再一次向YYF大神致敬。
但有一个叫YYF的大神(它说自己是蒟蒻)叫我附上转载地址:http://www.cnblogs.com/yyf0309/p/6853425.html
[导读]
相信来看的读者一定知道在stdlib.h中的rand(),开始觉得它是一个很神奇的东西,绞尽脑汁都想不出它是如何做到的,于是查了下资料知道了如下几点
- Windows随机函数产生的随机数不是真正意义下的随机数,而是通过一个随机数种子,然后一些公式,不断地得到下一个"随机数",然后将种子改成这个随机数,然后再不断这样继续。
- 通过单纯的编程很难得到一个真正的随机函数,UNIX系统下一个随机函数是通过硬件的信息(例如硬件发出的噪音)等等来得到的随机数。
所以经常会出现这样的情况
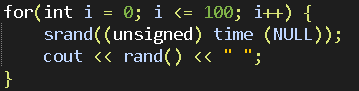
然后得到这样的可怕的"随机数"
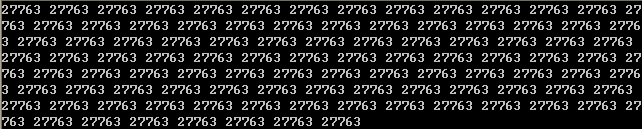
显然for循环的速度比操作系统时钟中断(至少有个10ms,你应该知道,光标的闪烁等等都需要依赖于操作系统的时钟中断的计时)一次快很多,所以每次的seed是一样的,公式也没有变,所以生成出来的随机数也没有变。
[小介绍]
如果你知道rand()和srand(unsigned int)两个函数就可以跳过这一段了。
| 函数原型 | 作用 |
|---|---|
| int __cdecl rand(void) | 返回一个值在0~RANDMAX之间的整数 |
| void __cdecl srand(unsigned int _Seed) | 重置随机数种子 |
你也注意到了rand()返回的值不是任意一个整型,至少它返回的最大值是RAND_MAX(多数机子上是32767)等等。那么如何得到一个1 ~ 20之间的一个数,有如下三种方法
- 一直rand(),直到出现一个符合条件的数。显然它是等概率的。如果我要生成一组100000个数的数组,显然它太慢了。
- 用(double)rand() / RAND_MAX得到一个在[0, 1]之间的数,然后再乘20取整再加一。当然这个不是等概率的,因为20可能不是RAND_MAX的约数,但是这点概率通常可以忽略。但是最大的问题是double有精度误差,所以如果想要的得到的数比较大,可能会出精度的问题,比如说产生比这个数还大的数。
- 模20再加1。这个比较常用。
但是如果我希望得到一个在1 ~ 2e7之间的随机数,好像有点痛苦了,上面好几种方法都不行,如果你忽略第二种方法会有很多不会能出现的数,你还是可以继续用它的。除此之外,还有以下两种方法。
- 用rand()再乘上一个rand()再按上面的方法处理就好了。但是有个问题就是,你不能得到质数,但是总比除了再乘靠谱吧。作为懒人,我通常都这么干。
- 也是rand()两次,用第一次rand()的低14位作为新数的低14位,用二次rand()的低14位作为新数后14位(说的是2进制),然后你就可以得到一个在[0, 229-1)之间的整数,然后就可以按上面的方法处理。
暂时先就讨论这么多吧,进入下一部分。
[手打随机数生成器]
不要以为随便乱加一堆,乘一个乱七八糟的数,再加一个什么啊,然后再模一个什么啊,就能够称为"随机数生成器",也许它连伪随机数生成器都不算。(表示经常遇到生成不出偶数什么的情况或者生成出奇数的概率为偶数的几倍)。
所以说需要调参数,要多次测试。除了测试有没有生成出来外还应该让各种数刷出来的概率不说一样至少得相差要小一点啊。
比如说开始我们封装一个"简单"的随机数生成器

#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
typedef bool boolean;
typedef class Random {
public:
unsigned int pre;
unsigned int seed;
Random():pre(0), seed((unsigned) time (NULL)) { }
Random(int seed):pre(0), seed(seed) { }
unsigned int rand() {
unsigned int ret = (seed * 7361238 + seed % 20037 * 1244 + pre * 12342 + 378211) * (seed + 134543);
pre = seed;
seed = ret;
return ret;
}
