Coding Tree Depth Estimation for Complexity Reduction of HEVC
《HEVC标准介绍、HEVC帧间预测论文笔记》系列博客,目录见:http://www.cnblogs.com/DwyaneTalk/p/5711333.html![Motion Vectors Merging Low Complexity Prediction Unit Decision Heuristic for the InterPrediction of HEVC Encoders.pdf]()
2013 Data Compress Conference
核心思想:
在P1.8论文(将frame分为Fu和Fc,对于Fc帧中CTU的最大深度进行限定,最大深度的值根据Fu帧对应位置的CTU的深度得到)的基础上继续优化,采用改进的策略(根据码率、目标计算复杂度和预测计算复杂度)更新Nc的值,采用更复杂有效的策略(时域+空域选择CTU深度)确定Fc帧中CTU的最大深度。
本论文改进的目的是:在P1.8中,由于仅仅通过时域信息限制Fc帧中CTU的深度来控制计算复杂度,这就导致当目标计算复杂度较小时(如60%),编码的率失真性能不是很好,所以通过新的策略放宽Fc帧中CTU最大深度的限制,通过降低Nc的最大值限制(最大为FR/2,使得更早按照max_depth_allowed-1进行CTU编码)。
思路分析:参见P1.8。
算法介绍:
总体思想:如下图(和P1.8类似)
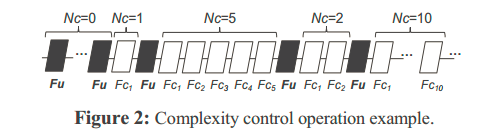
与P1.8的不同之处在于,该算法中在视频序列的开始部分,会有连续M帧全部是Fu帧,M的值最小为5。而且,在视频序列中,如果出现预测计算复杂度小于目标计算复杂度,就会编码5个连续的Fu帧,然后重新估计目标复杂度和预测复杂度。
具体步骤:


变量含义:
Fu:unconstrained frame,无限制帧,按照标准流程编码;Fc:constrained frame,限制帧,最大的CTU深度有限制,是编码的加速帧。
EMC:估计最大编码计算复杂度,相当于不进行任何加速、限制情况下的编码复杂度;
ETC:目标编码计算复杂度,可以根据用户定义、设备CPU资源、电池电量等进行判定,相当于论文中的60%、80%;
PC:预测当前编码进行下,所有帧都编码完成时,所需要的编码复杂度;
MTDM^k和MTDM^k-1:分别记录当前帧中已编码CTU和前一帧中所有CTU的实际编码深度;
CMTDM:记录了根据时域运动补偿,得到的当前帧在前一帧中运动补偿CTU的实际编码深度;
max_depth_allowed:实际一个CTU的最大编码深度。
Nc和frame rate如P1.8。
左边展示了算法的整体流程,右边展示了算法编码一帧的流程。整体流程包括:
S1、连续编码5帧Fu帧;
S2、计算EMC、ETC和PC的值;
S3、如果PC<ETC,跳到S1,否则继续;
S4、调整Nc的值,编码一个Fu帧;
S5、连续编码Nc个Fc帧,每编码一帧后,更新DMTCM矩阵;
