-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
开始讲PCA与ICA的时候,首先要明确几个概念
1.概率分布函数与概率密度函数的区别
从数学上看,分布函数F(x)=P(X<x),表示随机变量X的值小于x的概率。这个意义很容易理解。
概率密度f(x)是F(x)在x处的关于x的一阶导数,即变化率。如果在某一x附近取非常小的一个邻域Δx,那么,随机变量X落在(x, x+Δx)内的概率约为f(x)Δx,即P(x<X<x+Δx)≈f(x)Δx
2.协方差存在的原因:
我们都知道均值,方差,标准差等相关的统计量存在的原因,但是需要明确的一点是,方差只能用来衡量一维变量的离散程度,对于多维变量,离散程度就要用到协方差,定义如下:
需要注意的是协方差矩阵计算的是不同维度之间的协方差,而不是不同样本之间的。
协方差就是这样一种用来度量两个随机变量关系的统计量,我们可以仿照方差的定义:
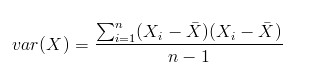
来度量各个维度偏离其均值的程度,标准差可以这么来定义:

协方差的结果有什么意义呢?如果结果为正值,则说明两者是正相关的(从协方差可以引出“相关系数”的定义),也就是说一个人越猥琐就越受女孩子欢迎,嘿嘿,那必须的~结果为负值就说明负相关的,越猥琐女孩子越讨厌,可能吗?如果为0,也是就是统计上说的“相互独立”。
从协方差的定义上我们也可以看出一些显而易见的性质,如:
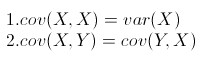
协方差多了就是协方差矩阵
上一节提到的猥琐和受欢迎的问题是典型二维问题,而协方差也只能处理二维问题,那维数多了自然就需要计算多个协方差,比如n维的数据集就需要计算 n! / ((n-2)!*2) 个协方差,那自然而然的我们会想到使用矩阵来组织这些数据。给出协方差矩阵的定义:

这个定义还是很容易理解的,我们可以举一个简单的三维的例子,假设数据集有三个维度,则协方差矩阵为
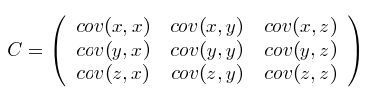
可见,协方差矩阵是一个对称的矩阵,而且对角线是各个维度上的方差。
3.独立与不相关的区别
独立一定不相关,不相关不一定独立
不相关指的是没有线性关系,不代表两者没有关系,而独立表示的就是没有关系
----------------------------------------------------------------------------------------------------------------------------
正态分布又名高斯分布
PCA指的是主成分分析;其样本的主元正交,样本必须符合高斯分布,源信号之间是非相关的
主要作用:数据降维
PCA的过程实际上就是求协方差矩阵的特征值和特征向量,然后做数据转换
(A)特征归一化
特征归一化直接给出代码参考:
function [X_norm, mu, sigma] = featureNormalize(X)
%FEATURENORMALIZE Normalizes the features in X
% FEATURENORMALIZE(X) returns a normalized version of X where
% the mean value of each feature is 0 and the standard deviation
% is 1. This is often a good preprocessing step to do when
% working with learning algorithms.
mu = mean(X);
X_norm = bsxfun(@minus, X, mu);
sigma = std(X_norm);
X_norm = bsxfun(@rdivide, X_norm, sigma);
% ============================================================
end
X是一个m*n的矩阵,代表有m个样本,每个样本有n个特征,每一行都是一个样本,这里经过计算得到的X_norm实际上是X矩阵是最终得到的特征,首先计算了所有训练样本每个特征的均值, 然后减去均值, 然后除以标准差。
(B)计算降维矩阵
B1.计算样本特征的协方差矩阵
可以对每个样本单独计算,或者采用矩阵的方式计算

B2.计算协方差矩阵的特征值和特征向量
采用奇异值分解的方法来计算协方差矩阵的特征值和特征向量,关于奇异值分解,比较复杂,我通常直接使用matlab的函数即可

在上图中, U 是计算得到的协方差矩阵的所有特征向量, 每一列都是一个特征向量, 并且特征向量是根据特征大小由大到小进行排序的, U 的维度为 n * n 。 U 也被称为降维矩阵。 利用U 可以将样本进行降维。 默认的U 是包含协方差矩阵的所有特征向量, 如果想要将样本降维到 k 维, 那么就可以选取 U 的前 k 列, Uk 则可以用来对样本降维到 k 维。 这样 Uk 的维度为 n * k
(C)降维计算
获得降维矩阵后就可以将样本映射到低维空间上

