前言
写这篇文章的最初动力是来自于一次笔试经历。有一道笔试题大概是这样的:程序使用一个txt文件来存储操作记录。存储记录是多行字符串,每一行代表一次操作记录,格式如下:用户名+操作事项名称+操作时间。现在假设这个txt文件已经非常大了,要求对这个文件做一些处理(具体记不太清了,接近于一些逻辑处理和增删改)。毫无疑问,对于txt文件来说,要对之中的数据进行处理,首先要把数据读入内存,这就涉及到选择何种数据结构的问题了。基于自己的常规思维,我不加思索就选择了自定义类的List泛型存储数据。之后再与面试官交流的时候,他给出了用Dictionary泛型的解决方案。由于自己的认知局限,当时没听明白面试官的具体解释,导致这道问题的讨论就成了单方面的阐述,失去了双方的交流。面试也是发现问题的一种途径。对于集合知识,自身确实存在认知匮乏的问题,而在许多程序中,选择合适的数据结构往往是决定整个算法或代码是否简洁优雅的关键所在,如果对集合都不熟悉的话,那么谈何选择合适的数据结构呢?如果你也存在和我一样的问题,可以尝试着继续读这篇文章,或许能给你带来帮助。
这篇文章讨论的主题是集合,重点在于分析集合的区别和联系,加深对集合的认知与使用,熟悉常用C#类库有关集合类的组织结构。
数组
论集合,不得不谈的第一项就是数组。C#数组需要声明元素类型,元素类型可以是值类型也可以是引用类型,数组是静态类型,初始化必须指定个数大小,且创建后的数组是连续存放在内存中的。声明方式如下所示:
int[] intArray = new int[10]; //整型数组 string[] stringArray = new string[10]; //字符串数组 Random[] randArray = new Random[10]; //类数组
数组是从Array隐式派生的,这是由编译器完成的,Array类被组织在System命名空间下。
Array myArray1 = new int[10]; Array myArray2 = new string[10]; Array myArray3 = new Random[10];
数组是引用类型,初始化后分配在堆上。
System.Collections
1. System.Collections 组织空间

2. 通用接口


public interface IEnumerator
{
bool MoveNext();
object Current { get; }
void Reset();
}
public interface IEnumerable
{
IEnumerator GetEnumerator();
}
public interface ICollection : IEnumerable
{
int Count { get; }
bool IsSynchronized { get; }
object SyncRoot { get; }
void CopyTo(Array array, int index);
}
public interface IList : ICollection, IEnumerable
{
bool IsFixedSize { get; }
bool IsReadOnly { get; }
object this[int index] { get; set; }
int Add(object value);
void Clear();
bool Contains(object value);
int IndexOf(object value);
void Insert(int index, object value);
void Remove(object value);
void RemoveAt(int index);
}
public interface IDictionary : ICollection, IEnumerable
{
bool IsFixedSize { get; }
bool IsReadOnly { get; }
object this[object key] { get; set; }
ICollection Keys { get; }
ICollection Values { get; }
void Add(object key, object value);
void Clear();
bool Contains(object key);
IDictionaryEnumerator GetEnumerator();
void Remove(object key);
}
集合类型都实现了IEnumerable接口,从而可以使用foreach迭代。
实现了ICollectoin接口的集合类表明集合中的元素是有先后顺序的。
IList接口继承了ICollection接口,实现了IList接口的集合类不止表明集合中的元素是有先后顺序,而且表明集合类可以通过下标访问的方式访问集合元素。
IDictionary接口也继承了ICollection接口,实现了IDicionary接口的集合类可以通过下标key访问的访问方式访问集合元素。
3. ArrayList