S6、从新计算PC,并返回到S3。
编码一帧流程,包括编码一帧内的每个CTU,对于编码一个CTU(i,j位置处),流程包括:
S1、如果是Fu帧:按照标准流程编码;否则:max_depth_allowed=max{MTDM^k(i-1,j),MTDM^k(i,j-1),MTDM^k(i-1,j-1),MTDM^k-1(i,j),CMTDM^k(i,j)}//分别为当前CTU当前帧左、上、左上CTU的实际深度,前一帧对应位置CTU实际深度和运动补偿估计得到的深度;
S2、根据max_depth_allowed编码一个CTU,并将实际编码深度存储到MTDM(i,j)中;
S3、所有CTU编码完成后,更新MTDM^k和MTDM^k-1。
相关变量计算:
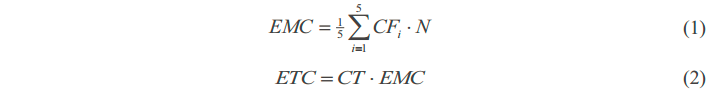
如上公式:计算EMC和MTC时,CFi是连续5帧Fu帧中第i帧的计算复杂度,N是视频序列中的帧数,CT是目标计算复杂度的比例。
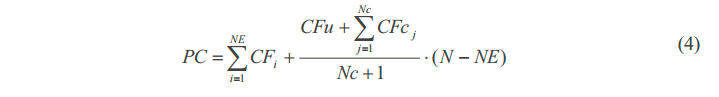
如上公式:计算估计计算复杂度时,根据刚刚编码的Nc帧FC帧和一帧Fu帧,按照线性关系估计所有帧编码完成需要的计算复杂度,其中NE是当前已编码完成的帧,CFi是所有已编码的帧中第i帧的计算复杂度。
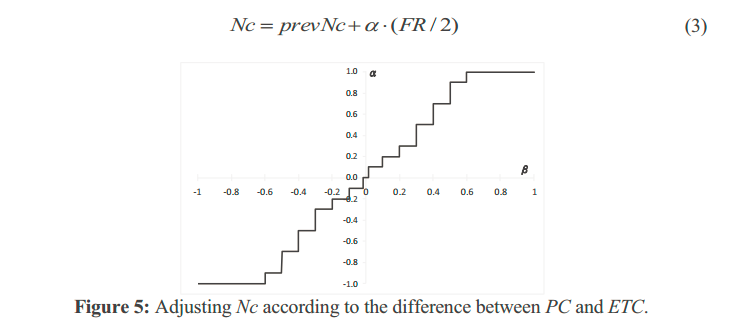
如上公式:更新Nc值时,通过差值调整的策略,alpha是beta的函数,二者关系有上面梯度折线确定,beta = (ETC-PC)/ETC。
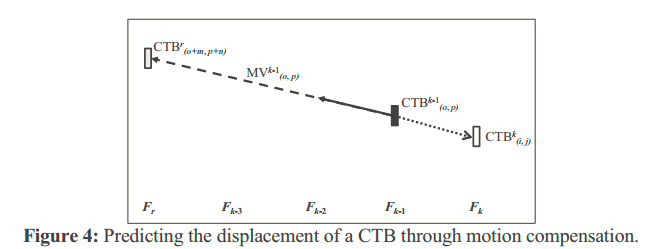
如上,展示了CMTDM的预测过程,假设图像CTU区域块运动恒定,编码k-1帧Fk-1时,CTU^k-1(o,p)的最大PU(也就是CTU)划分对应的运动矢量为MV^k-1(o,p),对应参考块为参考帧Fr中的CTU^r(o+m,p+n),所以:MV^k-1(o,p)=(m,n)。
在假设CTU运动恒定条件下,可以判断CTU^k-1(o,p)在Fk-2中的对应块为CTU^r(o+m1,p+n1),其中(m1,n1)=(m,n)/r,同样可以判断CTU^k-1(o,p)在Fk中的对应块为CTU^r(o-m1,p-n1)。假设(o-m1,p-n1)=(i,j),那么记录CMTDM^k(i,j)为CTU^k-1(o,p)的实际编码深度。
实验展示:
实验条件:HM8.2,Low Delay, VTune Amplifier XE2011 software profiler进行计算复杂度检测,6个不同实验序列,60%~100%共5个目标复杂度。
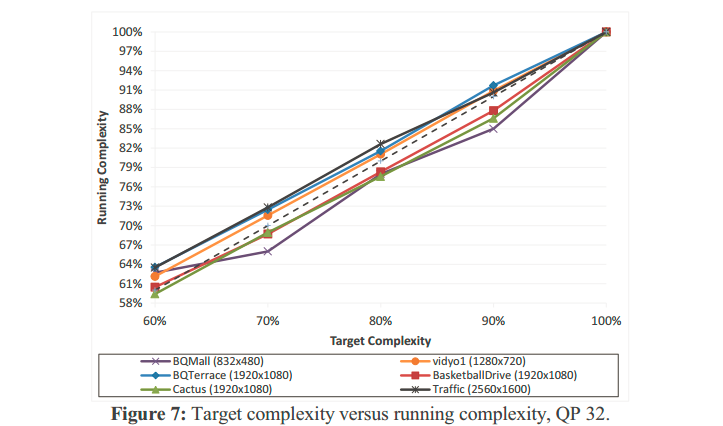
上图展示了,算法在控制目标计算复杂度的性能。如图展示,可以看出对于6个序列,目标计算复杂度(虚线)和实际运行的计算复杂度(6条实线)差距不大。
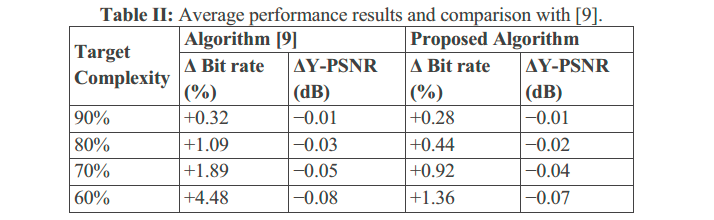
上表展示的是算法在保证控制实际运行计算复杂度的前提下,编码的码率和PSNR性能。