}Random;
测试一下发现效果还可以,还算过得去,效率也不错,再运行一下stdlib.h中的rand(),发现最大的概率差大概和库中的函数差不多,参差不齐。但是这样生成的最大问题就是可能循环节会比较小(至少不搞天文数据还是算得过去的)。
于是决定进入time()函数增加一点恶趣味。。
unsigned int ret = (seed * 7361238 + seed % 20037 * 1244 + pre * 12342 + 378211 + time(NULL) * pre) * (seed + 134543);
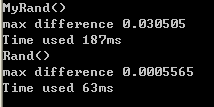
可怕,一不均匀二很慢,于是决定将两者组合一下,并调整一下参数。
unsigned int ret;
if(pre & 1)
ret = (seed * 7361238 + seed % 20037 * 1244 + pre * 12342 + 378211 + ((time(NULL) * pre) & 7624)) * (seed + 134543);
else
ret = (seed * 7361238 + seed % 20037 * 1244 + pre * 12342 + 378211) * (seed + 134543);
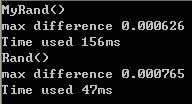
这样效果就还行,虽然慢了点,还是很棒的。最关键的是,因为unsigned int自带溢出,所以这个随机函数能够生成的数的最大值可以达到(233-1)!
然而测试一下1 ~ 2的随机数生成,输出出来,发现这是严格的奇偶交替。。于是重写了一个rand()
unsigned int rand() {
unsigned int ret;
if(ret & 1)
ret = (seed * 7361238 + seed % 20037 * 1245 + pre * 456451 + (time(NULL) * (pre * 5 + seed * 3 + 37)) + 156464);
else
ret = (seed * 7361238 + seed % 20037 * 1241 + pre * 456454 + (time(NULL) * (pre * 7 + seed * 3 + 18)) + 156464);
pre = seed;
seed = ret;
return ret;
}
效果在范围较大的时候都还不错。
[随机数生成器的应用]
为了简单,所以决定再定义一个成员函数
unsigned int rand(int low, int high){
if(low > high) return 0;
int len = high - low + 1;
return rand() % len + low;
}
生成在整数区间[low, high]之间的整数。
1.随机生成一个数列
这个很简单不停地调用rand()函数就好了
void randArray(int* array, unsigned int low, unsigned int high, int length) {
for(int i = 0; i < length; i++)
array[i] = rand(low, high);
}
2.随机生成一个没有重复的数的数列
可以想到的第一个方法,用树状数组维护已经使用过的数(用过的记为1,没有用过的记为0),每次随机产生一个在整数区间[0, r)中的整数,其中r为还没有选的整数个数,然后二分答案找到这个数,总时间复杂度为O(nlog2k),其中k为可选数的个数。(有没有更快找到第x个没有被选的数的方法我就不知道了)。
写起来会比较"爽",所以就不写了,树状数组至少20行,再加上7 ~ 8行的二分答案,然后最后几行for啊,什么的,总共大概30行左右,只是为了造个数据,写起来却像是半道题。可以考虑另寻思路。
开一个vis数组,记录这个这个数有没有被选。然后rand一个数,直到它没有被选再把它的值付给数组中的元素,然后打上标记。看似最坏的情况是O(n2)的或者更糟糕,但是这种情况极其少。可以尝试先写一个,然后运行,事实证明它没有那么糟糕的。
1 boolean randNonRepeatArray(int* array, unsigned int low, unsigned int high, int length) {
2 if((signed)(high - low + 1) < length) return false;
