1、字符编码
字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
- Unicode下一个中文字符和英文字符都占两字节。
- UTF-8下一个中文占三个字节(绝大多数的情况,偏僻中文字符的占四个),英文占一个字节。
- GBK下一个中文占两个字节,英文占一个字节。
- 1980 GB2312 ,支持七千多汉字;1995 GBK1.0,支持两万多汉字;2000 GB18030 两万七千多汉字。
- Python2中如果要使用汉字,需要先定义字符编码:# -*- coding:utf-8 -*- (中横线和下划线皆可)。
以下内容摘抄自廖雪峰:
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。(我的理解是Unicode只是在内存中的存在形式,存入文件或者在网络中发送时需要再进行编码。例如存文件需要编译成UTF-8、GBK等,在网络中发送需要编译成bytes。)
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。当字符在ASCII码的范围时,就用一个字节表示,所以是兼容ASCII编码的。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
1.1 Bytes数据类型
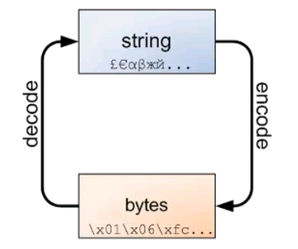
#字符串转bytes
>>>msg = "北京"
>>>print(msg.encode("utf-8")) #如果不指定字符编码,默认使用utf-8
b'xe5x8cx97xe4xbaxac'
#bytes转字符串
>>>b'xe5x8cx97xe4xbaxac'.decode("utf-8")
'北京'
1.2 字符编码和解码
- 在python2默认编码是ASCII, python3里默认是unicode(utf-8)。
- unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间。
- 在python3中encode在转码的同时还会把string变成bytes类型,decode在解码的同时还会把bytes变回string。
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
1 >>> "abc" 2 'abc' 3 >>> print(type("abc")) 4 <class 'str'> # str类型 5 6 >>> "abc".encode("utf-8") # 以unicode表示的str经过encode()后变为bytes类型 7 b'abc' 8 >>> print(type("abc".encode("utf-8"))) 9 <class 'bytes'> # bytes类型 10 11 >>> "阿波呲".encode("utf-8") 12 b'xe9x98xbfxe6xb3xa2xe5x91xb2' 13 >>> print(type("阿波呲".encode("utf-8"))) 14 <class 'bytes'> # bytes类型 15 16 17 >>> b'abc'.decode() # bytes类型经过decode()后变为str类型 18 'abc' 19 >>> print(type(b'abc'.decode())) 20 <class 'str'> # str类型 21 22 >>> b'xe9x98xbfxe6xb3xa2xe5x91xb2'.decode() # bytes类型经过decode()后变为str类型 23 '阿波呲' 24 >> print(type(b'xe9x98xbfxe6xb3xa2xe5x91xb2'.decode())) 25 <class 'str'> # str类型
字符编码和解码及转化关系如下图所示:
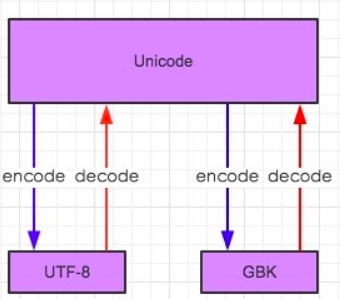
python2中的转码:
1 # -*- coding=utf-8 -*- #此处意思仅是声明文件编码,而不能改变程序编码 2 import sys 3 4 print(sys.getdefaultencoding()) #ascii 6 s = "你好" #这里编码仍然为ascii 7 8 s_to_unicode = s.decode("utf-8") #将utf-8解码为unicode。decode后面的'utf-8'参数意思是现在使用的是utf-8编码。 9 print(s_to_unicode) 10 11 unicode_to_gbk = s_to_unicode.encode('gbk') #将unicode编码为gbk。encode后面的'gbk'编码意思是转换为gbk编码。 12 print(unicode_to_gbk)
python3中的转码:
1 #-*-coding:gbk-*- #作用仅为声明文件编码。编译器的编码也要和这个对应,否则报错。 2 import sys 3 4 print(sys.getdefaultencoding()) #utf-8 5 6 msg = "陈 ABCD" 7 8 msg_to_gbk = msg.encode("gbk") #默认就是unicode,不用先encode,和python2不一样 9 print(msg_to_gbk) #b'xb3xc2 ABCD' 10 11 gbk_to_unicode = msg_to_gbk.decode("gbk") 12 print(gbk_to_unicode) #陈 ABCD 13 14 gbk_to_utf8 = msg_to_gbk.decode("gbk").encode("utf-8") 15 print(gbk_to_utf8) #b'xe9x99x88 ABCD'
关于UTF-8下一个中文占三个字节,英文占一个字节,GBK下一个中文占两个字节,英文占一个字节:
1 >>> a = "字节" 2 >>> type(a) 3 <class 'str'> # 字符串类型 4 >>> len(a) # 编译前长度为2 5 2 6 7 >>> type(a.encode("utf-8")) 8 <class 'bytes'> # 字节 9 >>> len(a.encode("utf-8")) # 编译为UTF-8后长度变为6 10 6 11 >>> type(a.encode("gbk")) 12 <class 'bytes'> 13 >>> len(a.encode("gbk")) # 编译为GBK后长度变为4 14 4 15 16 >>> b = "zifu" 17 >>> type(b) 18 <class 'str'> 19 >>> len(b) # 编译前长度为4 20 4 21 22 >>> type(b.encode("utf-8")) 23 <class 'bytes'> 24 >>> len(b.encode("utf-8")) # 编译为UTF-8后仍然为4 25 4 26 >>> len(b.encode("gbk")) # 编译为GBK后仍然为4 27 4