Decomposition Problem
Introduction
Decomposition is a approach to solving a problem by breaking it up into smaller ones and solving each of smaller ones separately, or sequentially.
If the problem is separable, i.e., the objective is comprised by the sum of functions of sub-vector \(x_i\) and each constraint only involve only one variable from one of the sub-vector \(x_i\), then each smaller problem involving \(x_i\) separately can be easily solved(called trivially parallelizable or block separable). The more interesting problem is that sub-vectors are tangled.
The core idea of decomposition is: using effective methods to solve sub-problems and combining the results in such a way as to solve the larger problem. Two techniques will be introduced in the following.
Primal decomposition
unconstrainted case
where \(x_1\) and \(x_2\) are called private or local variables, \(y\) is the complicating or coupling variable which complicates the problem and \(x=\{x_1, x_2, y\}\). If \(y\) is fixed, the problem is separable and the subproblem is equivalent to find \(\phi_1(y)=\min_{x_1}f_1(x_1, y)\) and \(\phi_2(y)=\min_{x_2}f_2(x_2, y)\). The original problem becomes
which is called master problem.
A decomposition method solve the original problem by a iterative method, such as the subgradient method.

Dual decomposition
consistency constraint
The Lagrangian is
The dual function is
where \(g_1(v)=\inf_{x_1,y_1} f_1(x_1,y_1)+v^Ty_1=-f_1^*(0,-v)\), \(g_2(v)=\inf_{x_2,y_2} f_2(x_2,y_2)-v^Ty_2=-f_2^*(0,-v)\)
The dual problem is
where \(g_1(v)\) and \(g_2\) can be solved separately, according to the Primal decomposition context.

Decomposition with constraints
where the last constraint complicates the problem, called complicating constraints.
Primal decomposition
Assigning a fixed amount of resource \(t\) to \(h_1(x_1)\) and the amount of \(h_2(x_2)\) is \(-t\), then the original problem can be separable.
Let \(\phi_1(t)\) and \(\phi_2(t)\) be the optimal value of the problem \(\ref{eq:DCP1}\) and \(\ref{eq:DCP2}\), \(\lambda_1\) and \(\lambda_2\) denote the optimal dual variable of corresponding subproblem. Then the optimization process is:
- Solve the subproblem \(\ref{eq:DCP1}\), to find an optimal \(x_1\) and \(\lambda_1\)
- Solve the subproblem \(\ref{eq:DCP2}\), to find an optimal \(x_2\) and \(\lambda_2\)
- \(t=t-\alpha(\lambda_2-\lambda_1)\)
Dual decomposition
The partial Lagrangian is
The problem is the same with \(\ref{eq:DCC}\)
The more complicated decomposition can be represented by a hypergraph or net.
There are three subproblems and each link represent the coupling variable or constraint between the adjoined subproblems.
How primal and dual decomposition work:
- In primal decomposition, each hyperedge or net has a single variable associated with it. Each subproblem is optimized separately, using the public variable values (asserted) on the nets. Each subproblem produces a subgradient associated with each net it is adjacent to. These are combined to update the variable value on the net, hopefully in such a way that convergence to (global) optimality occurs.
- In dual decomposition, each subproblem has its own private copy of the public variables on the nets it is adjacent to, as well as an associated price vector(dual variable \(\lambda_i\)). The subsystems use these prices to optimize their local variables, including the local copies of public variables. The public variables on each net are then compared, and the prices are updated, hopefully in a way that brings the local copies of public variables into consistency (and therefore also optimality).
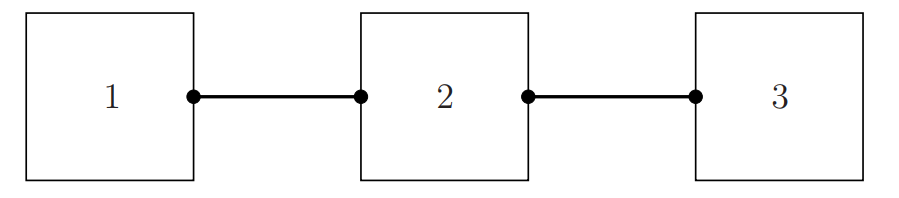
General framework for decomposition structures
There are \(K\) subproblems with private variables \(x_i\), public variables \(y_i\), public variable \(f_i\) and the local feasible set \(\mathcal{C}_i\). Let \(y\) denote the set of all public variables, i.e., \(y=(y_1, y_2,\dots,y_K)\) and \((y)_i\) be the \(i\)-th component. Suppose there are \(N\) nets, let \(z\in R^N\) be the common value on the nets. Then \(y=Ez\), where E is the matrix with
The whole problem is
Primal Decomposition
In primal decomposition, at each iteration we fix the vector z of net variables, and we fix the
public variables as $y_i = E_iz $. Each subsystem can (separately) find optimal values for its local variables \(x_i\)
To find a subgradient of \(\phi\), we find \(g_i \in \partial \phi_i(y_i)\) . We then have
The entire process is
- $y_i = E_iz, i = 1, . . . , K $
- Solve subproblems to find optimal \(x_i\), and \(g_i\in\partial \phi(y_i),\, i=1,2\dots,K\)
- \(g=\sum_{i=1}^K E^T_ig_i\)
- $z= z - \alpha_kg. $
Dual Decomposition
The partial Lagrangian is
the subproblem is
Let \(g_i(v_i)\) be the optimal value of the subproblem and the subgradient of \(-g_i\) at \(v_i\) is \(-y_i\). The dual problem is
where the last constraint comes from \(\min_z L(x,y,z,v)\).
We can solve this dual decomposition master problem using a projected subgradient method. Projection onto the feasible set \(\{v | E^T v = 0\}\), which consists of vectors whose sum over each net is zero. The projection is given by multiplication by \(\underbrace{I}_{\text{identity matrix}} - \underbrace{E(E^T E)^{-1}E^T}_{\text{average value on the graph}}\), where \(E^T E=\text{diag}\{d_1, \dots,d_N\}\), \(d_i\) is the degree of the net \(i\). \(i.e.\), the number of subsystems adjacent to net \(i\).
