker network create -d overlay my-overlay
结果如下:

此时查看 102 网络:

已经同步过来了,如果没有同步成功,可以重新关闭 102 的防火墙,重启 102 的 docker 再看。
5. 此时在 101 和 102 上面分别创建容器然后测试网络的连通性:
# 101 上面创建 docker container run -d --name b1 --network my-overlay busybox /bin/sh -c "while true;do sleep 3000;done" # 102 上面创建 docker container run -d --name b2 --network my-overlay busybox /bin/sh -c "while true;do sleep 3000;done"
注意这里新的参数:--network,指定容器的网络,不再是默认的 bridge 网络。
docker container exec -it b1 ping b2
直接在 b1 上面 ping b2:

发现已经能够实现正常的通信了。而且不再需要我们指定 link 参数了。
当然 etcd 也有它的缺点,它是静态发现,意味着我们增加节点就需要增加配置和重启 etcd。