寒假作业2/2
| 这个作业属于哪个课程 | 2021春软件工程实践|W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 阅读构建之法,完成wordCount程序,撰写博客 |
| 其它参考文献 | 估计时间,执行力 |
| GitHub项目地址 | https://github.com/czj6/PersonalProject-Java.git |
阅读构建之法并提问
-
书中第三章 3.3技能的反面这里提到
那怎么提高技能呢?答案很简单,通过不断地练习,把那些低层次的问题都解决了,变成不用大脑的自动操作,然后才有时间和脑力来解决较高层次的问题。
我有个提问:低层次和较高层次的分界在哪,感觉底层次的问题不单单是指语言的基本语法使用。我去网上找了下博客,如下:
低层次:序列,条件语句和循环;
中间水平:函数,对象和递归; 高层次:模块设计,设计模式,创建API程序; 高层次优化:订单的复杂性和算法优化
这篇博客是08年的,感觉年代有点久远,所以答案我觉得现在已经变了。我觉得低层次应该是语法api的基本使用,框架的基础应用(不包括源码解读),算法的了解,设计模式等等。
-
书本的第16章 16.1 创新的迷思这里
杰弗里.尼科尔森认为“科研是将知识转换为金钱的过程“,”而创新则是将知识转换为金钱的过程“
我不认同这种说法,我认为它们并不是单方向的转换,科研既是将知识转换成金钱,又是将金钱转换成知识。科学家投入了大量的时间金钱钻研出了新产品,可以将新产品卖出去又变现了金钱,所以我认为它们是互通的。
-
书本的第八章需求分析 8.6计划和估计这里
估计:以当前了解的情况和掌握的资源,要花费多少人力物力时间才能实现某事。
我觉得在编程时,我们可能会遇到遗忘的知识点或者空白的知识点,需要我们停下学习。还可能出现bug,需要我们排查bug,排查bug的时间无确定性,所以估计如何才能做到有参考意义上的估计呢?
我上网查了资料:
尽管进行了精确估算,也不能保证每个项目都会100%精确。偶尔会遇到一些突发情况和没预估到的风险是不可避免的。那么面对风险,有一些原则可以帮助你:
- 报风险时间置前,如果开发开始或者任何过程有可能导致项目延期或者需求无法实现的时候就报警,不要等加班能实现或者存在侥幸心理;
- 对于不确定的需求,一定要沟通到位;
- 涉及到交互细节,必须提前沟通好,充分明确细节;
- 技术可行性方案提前调查清楚。
估计不是绝对精确的,但是它具有很大的概率性,对我们程序员开发具有很大的帮助。
-
书本16.1 创新的迷思这里
假设你发明了电报,创办了电报公司,并花费毕生精力建起了覆盖全国的点报网。这时有个年轻的发明家上门推销他的创新——电话
电报创新者可能会讨厌电话这个创新。就好比电商夺走实体店的一部分市场资源一样,一个创新的诞生总是伴随着一部分人的反对与赞同。
-
书中 16.3创新的招数这里
执行力的一个有效衡量标准是一个决定需要多少次会议才能达成的
那怎样才有有效提高执行力呢?在知乎上,有人这么回答
通过“tita项目管理”计划功能安排任务,可将具体工作指定到责任人和参与人,且有明确的完成截止时间。如接受工作任务人员无法在截止日期前完成任务,可及时和领导反馈信息,方便领导进行下一步工作部署。领导在系统里可查看到自己安排过的任务,而且系统任务功能督促员工及时完成任务及反馈工作情况,调动了员工的工作积极能动性。这样,系统明确告诉员工“该做什么”和“如何协同大家克服困难完成任务”。
冷知识和故事
有次里奇演讲,演讲过后一个学生问道:丹尼斯先生,你认为一个人从学习C到熟悉C,并能写出有价值的代码,大约需要多长时间?