X矩阵是m*n维的,降维后就变成了m*k,每一行代表样本的一个特征。
(降维的k的值的选择)
在 http://blog.csdn.net/watkinsong/article/details/8234766 这篇文章中, 很多人问了关于贡献率的问题, 这就是相当于选择k的值的大小。 也就是选择降维矩阵 U 中的特征向量的个数。
k 越大, 也就是使用的U 中的特征向量越多, 那么导致的降维误差越小, 也就是更多的保留的原来的特征的特性。 反之亦然。
从信息论的角度来看, 如果选择的 k 越大, 也就是系统的熵越大, 那么就可以认为保留的原来样本特征的不确定性也就越大, 就更加接近真实的样本数据。 如果 k 比较小, 那么系统的熵较小, 保留的原来的样本特征的不确定性就越少, 导致降维后的数据不够真实。 (完全是我个人的观点)
关于 k 的选择, 可以参考如下公式:

上面这个公式 要求 <= 0.01, 也就是说保留了系统的99%的不确定性。
需要计算的就是, 找到一个最小的 k 使得上面的公式成立, 但是如果计算上面公式, 计算量太大, 并且对于每一个 k 取值都需要重新计算降维矩阵。
可以采用下面的公式计算 k 的取值, 因为在 对协方差矩阵进行奇异值分解的时候返回了 S , S 为协方差矩阵的特征值, 并且 S 是对角矩阵, 维度为 n * n, 计算 k 的取值如下:

3.5 重构 (reconstruction, 根据降维后数据重构原数据), 数据还原
获得降维后的数据, 可以根据降维后的数据还原原始数据。
还原原始数据的过程也就是获得样本点映射以后在原空间中的估计位置的过程, 即计算 X-approx的过程。

使用降维用的降维矩阵 Uk, 然后将 降维后的样本 z 还原回原始特征, 就可以用上图所示的公式。
附一张关于PCA的python实现照片
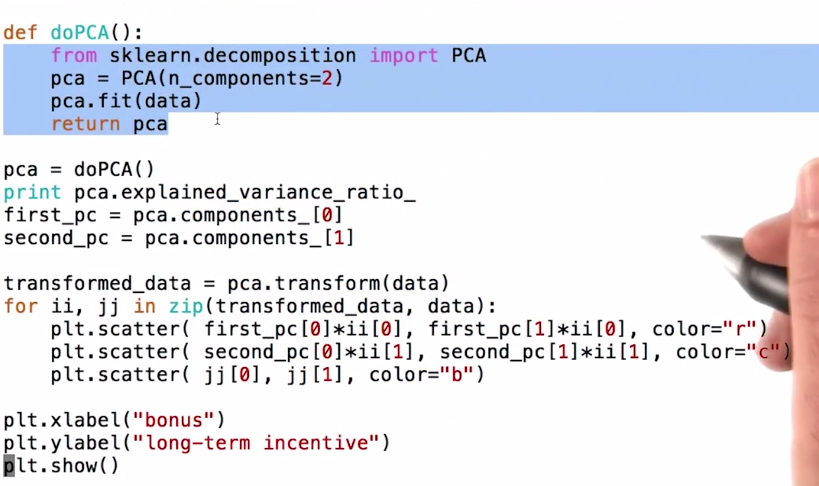
matlab实现的简单实例
Compute principal components for the ingredients data in the Hald data set, and the variance accounted for by each component.
load hald; %载入matlab内部数据
[pc,score,latent,tsquare] = princomp(ingredients); %调用pca分析函数
ingredients,score,pc,latent,tsquare %显示得到的结果
http://blog.csdn.net/watkinsong/article/details/8234766像这样多总总结。
------------------------------------------------------------------------------------------插入一个小概念--------------------------------------------------------------------------------------
基本概念:
1.似然函数与似然性以及概率 https://www.cnblogs.com/hejunlin1992/p/7976119.html
似然指的是:通过观测到的结果来估计概率模型中的各种参数,而概率指的是通过已知参数的概率模型来判断某件事情发生的概率。
似然函数是一种条件概率的函数。
最大似然函数:
- 这里的似然函数是指
不变时,关于
的一个函数。
- 最大似然估计函数不一定是惟一的,甚至不一定存在。
2.密度函数和线性变换
在讨论ICA具体算法之前,我们先来回顾一下概率和线性代数里的知识。
假设我们的随机变量s有概率密度函数![]() (连续值是概率密度函数,离散值是概率)。为了简单,我们再假设s是实数,还有一个随机变量x=As,A和x都是实数。令
(连续值是概率密度函数,离散值是概率)。为了简单,我们再假设s是实数,还有一个随机变量x=As,A和x都是实数。令![]() 是x的概率密度,那么怎么求
是x的概率密度,那么怎么求![]() ?
?
令![]() ,首先将式子变换成
,首先将式子变换成![]() ,然后得到
,然后得到![]() ,求解完毕。可惜这种方法是错误的。比如s符合均匀分布的话(
,求解完毕。可惜这种方法是错误的。比如s符合均匀分布的话(![]() ),那么s的概率密度是
),那么s的概率密度是![]() ,现在令A=2,即x=2s,也就是说x在[0,2]上均匀分布,可知
,现在令A=2,即x=2s,也就是说x在[0,2]上均匀分布,可知![]() 。然而,前面的推导会得到
。然而,前面的推导会得到![]() 。正确的公式应该是
。正确的公式应该是
![]()
推导方法
![]()
![]()
更一般地,如果s是向量,A可逆的方阵,那么上式子仍然成立。
ICA指的是独立成分分析
样本不符合高斯分布,源信号间彼此相互独立,混合信号是高斯分布的,原因在于中心极限定理告诉我们:大量独立同分布随机变量之和满足高斯分布。还有一个概念,在信息论里有一个强有力的结论是:高斯分布的随机变量是同方差分布中熵最大的。也就是说对于一个随机变量来说,满足高斯分布时,最随机。
https://en.wikipedia.org/wiki/Independent_component_analysis#cite_note-18维基百科关于ICA的解释
ICA相比与PCA更能刻画变量的随机统计特性,且能抑制高斯噪声。
主要作用:盲源信号分析 来源:鸡尾酒会问题
关于ICA实现的具体过程总结如下:
假设可观察的信号为:






以下摘自http://blog.csdn.net/ffeng271/article/details/7353881
ICA算法
ICA算法归功于Bell和Sejnowski,这里使用最大似然估计来解释算法,原始的论文中使用的是一个复杂的方法Infomax principal。
我们假定每个![]() 有概率密度
有概率密度![]() ,那么给定时刻原信号的联合分布就是
,那么给定时刻原信号的联合分布就是
![]()
这个公式代表一个假设前提:每个人发出的声音信号各自独立。有了p(s),我们可以求得p(x)
![]()
左边是每个采样信号x(n维向量)的概率,右边是每个原信号概率的乘积的|W|倍。
前面提到过,如果没有先验知识,我们无法求得W和s。因此我们需要知道![]() ,我们打算选取一个概率密度函数赋给s,但是我们不能选取高斯分布的密度函数。在概率论里我们知道密度函数p(x)由累计分布函数(cdf)F(x)求导得到。F(x)要满足两个性质是:单调递增和在[0,1]。我们发现sigmoid函数很适合,定义域负无穷到正无穷,值域0到1,缓慢递增。我们假定s的累积分布函数符合sigmoid函数
,我们打算选取一个概率密度函数赋给s,但是我们不能选取高斯分布的密度函数。在概率论里我们知道密度函数p(x)由累计分布函数(cdf)F(x)求导得到。F(x)要满足两个性质是:单调递增和在[0,1]。我们发现sigmoid函数很适合,定义域负无穷到正无穷,值域0到1,缓慢递增。我们假定s的累积分布函数符合sigmoid函数
![]()
求导后
![]()
这就是s的密度函数。这里s是实数。
如果我们预先知道s的分布函数,那就不用假设了,但是在缺失的情况下,sigmoid函数能够在大多数问题上取得不错的效果。由于上式中![]() 是个对称函数,因此E[s]=0(s的均值为0),那么E[x]=E[As]=0,x的均值也是0。
是个对称函数,因此E[s]=0(s的均值为0),那么E[x]=E[As]=0,x的均值也是0。
知道了![]() ,就剩下W了。给定采样后的训练样本
,就剩下W了。给定采样后的训练样本![]() ,样本对数似然估计如下:
,样本对数似然估计如下:
使用前面得到的x的概率密度函数,得

大括号里面是![]() 。
。
接下来就是对W求导了,这里牵涉一个问题是对行列式|W|进行求导的方法,属于矩阵微积分。这里先给出结果,在文章最后再给出推导公式。
![]()
最终得到的求导后公式如下,![]() 的导数为
的导数为![]() (可以自己验证):
(可以自己验证):