3 boolean *vis = new boolean[(const int)(high - low + 1)];
4 memset(vis, false, sizeof(boolean) * (high - low + 1));
5 for(int i = 0, c; i < length; i++) {
6 while(vis[(c = rand(low, high)) - low]);
7 vis[c - low] = true;
8 array[i] = c;
9 }
10 return true;
11 }
再运行一下106级的数据,并加一段这样的统计
1 inline void total() {
2 memset(counter, 0, sizeof(counter));
3 for(int i = 1; i <= L; i++) {
4 counter[a[i]]++;
5 if(counter[a[i]] > 1) {
6 cout << "The algorithm migit have some problems because of " << i << "." << endl;
7 return;
8 }
9 }
10 }
发现没有这段的输出,说明算法是正确的,再看看效率

以我家渣机的效率,可以估计它的期望时间复杂度大概是O(nlogn)级别的(只是这个级别,不是说就是O(nlogn))
下面给出更详细的估计(如果你不会一些高等数学的知识,完全可以跳过这一部分)
(当然,下面所有分析的前提是,这个随机数生成器生成出来的数是等概率的)
对于我已经用了x个数,一次选下来的期望是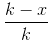 ,两次选下来的期望是
,两次选下来的期望是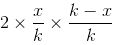 ,三次选下来的期望是,
,三次选下来的期望是, ,因此选取第(x + 1)个数的期望是
,因此选取第(x + 1)个数的期望是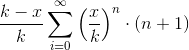 。
。
不用害怕,对(n + 1)展开进行求和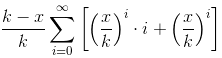
首先解决简单点的,先把第二部分解决了,我们可以用极限的思想,配合上等比数列求和公式轻松地得到

对于第一部分,我们首先设
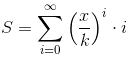
然后有
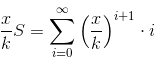
然后得到
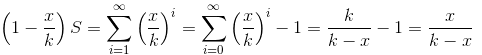
然后可以得到
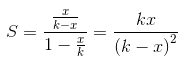
然后再把之前的括号内拿来求和
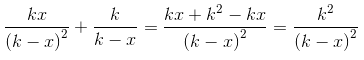
再乘上,得到它的期望是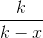 。
。
那么总的期望的次数就是
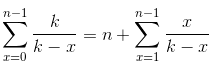
然后我们假设k和x,n都很大,于是我们可以愉快地调用调和级数的"求和公式"(当n很大的时候就越接近这个下界),然后得到了
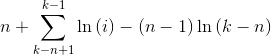
对于通常情况下的估计,第二项直接估为 ,然后就可以粗略地计算耗时。不过通常出数据时哪会管这个时间复杂度,那个方法写起简单用哪个,我不知道为什么这个算法在网上人人都说它很慢,最坏的情况下趋于无限(显然这基本上可以看做不可能事件),理论上还是蛮优秀的啊。下面将提供一种线性的方法。
,然后就可以粗略地计算耗时。不过通常出数据时哪会管这个时间复杂度,那个方法写起简单用哪个,我不知道为什么这个算法在网上人人都说它很慢,最坏的情况下趋于无限(显然这基本上可以看做不可能事件),理论上还是蛮优秀的啊。下面将提供一种线性的方法。
3.随机打乱一个数列
仍然可以用过上面的方法,生成一个新的位置没有重复的数组,然后按这个数组重新排列就好了。但是这里我想要介绍一种O(n)的方法。
- 设i = 1
- 我当前正在考虑位置i,执行一次rand(i, n),其中n为数组长度,设这个返回值为x,交换位置i和x(如果i = x则就不动就好了)
- 如果i = n,算法结束,否则i++,调回步骤2