里奇:我怎么会知道,我又没学过C。
WordCount
项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 4(day) | 6(day) |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 45 | 90 |
| • Design Spec | • 生成设计文档 | 15 | 15 |
| • Design Review | • 设计复审 | 15 | 15 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 5 | 10 |
| • Design | • 具体设计 | 60 | 120 |
| • Coding | • 具体编码 | 240 | 360 |
| • Code Review | • 代码复审 | 20 | 15 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 20 | 20 |
| • Size Measurement | • 计算工作量 | 10 | 15 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 15 | 20 |
| 合计 | 505 | 770 |
解题思路
拿到题目后,首先输入和输出文件由命令行传入,需要用process.argv[]来获取,读取文件和写入文件操作可以用nodejs的fs模块。进行统计单词,需要用到正则表达式去匹配,按照题目要求分为以下几个函数模块:
- 统计文件字符数
- 统计单词总数
- 统计文件有效行数
- 统计文件中单词出现次数
代码规范链接
设计与实现
总体思路为,如下图:
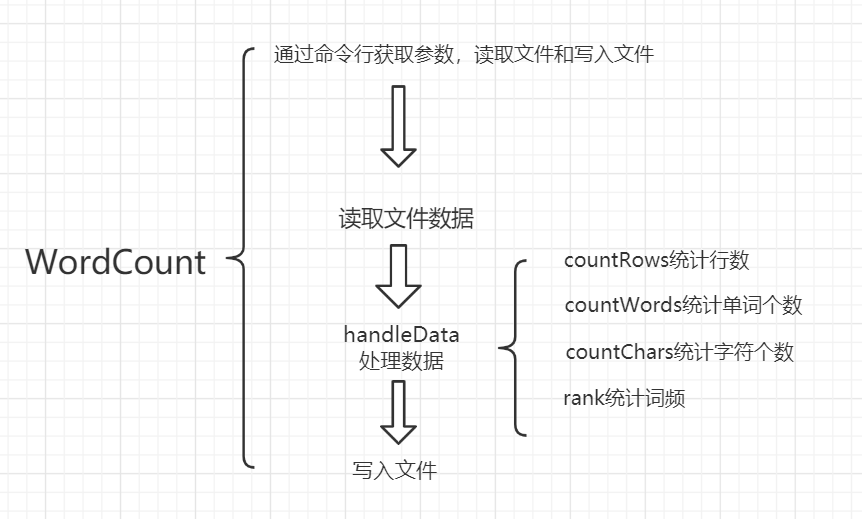
首先是要设计正则表达式
module.exports = {
reg: {
han: /[u4e00-u9fa5]+/, // 匹配汉字的正则
symbol: /
/g, // 匹配换行符
asciiRex: /[x00-xff]+/, // 匹配ascii码
wordRex: /[a-zA-Z]{4}([a-zA-Z0-9])*/, // 匹配单词
wordSplit: /[^A-Za-z0-9]+/, // 切割单词
},
};
我把正则表达式单独抽离在一个config.js配置文件,以便于后序进行修改。
然后在设计一个异常类,判断是否是输入命令异常,还是资源未找到异常。
-
读取文件用
fs.readFileSync(this.readFile, { encoding: 'utf8' }) -
countRows
function countRows(data) { const arr = data.split(symbol); let lines = 0; for (let i = 0; i < arr.length; i++) { if (arr[i].trim()) { lines += 1; } } return lines; }通过正则匹配生成一个数组,然后遍历计算行数。
-
countChars
function countCharNum(arr, restCount) { return arr.length - restCount; }这个方法是统计字符个数,restCount是非
ascii码的个数,因为题目要求统计的是ascii个数。 -
countWords
function countWord(arr) { const res = arr.join('').toLocaleLowerCase(); const data = res.split(wordSplit); const str = data.filter((item) => { let bool = wordRex.test(item); return bool; }); return { words: str.length, table: str, }; }单词先转成小写,然后再通过正则分割单词,分割完再进行过滤匹配是否符合我们的单词要求。
-
rank
function rank(arr, num) { const obj = { }; arr.sort(); // .... function compare(a, b) { const key1 = Object.keys(a)[0]; const key2 = Object.keys(b)[0]; return b[key2] - a[key1]; } data.sort(compare); let dataMsg = {}; for (let i = 0; i < num; i += 1) { dataMsg = { ...dataMsg, ...data[i] }; } return dataMsg; }我在想
nodejs中对象本身就是map的数据结构,所以就用对象来存储统计,key为单词本身,value是单词出现的次数。然后再将该对象转成数组,最后进行sort排序,输出结果
性能改进
性能改进前,处理1000w个字符,需要6000多ms

性能改进后,处理1000w个字符,需要3000多ms

解决方法:
nodejs是单线程的,所以我觉得在IO读取占用大量时间,所以我去官方找了下资料,采用了流的读取这方式,所以我将上面的方法移到v1文件夹,表示为第一版本,改进后的版本我写在v2这文件夹 ,两个版本的主要区别是IO读取不同。关键代码如下:
const readable = fs.createReadStream(readFile);
readable.on('data', (chunk) => {
characters += countChar(chunk); //统计字符
lines += countRows(chunk); // 统计行数
let table = countWords(chunk);
arr = [...arr, ...table];
words += table.length; // 统计单词
wordMap = classArr(table, wordMap);
});
readable.once('close', () => {
rankObj = rank(wordMap, 10); // 排行
let data = {
characters,
words,
lines,
...rankObj,
};
writeToFile(data, writeFile);
console.timeEnd('test');
});
这次并不是一次性读取文件,而是用流的方式读取,先读取一段chunk进行处理。
单元测试
项目采用的是jest插件进行单元测试,测试得代码放在test文件夹里面,部分代码如下
const countWords = require('../../src/lib/v2/countWords');
test('测试单词个数',() => {
let obj = `abcd,aaaa.
