昨天老师安排了一场考试,我分配到的题目是 “http://zhinengdayi.com/hbnu爬取院系专业中的专业简介”。
进入网站后,我找到了专业简介介绍
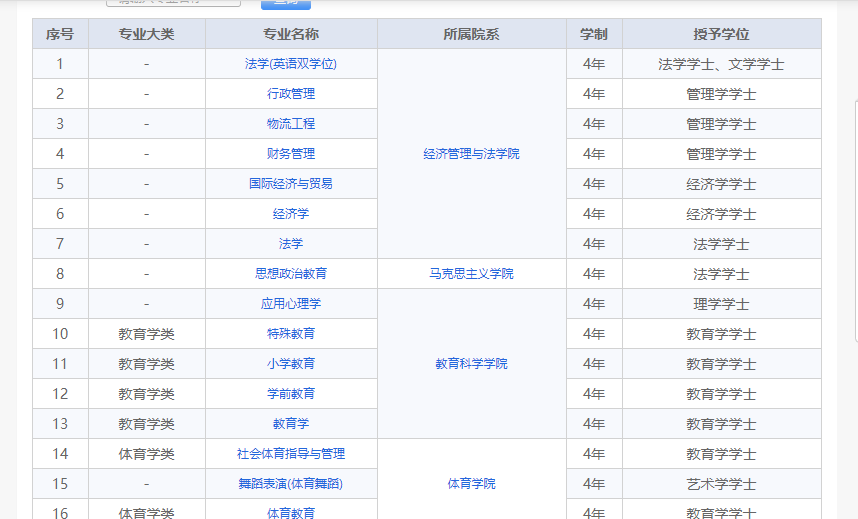
通过肉眼观察我发现,我所需爬取的内容是一个网页表格,检查发现果然如此
思路:当时我看到这个题目立马想到书上有个例题,是爬取中国最好大学排行榜,它也是一个网页表格。
# 导入所需的库 import requests from bs4 import BeautifulSoup # 解决乱码问题 import io import sys sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') # 请求 r=requests.get("http://zhinengdayi.com/page/detail/LSPJPH/489/1040") result=r.text # 解析html源码 soup=BeautifulSoup(result,'html.parser') name=soup.find_all('th') com=soup.find_all('tr') # 将数据导入CSV文件 fr=open("jianjie.csv","a") li=[] for i in name: li.append(i.text) fr.write(",".join(li)+" ") for tr in com: ltd=tr.find_all('td') if len(ltd)==0: continue li1=[] for td in ltd: li1.append(td.text) fr.write(",".join(li1)+" ") fr.close()
上述代码是我根据题目要求所编写的源码,重点在将数据导入CSV文件。
fr=open("jianjie.csv","a")
这行代码是以a读写文件,即没有该文件就创建,有则打开文件并在其后添加列表。
fr.write(",".join(li)+" "
将列表数据写入CSV文件,以逗号为分隔符,加入后换行。
最后,fr.close()关闭文件。
以下是运行结果:

2019-11-23 14:56:01