Array是静态分配的,意味着创建数组后的大小不能改变,然而实际应用中,我们很多时候无法在一开始确定数组的大小,这样便需要一种能动态分配的数组类型,ArrayList就是为此而生的。ArrayList主要实现的接口有IList,所以这是一个索引集合。
//声明ArrayList ArrayList myArray = new ArrayList(); //插入元素 可以为值类型 也可以为引用类型 myArray.Add(1); myArray.Add("hello"); myArray.Add(new Random()); int i = (int)myArray[0]; string str = (string)myArray[1]; Random rand = (Random)myArray[2];
使用Reflector查看ArrayList的底层实现,可以看到动态数组其实是由一个object[] _items维系着的,这就解释了为什么集合的元素可以为值类型也可以为引用类型。这样的底层实现貌似灵活性很高,集合可以容纳异构类型,然而却带来了性能上的问题,因为当插入值类型的时候,就存在隐式装箱操作,而当把元素还原为值类型变量的时候,又发生了一次显式拆箱操作,如果这种装箱拆箱存在上千万次,那么程序的性能是要大打折扣的。同时要注意一点的是object类型可以强制转化为任何类型,这是说编译器不会检查object强制转换的类型,如果无法转换的话,这必须等到运行时才能确定出错,这就是类型安全问题。
所以应该尽量避免使用ArrayList。
4. Stack 和 Queue
对于栈和队列这两种经典的数据结构,C#也将它们组织在System.Collections命名空间中。Stack是后进先出的结构,Queue是先进先出的结构,这两者主要实现的接口有ICollection,表示它们都是有序集合,应注意到这两者都不可以使用下标访问集合元素。这两者的底层实现都是由一个object[] _array维系着,都存在着装箱拆箱的性能问题和类型安全问题,所以应该尽量避免直接使用它们。
5. HashTable
前面我们提到的集合类都属于单元素集合类,实际应用中我们需要一种键值对的形式存储数据,即集合类中存储的不再是单个元素,而是key-value两个元素,HashTable就是为此而生的。HashTable实现了IDictionary接口。
//创建一个HashTable实例 Hashtable hashDict = new Hashtable(); //往容器中加入key-value hashDict.Add("a", "hello"); hashDict.Add("b", "hello"); hashDict.Add("c", "go"); hashDict.Add(4, 300); //通过下标key获取value string str1 = hashDict["a"].ToString(); string str2 = (string)hashDict["b"]; int i4 = (int)hashDict[4];
HashTable中的key关键字必须唯一,不能重复。如果深入到HashTable的底层实现,应该可以清楚的看到key和value是结构体bucket数组维护着,bucket中key和value的实现也是object,所以存在着与ArrayList,Stack,Queue同样的问题,应该尽量避免使用HashTable。
为什么键值集合类要命名为HashTable?
从HashTable的命名来看,我们可以断定说键值集合跟Hash必定存在某种联系。哈希又称为散列,散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key),f又称为散列函数。HashTable实现了IDictionary接口,表明HashTable可以通过下标key访问的方式获取数组元素,即 HashTable[key],这与实现了IList接口的集合类的数字下标访问存在着明显的不同。那么如何通过key快速定位得到value呢?我相信通过前面的铺垫大伙都知道是什么回事了,对,就是哈希函数的运用。具体可以参考文章http://www.cnblogs.com/abatei/archive/2009/06/23/1509790.html。
6. SortedList
在控制台应用程序下运行以下代码并观察结果:
Hashtable hashDict = new Hashtable(); hashDict.Add("key1", "1"); hashDict.Add("key2", "2"); hashDict.Add("key3", "3"); hashDict.Add("key4", "4"); foreach (string key in hashDict.Keys) { Console.WriteLine(hashDict[key]); }
我们可以看到这里并没有按照预期的Key顺序输出Value。也就是说HashTable是不按照key顺序排序的,具体原理可以参考HashTable的源码。SortedList很好地解决了键值集合顺序输出的问题。