其中![]() 是梯度上升速率,人为指定。
是梯度上升速率,人为指定。
当迭代求出W后,便可得到![]() 来还原出原始信号。
来还原出原始信号。
注意:我们计算最大似然估计时,假设了![]() 与
与![]() 之间是独立的,然而对于语音信号或者其他具有时间连续依赖特性(比如温度)上,这个假设不能成立。但是在数据足够多时,假设独立对效果影响不大,同时如果事先打乱样例,并运行随机梯度上升算法,那么能够加快收敛速度。
之间是独立的,然而对于语音信号或者其他具有时间连续依赖特性(比如温度)上,这个假设不能成立。但是在数据足够多时,假设独立对效果影响不大,同时如果事先打乱样例,并运行随机梯度上升算法,那么能够加快收敛速度。
回顾一下鸡尾酒宴会问题,s是人发出的信号,是连续值,不同时间点的s不同,每个人发出的信号之间独立(![]() 和
和![]() 之间独立)。s的累计概率分布函数是sigmoid函数,但是所有人发出声音信号都符合这个分布。A(W的逆阵)代表了s相对于x的位置变化,x是s和A变化后的结果。
之间独立)。s的累计概率分布函数是sigmoid函数,但是所有人发出声音信号都符合这个分布。A(W的逆阵)代表了s相对于x的位置变化,x是s和A变化后的结果。
ICA的投影追踪解释(Projection Pursuit)
投影追踪在统计学中的意思是去寻找多维数据的“interesting”投影。这些投影可用在数据可视化、密度估计和回归中。比如在一维的投影追踪中,我们寻找一条直线,使得所有的数据点投影到直线上后,能够反映出数据的分布。然而我们最不想要的是高斯分布,最不像高斯分布的数据点最interesting。这个与我们的ICA思想是一直的,寻找独立的最不可能是高斯分布的s。
在下图中,主元是纵轴,拥有最大的方差,但最interesting的是横轴,因为它可以将两个类分开(信号分离)。

ICA算法的前处理步骤
1、中心化:也就是求x均值,然后让所有x减去均值,这一步与PCA一致。
2、漂白:目的是将x乘以一个矩阵变成![]() ,使得
,使得![]() 的协方差矩阵是
的协方差矩阵是![]() 。解释一下吧,原始的向量是x。转换后的是
。解释一下吧,原始的向量是x。转换后的是![]() 。
。
![]() 的协方差矩阵是
的协方差矩阵是![]() ,即
,即
![]()
我们只需用下面的变换,就可以从x得到想要的![]() 。
。
![]()
其中使用特征值分解来得到E(特征向量矩阵)和D(特征值对角矩阵),计算公式为
![]()
下面用个图来直观描述一下:
假设信号源s1和s2是独立的,比如下图横轴是s1,纵轴是s2,根据s1得不到s2。

我们只知道他们合成后的信号x,如下

此时x1和x2不是独立的(比如看最上面的尖角,知道了x1就知道了x2)。那么直接代入我们之前的极大似然概率估计会有问题,因为我们假定x是独立的。
因此,漂白这一步为了让x独立。漂白结果如下:

可以看到数据变成了方阵,在![]() 的维度上已经达到了独立。
的维度上已经达到了独立。
然而这时x分布很好的情况下能够这样转换,当有噪音时怎么办呢?可以先使用前面提到的PCA方法来对数据进行降维,滤去噪声信号,得到k维的正交向量,然后再使用ICA。
小结
ICA的盲信号分析领域的一个强有力方法,也是求非高斯分布数据隐含因子的方法。从之前我们熟悉的样本-特征角度看,我们使用ICA的前提条件是,认为样本数据由独立非高斯分布的隐含因子产生,隐含因子个数等于特征数,我们要求的是隐含因子。
而PCA认为特征是由k个正交的特征(也可看作是隐含因子)生成的,我们要求的是数据在新特征上的投影。同是因子分析,一个用来更适合用来还原信号(因为信号比较有规律,经常不是高斯分布的),一个更适合用来降维(用那么多特征干嘛,k个正交的即可)。有时候也需要组合两者一起使用。这段是人家的个人理解,仅供参考。
RCA随机主成分分析,特点是快
LDA线性判别分析
整理这个的原因在于 ,我想搞明白ICA算法是否可以应用到测量数据的处理过程中,就比如我们所搭建系统测量的信号实际是包括暗噪声,同频通道测量值和不同频通道的串扰值,那么这个被测量的信号是否可以看做是盲源信号,因为测量值的各个组成部分都是可以看做是独立随机的过程,那么也就符合高斯分布。现在的问题是怎样将ICA用于实际的信号处理中去。