现在来考虑算法的正确性,还是和上面一样,假设数据生成器十分完美,生成任何数都是等概率的。
下面将使用数学归纳法来证明
1. 对于位置1,显然每个数在这个位置上的概率为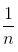
2. 对于一个位置k(k > 1),假设每个数在这之前的(k - 1)个位置上的概率都为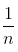 (归纳假设),则剩下的每个数留在位置k的概率为(第一个分数是因为留在后(n - k + 1)的概率为这么多,后面一个就很好理解)
(归纳假设),则剩下的每个数留在位置k的概率为(第一个分数是因为留在后(n - k + 1)的概率为这么多,后面一个就很好理解)
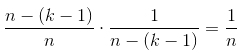
所以算法是满足等概率。显然这个算法不会发生什么冲突,一个把另一个覆盖,数放到数组外边去了之类的情况,所以它是正确的。
写起来也很短,而且还可以写成模板
1 template<typename T>
2 void randomUpset(T* array, int length) {
3 for(int i = 0; i < length; i++) {
4 int idx = rand(i, length - 1);
5 if(idx != i) {
6 T t = array[idx];
7 array[idx] = array[i];
8 array[i] = t;
9 }
10 }
11 }
对于上面的那一种任务,可以想到用这个方法随机打乱(1 ~ k)生成出1 ~ k的排列的前n个(当i >= n的时候break掉),显然它是正确的,时间复杂度成功降为O(n)。
4.更小内存消耗的无重复随机数列生成
经常遇到数据结构的题,数据范围是凶残的,比如说109或者1018之类的,如果按照上面的生成方法那么内存会炸掉,但是显然n不会那么大,那么考虑一下其他方法。
首先来思考一个线性的做法
- 将i设为1,开始步骤2
- 如果i <= n,则将a[i]设为i,将i++然后继续步骤2,否则跳转步骤3
- 否则随机一个在1 到 i之间的数r,如果r小于等于k,则将a[k]设为i,否则不管。然后i++,如果i > k就跳转到步骤4。
- 随机打乱a数组
然后来考虑一下算法的正确性。这个用和上面的相似的方法就可证出来。
这时只用存下a数组,所以空间复杂度仅为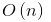 ,但是时间复杂度变为了
,但是时间复杂度变为了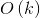 ,只能另寻思路。
,只能另寻思路。
考虑用更高效的数据结构(例如hash表或者平衡树,当然如果您高兴可以线段树动态开节点)来优化上面的应用2的最后一种做法。
如果用平衡树或者线段树,那么它的期望大概是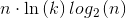 ,空间复杂度为。
,空间复杂度为。
但是如果是hash表,那么时间复杂度和空间复杂度都是O(玄学)(hash表本来就是玄学。。)
5.生成一棵树
如果你不知道树在计算机里是指什么,我就水水地说一下,由n - 1条边使得n个点互相联通的一个无向图。
那么怎么生成一棵树呢?
我们假定父节点的编号比子节点小,是不是有思路了?
然后每个节点(除了根节点外)去生成它的父节点就好了。
那么可以想到生成一个无向连通图,因为一个有n个点的无向连通图的边数是大于等于(n - 1)的,所以它是基于树上加点边。于是你就可以先生成一棵树,然后不断加边就好了。
6.更多的应用
上面只是讲述了如何出数据之类的问题,下面列举一点基于随机数的一些算法 / 数据结构
- Treap的优先级,虽然可以出有序数据,但是通常都是用的随机数
- 爬山 & 退火
- 模拟一些没有规律的运动,或者说画面的渲染(比如说吸收了多少的光,反射了多少,来确定物体的亮度)
(最后呢,欢迎提问或者指出问题(我觉得上面推一大堆东西的那一块问题特别大))
提供一份模板 [RamdomV1.1.zip]
历史版本一览
- RandomV1.0.zip [Download]
要用的时候解压放在当前工作目录下,加入#include "Random"
[更新日志]
- 2017.5.19 更新代码一份,更正两处笔误,更新随机函数。
- 2017.5.20 更新3处有问题的地方