//创建一个SortedList实例 SortedList sortList = new SortedList(); //往容器中加入元素 sortList.Add("key1", 1); sortList.Add("key2", 2); sortList.Add("key3", 3); sortList.Add("key4", 4); //获取按照key排序的第index个Key string str1 = sortList.GetKey(0).ToString(); Console.WriteLine(str1); //获取按照key排序的第index个Value int i1 = (int)sortList.GetByIndex(0); Console.WriteLine(i1.ToString()); //下标key访问 string str2 = sortList["key2"].ToString(); Console.WriteLine(str2); //遍历sortList foreach (DictionaryEntry item in sortList) { Console.WriteLine(item.Key); Console.WriteLine(item.Value); }
SortedList实现了IDictionary接口,所以可以使用下标key访问元素的形式,同时要求key必须唯一。
SortedList的底层实现与HashTable有着本质的区别。SortedList中使用object[] keys 和 object[] values 两个对象数组分别来存储key和value,要求实现能按照key有序输出,在下标key访问的时候就无法使用Hash函数了,所以SortedList虽然也是键值集合,但与Hash却没有任何联系。通过查看SortedList的底层代码,原来它的实现是二分查找(BinarySearch),也就是说要求key是有序排列的,在查找的时候进行二分比较搜索,找到对应的index,从而返回values[index]。
如果需要实现按照key有序输出,那么毫无疑问就要选择SortedList了。如果不需要按照key有序输出,在小数据量的情况下,两者选择任何一个性能都应该差不多,但大数据量的情况下,则更应该选择HashTable。为什么呢?理由有两点。1.HashTable的key下标访问更直接更快。通过上面分析我们知道SortedList的key下标访问是由二分查找实现的,实现的时间复杂度为O(log n),而Hash函数的时间复杂度为O(1),HashTable的实现更优。2.SortedList要求key有序,这意味着在插入的时候必须适当地移动数组,从而达到有序的目的,所以存在性能上的消耗,HashTable的实现更优。
SortedList也并没有走出装箱拆箱性能和类型安全的圈子,所以应该尽量避免直接使用它。
System.Collections.Generic
1. System.Collections.Generic 组织空间
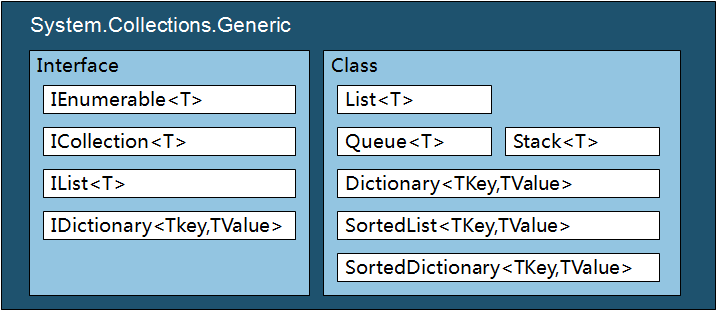
2. 何为集合泛型
新的命名空间下,可以看到接口或集合类后都携带了<T>或<TKey,TValue>。很明显,携带<T>对应的是单元素集合,携带<TKey,TValue>对应的是键值集合。那么泛型又是如何工作的呢?来看一下其编译过程吧:初次编译时,首先生成IL代码和元数据,T(TKey,TValue)只是作为类型占位符,不进行泛型类型的实例化;在进行JIT编译时,将以实际类型替换IL代码和元数据中的T占位符,并将其转换为本地代码,下一次对该泛型类型的引用将使用相同的本地代码。
泛型即解决了装箱拆箱的性能问题,又解决了潜在的类型转换安全问题,所以在实际应用中,推荐使用泛型集合代替非泛型集合。
3. 泛型集合与非泛型集合的对应
ArrayList => List<T> 新的泛型集合去掉了Array前缀。
Stack,Queue => Stack<T>,Queue<T>
HashTable => Dictionary<TKey,TValue> 新的泛型键值集合的命名放弃了HashTable,但其内部实现原理还是和HashTable有很大相似的。
SortedList => SortedList<TKey,TValue> | SortedDictionary<TKey,TValue>
SortedList<TKey,TValue>的底层实现基本是按照SortedList,下标key访问是二分查找的O(log n),插入和移除运算复杂度是O(n)。而SortedDictionary<TKey,TValue> 底层实现是二叉搜索树,下标key访问也为O(log n),插入和移除运算复杂度是O(log n)。所以SortedList<TKey,TValue>使用的内存会比SortedDictionary<TKey,TValue>小,SortedDictionary<TKey,TValue>在插入和移除元素的时候更快。