http://www.cnblogs.com/xing901022/p/9362339.html
本章主要围绕机器学习的推荐实践过程以及评测指标,一方面告诉我们如何优化我们的模型;另一方面告诉我们对于分类的算法,使用精确率和召回率或者F1值来衡量效果更佳。最后还强调了下,在大部分的机器学习中,训练样本对模型的准确率都有一定的影响。
更多内容参考 机器学习&深度学习
机器学习最佳实践
针对垃圾邮件分类这个项目,一般的做法是,首先由一堆的邮件和是否是垃圾邮件的标注,如[(邮件内容1,是),(邮件内容2,否),(邮件内容3,是)...]。然后我们针对邮件的内容去做分词,搜集全部词语组织成词表;由于邮件内容的词通常都是常用词,因此可以取top500的词组织成词表,然后替换内容邮件。
接下来如果想要优化机器学学习模型,可以有下面几种: 1 搜集更多的数据 2 从邮件的地址中寻找新的feature 3 从邮件内容中寻找新的feature 4 基于更复杂的算法检测错拼词
推荐的步骤是: 1 先通过一些简单的算法快速实现,然后通过交叉验证选择一个比较好的模型 2 通过学习曲线,确定是属于高偏差的情况、还是高方差的情况,再来决定是否增加样本、或者增加特征 3 错误分类的分析,通过分析那些被分错的样本,观察是否有什么共同的特征。比如分析一个英文单词,提取词干和不提取,错误率有没有什么变化,从而调整算法
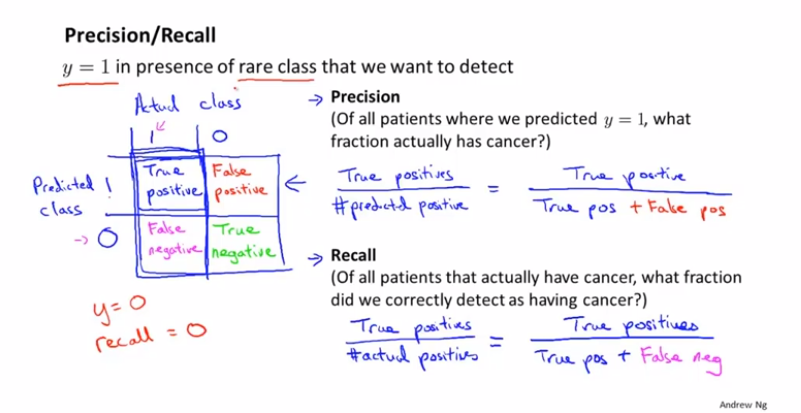
P、R、F1模型评测
在说一个其他的例子,癌症检测。如果我们的错误率是1%,而1%中只有0.5%是真正得了癌症的,那么这个分类的算法其实也称不上好。所以错误率低,并不一定代表模型就好。
因此可以使用下面的指标衡量方法,精确率和召回率。精确率是指我们预测的多少是对的;召回率是指我们预测对的全不全(预测对的占本身就是对的多少)。通过这两个指标可以比较好的评判一个分类算法的好坏。
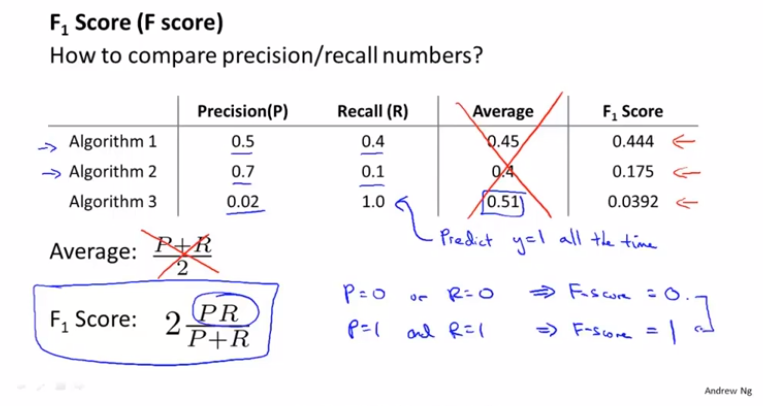
如果不知道怎么平衡精确率和召回率,可以直接使用F1 Score,这个指标同时衡量了两个值:
一般说来,盲目的扩充样本数据并没有什么作用。但是在一些特例中,只有足够的样本才能使得训练更准确。比如基于上下文却分容易混淆的词语。