abcd.sdfgsfg`
expect(countWords(obj).length).toBe(4)
})
const {countChar} = require('../../src/lib/v2/countChar');
// 测试计算换行符
test('测试字符个数',() => {
let obj1 = `abcd,
hello`
expect(countChar(obj1)).toBe(11)
})
// 测试计算空格
test('测试字符个数',() => {
let obj1 = `abcd, hello`
expect(countChar(obj1)).toBe(11)
})
自动化测试npm run test执行jest单元测试,然后生成覆盖率图(包含v1和v2两个版本)
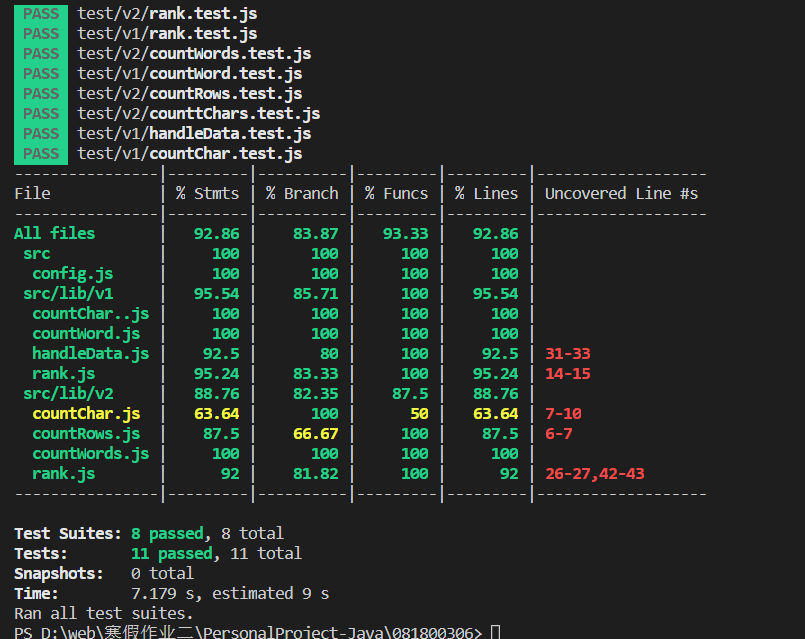
异常处理
单独写一个exception.js异常类
class Exception extends Error {
constructor(msg = '出现了异常', status = 500) {
super();
this.msg = msg;
this.status = status;
}
}
// ...
class ParamException extends Exception {
constructor(msg = '参数错误', status = 400) {
super();
this.msg = msg;
this.status = status;
}
}
到时使用时只需抛出一个异常类的实例就行。NOtFindException类主要是比如readFile文件未找到,就会抛出一个资源未找到异常。ParamException主要是比如命令行敲命令少了一个参数,就会抛出参数错误异常。
异常处理的测试单元代码
const { NotFindException } = require('../../src/exception');
function compileAndroidCode() {
throw new NotFindException('资源未找到');
}
test('compiling android goes as expected', () => {
expect(() => compileAndroidCode()).toThrow(NotFindException);
});
心路历程与收获
通过这次项目,我对nodejs的流更加的了解,还有学会了基础了jest单元测试,对正则有更深的印象。
不足:我知道sort对性能消耗比较大,但是不知道怎么去改进,存在欠缺。。